


Il team di ricerca di Cohere For AI (C4AI), il laboratorio di ricerca no-profit di Cohere, ha annunciato Aya, un nuovo large language research model (LLM) all’avanguardia, open source e massivamente multilingue, che copre 101 lingue diverse – più del doppio del numero di lingue coperte dai modelli open source esistenti. Aya aiuta i ricercatori a sbloccare l’enorme potenziale degli LLM per decine di lingue e culture in gran parte ignorate dalla maggior parte dei modelli avanzati presenti oggi sul mercato, sottolinea il team.
Cohere For AI sta offrendo in open source sia il modello Aya, sia il più grande set di dati multilingue di istruzione fine-tuned fino ad oggi, con una dimensione di 513 milioni che copre 114 lingue. Questa raccolta di dati include annotazioni rare di madrelingua e parlanti fluenti in tutto il mondo, assicurando che la tecnologia AI possa servire efficacemente un ampio pubblico globale che finora ha avuto un accesso limitato.
Aya – spiega Cohere, società specializzata nell’AI per l’ambito enterprise – fa parte di un cambiamento di paradigma nel modo in cui la comunità ML si approccia alla ricerca sull’AI massively multilingual, che rappresenta non solo un progresso tecnico, ma anche un cambiamento nel come, dove e da chi viene svolta la ricerca.

Mentre i large language model, e l’AI in generale, hanno cambiato il panorama tecnologico globale, molte comunità in tutto il mondo sono rimaste senza supporto a causa delle limitazioni linguistiche dei modelli esistenti. Questa lacuna ostacola l’applicabilità e l’utilità dell’AI generativa per un pubblico globale e potrebbe ampliare ulteriormente le disparità già esistenti a causa delle precedenti ondate di sviluppo tecnologico. Concentrandosi principalmente sull’inglese e su una o due decine di altre lingue come risorse di addestramento, la maggior parte dei modelli tende a riflettere pregiudizi culturali intrinseci, mette in evidenza il team.
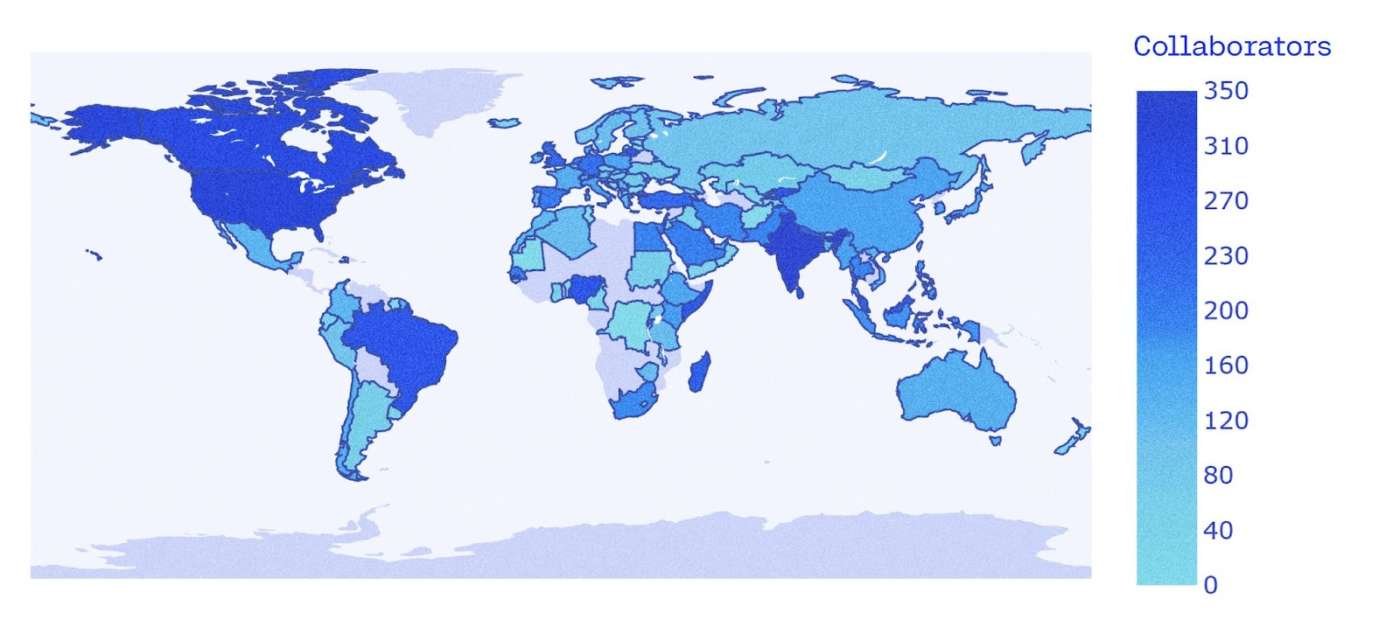
Cohere For AI ha avviato il progetto Aya per colmare questa lacuna, riunendo oltre 3.000 ricercatori indipendenti provenienti da 119 Paesi.
Il team di ricerca dietro ad Aya è riuscito a migliorare sostanzialmente le prestazioni per le lingue poco conosciute, dimostrando capacità superiori in compiti complessi, come la comprensione del linguaggio naturale, la sintesi e la traduzione, in un ampio spettro linguistico.
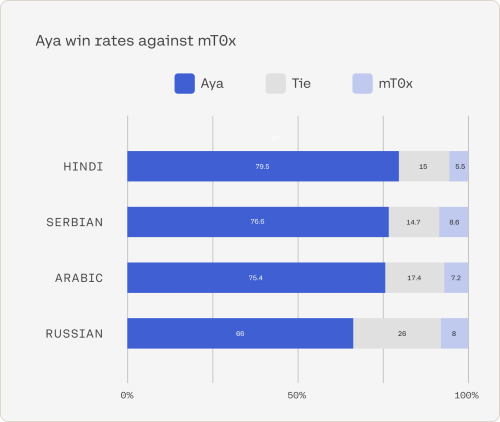
Il team ha confrontato le prestazioni del modello Aya con quelle dei modelli multilingue massivi open source disponibili. Il modello Aya supera con ampio margine i migliori modelli open source, come mT0 e Bloomz, nei test di benchmark. Aya ha ottenuto costantemente un punteggio del 75% nelle valutazioni umane contro altri modelli open source leader del settore e dell’80-90% nelle percentuali di win rate.
Aya estende inoltre la copertura a più di 50 lingue precedentemente non servite, tra cui il somalo, l’uzbeko e altre ancora. Mentre i modelli proprietari svolgono un lavoro eccellente per una serie di lingue più comunemente parlate al mondo, Aya contribuisce a fornire ai ricercatori un modello open source senza precedenti per decine di lingue sottorappresentate.
Cohere For AI sta rilasciando la collezione Aya, composta da 513 milioni di richieste e completamenti che coprono 114 lingue. Questa enorme raccolta è stata creata da persone che parlano correntemente in tutto il mondo, che hanno creato modelli per set di dati selezionati e hanno incrementato un elenco accuratamente curato di dataset. Include anche il set di dati Aya, che il team descrive come il più vasto dataset annotato dall’uomo, multilingue e con istruzioni di fine-tuning. Contiene circa 204.000 annotazioni rare curate dall’uomo in 67 lingue, garantendo una copertura linguistica solida e diversificata. Questo offre un archivio su larga scala di dati linguistici di alta qualità per sviluppatori e ricercatori.
Molte lingue presenti in questa raccolta non erano mai state rappresentate in set di dati instruction-style. Il dataset, completamente permissivo e open-sourced, include un ampio spettro di esempi linguistici, comprendendo una varietà di dialetti e contributi originali che riflettono autenticamente l’uso organico, naturale e informale della lingua. Ciò lo rende una risorsa inestimabile per la ricerca linguistica e gli sforzi di conservazione linguistica.
Cohere For AI sta rilasciando sia il modello Aya che i set di dati Aya con una licenza Apache 2.0 completamente permissiva, con l’obiettivo di ampliare l’accesso al progresso multilingue. Con questa licenza, accademici, istituzioni civili e piccole imprese possono sfruttare il modello e i dati di Aya per un impatto più ampio.
Aya sarà la base per altri progetti di scienza aperta e Cohere si aspetta di continuare a migliorarne le capacità. Per aderire a questa iniziativa di scienza aperta e assicurarsi che la propria lingua sia rappresentata, è possibile visitare il sito web del progetto Aya per iscriversi e iniziare. È inoltre possibile provare il modello Aya nel Cohere Playground o scaricare il modello e il set di dati.
Venerdì 16 febbraio l’azienda terrà un evento virtuale per condividere ulteriori informazioni sul nuovo modello Aya.









{kind=link}