


Matt Calkins, CEO di Appian, è calmo, riflessivo e riservato, ma il suo carattere non gli ha impedito di mettere in evidenza con forza, durante il keynote che ha aperto l’edizione 2024 di Appian World, caratteristiche, visione e soluzioni che differenziano l’azienda – da lui fondata 25 anni fa insieme a Michael Beckley (attuale CTO), Robert Kramer (General Manager) e Marc Wilson (Chief Partner Officer) – da altri attori del settore, anche con fatturato e dimensioni molto maggiori.
Festeggiare l’anniversario a Washington DC, nei pressi del quartier generale di Appian, è simbolico, ma consente a Calkins di sottolineare che “Appian è diventata più grande in questo periodo, ma non siamo cambiati molto. Noi quattro fondatori siamo ancora in azienda, tutti in ruoli apicali. La nostra value proposition è più o meno la stessa; le persone si aspettano da noi le stesse cose oggi come dieci anni fa. Questo è fondamentalmente il nostro lavoro: ci occupiamo di processi, soprattutto di processi critici e importanti per il business, siamo innovativi e siamo buoni partner. Non molto diverso da quello che era un anno fa, 5 anni o 10 anni fa.”

E i clienti, i partner e gli sviluppatori che fanno parte della comunità Appian, si attendono determinate cose da Appian; tra queste, si aspettano che per ogni nuova ondata di tecnologia sia all’avanguardia, al passo con le ultime funzionalità e le renda facili da utilizzare aggiungendo valore, trovando un modo non solo per abbracciare questa tecnologia, ma per portarla ai clienti e renderla produttiva nel loro ambiente.
La tecnologia più recente è naturalmente l’AI, e soprattutto l’AI generativa. Ma l’intelligenza artificiale, sostiene Calkins, “non è una tecnologia a sé stante. Prospera se accompagnata da un paio di altri elementi: i dati e i processi. Prima di tutto: i dati, e tutti voi lo sapete: sappiamo che l’AI non è nulla senza dati. L’AI è più potente con i dati e più gliene date, più diventa intelligente. Il problema è che non sono i dati generici esterni a rendere l’AI veramente potente in un’azienda. Se OpenAI trova un’altra fonte di dati e la legge nella sua ultima iterazione, in realtà non cambierà di molto il valore che si ottiene dall’AI. Ciò che cambierà è il cluster di dati interni che dovrebbero guidare le risposte dell’AI nel contesto in cui ci si trova. I dati interni sono i più preziosi per l’AI e purtroppo sono anche i più difficili da ottenere, sono quelli che si esita a condividere o su cui fare formazione”.
Il momento della mixed autonomy
“Se un sistema Self Driving ti sta guidando l’auto, è meglio non staccare troppo le mani dal volante”, provoca Calkins, spostando l’attenzione sui processi. ”L’AI commette ancora molti errori; l’AI non ha una capacità umano di giudizio; l’intelligenza artificiale può scrivere cose, ma gli esseri umani devono poterle modificare. L’intelligenza artificiale può proporre idee, ma gli esseri umani devono controllarle. L’AI non può lavorare da sola. Siamo nel momento della mixed autonomy”, di un’autonomia dell’AI che non è totale ma va condivisa con l’uomo, quanto più sono critiche le decisioni da prendere o le scelte da effettuare.
Dove si inserisce il processo? un processo è il luogo ideale per utilizzare l’AI oggi. Un processo fornisce la struttura: è una serie di compiti e di passaggi che mirano a un obiettivo di business. Qualsiasi risorsa impiegata nel processo acquista valore perché è stata indirizzata verso un obiettivo significativo. A un processo è già collegato un team, un insieme di worker – umani e digitali – e l’AI può collaborare con loro. Quindi, se si inserisce l’AI in un processo, c’è già una struttura, c’è già un obiettivo e dei collaboratori. “E c’è la possibilità di misurare i risultati; puoi vedere com’era prima dell’introduzione dell’AI, com’è dopo, confrontare e giustificare la decisione di inserire l’AI. Il processo è l’ambiente ideale per iniziare con l’AI.”, prosegue il CEO di Appian.
“Abbiamo innovato nell’IA da 10 anni, la vendiamo come parte della nostra suite di automazione, abbiamo un approccio ai dati che è stato convalidato da miliardi di interrogazioni e il traffico generato dai nostri processi è semplicemente straordinario: 16 miliardi di transazioni al giorno, soltanto su AWS, secondo le loro statistiche: migliaia di volte in più di quelle che passano attraverso Bitcoin in un giorno. Proprio la scorsa settimana abbiamo siglato un accordo di collaborazione strategica con i nostri amici di AWS. Siamo partner da quasi 14 anni con AWS, di cui siamo stati tra i primi utilizzatori.
Quindi abbiamo un vantaggio incredibile in tutte e tre queste aree.”, afferma con orgoglio Matt Calkins, sottolineando la differenza con molti competitor: “tutti possono fare IA in una certa misura, ma se non si apportano determinate competenze, se non si hanno vantaggi e tecnologie complementari, la propria offerta di IA potrebbe essere abbastanza generica, simile a quella che tutti gli altri sono in grado di fare. La nostra si distingue per il nostro vantaggio in queste due aree: la nostra struttura con i dati interni rende la nostra IA più intelligente e più preziosa per voi. Il nostro framework di processo rende l’IA facile da usare. Queste sono le cose più importanti che possiamo offrirvi, oltre all’innovazione in corso con la Gen AI.”
Data Lake vs. Data Mesh vs. Data Fabric
Data Lake: Un data lake è nettamente diverso da un data fabric. Come un data warehouse, l’obiettivo principale di un data lake è solo quello di raccogliere i dati in un unico repository. I data lake sono utilizzati per grandi insiemi di dati non strutturati, mentre i data warehouse sono utilizzati per i dati strutturati. Con un data lake, è necessario estrarre tutti i dati da ogni sistema e caricarli in un nuovo sistema (il lake). I dati rimangono nel lake fino a quando non vengono trasformati e analizzati in un secondo momento. Un data lake è perfetto per il lavoro analitico, ma non supporta i sistemi transazionali che richiedono dati in tempo reale, come le applicazioni CRM. Inoltre lo spostamento dei dati da un sistema separato al data lake comporta tempi e costi di sviluppo aggiuntivi. Ad esempio, gli sviluppatori non possono avviare una nuova applicazione finché i dati del lake non vengono ripuliti e migrati per essere utilizzati. La manutenzione e la cura dello sviluppo di questo data lake comporta nel tempo un ulteriore debito tecnico per i team di ingegneri.
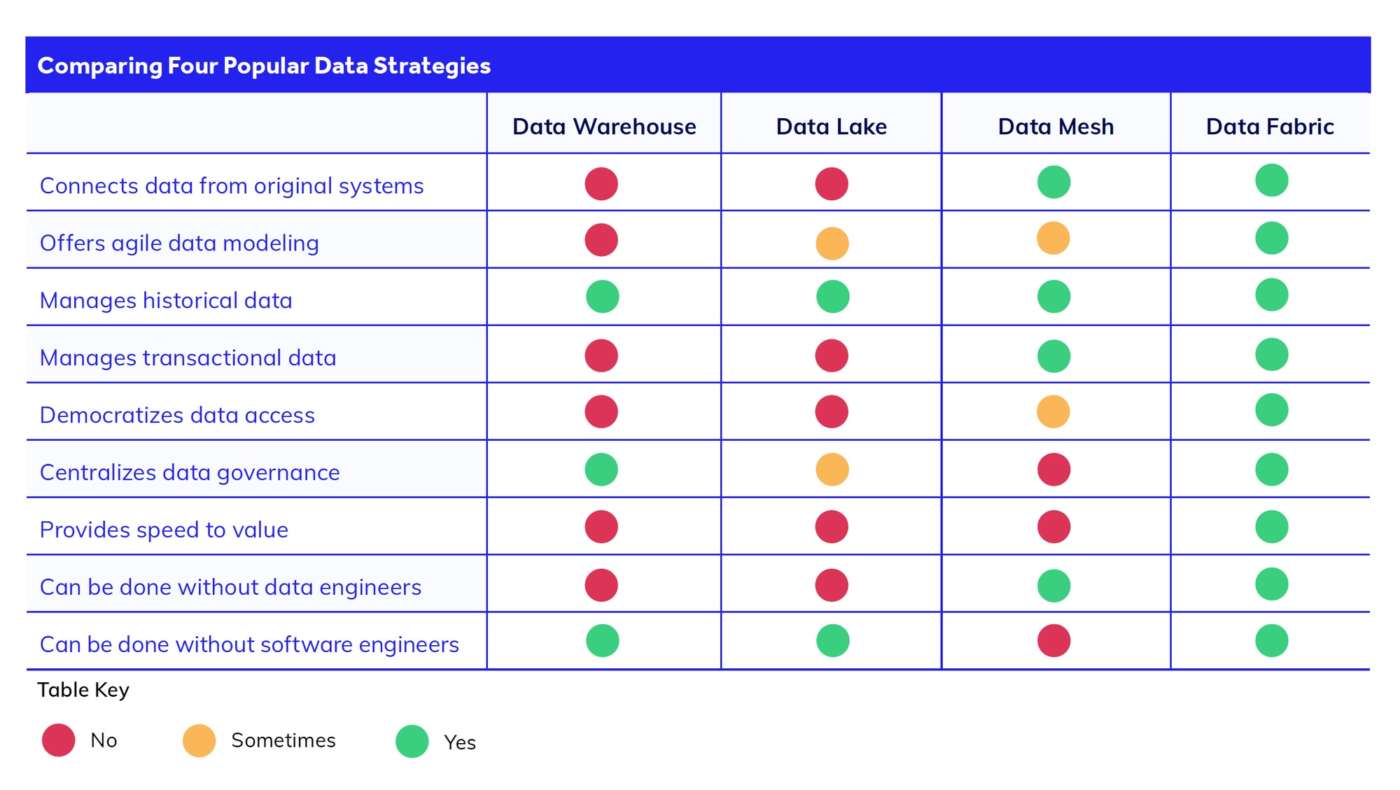
Data Mesh: Le architetture di progettazione data fabric e data mesh hanno invece un approccio diverso. Entrambe si concentrano sulla connessione diretta alle fonti di dati, anziché sull’estrazione di tutti i dati, il che consente di accedere ai dati in tempo reale e di evitare progetti di migrazione tempestivi e costosi. Data mesh e data fabric risolvono il problema della connessione dei dati in modo diverso. Il data mesh utilizza integrazioni API tra microservizi per collegare tra loro i sistemi dell’azienda. Con il data mesh, quindi, se da un lato si evita molto lavoro di ingegnerizzazione dei dati, dall’altro lo si scambia con un ulteriore impegno di sviluppo del software per la gestione delle API.
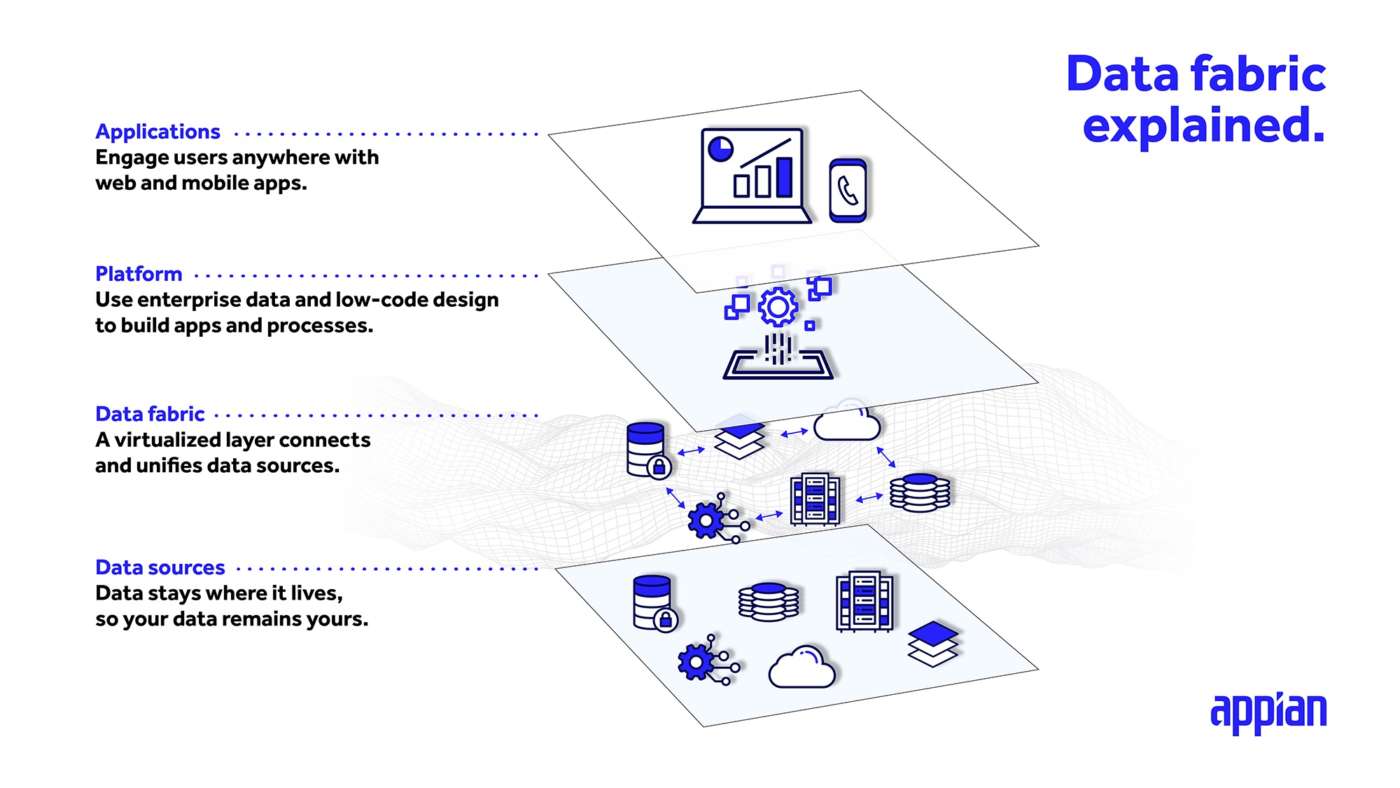
Data Fabric: Ciò che rende unico il data fabric è la sua capacità di creare un livello di dati virtualizzati in cima ai set di dati, eliminando la necessità del lavoro con le API e di codifica che un data mesh o un data lake richiedono. Ciò offre ai team una maggiore velocità e agilità nell’analisi dei dati, nella modellazione dei dati e nel lavoro di trasformazione digitale.
Con il data fabric di Appian si ottiene un livello semantico comune che può essere trattato come se fosse un dato locale, si può leggere e scrivere, è ottimizzato in background per massimizzare la velocità delle query. L’accesso ai dati è unificato, ma – questa è la differenza fondamentale – nulla viene trasferito. “È una tecnologia fatta per rispettare il modo in cui la vostra azienda è già strutturata, per supportare il modo in cui la vostra infrastruttura è già allineata. Non vi chiediamo di stravolgere le cose, non vi chiediamo di consegnare i vostri dati, ma di facilitare l’impresa che avete, così com’è ora, a raggiungere rapidamente il valore.”, promette il manager.
Per un’AI rilevante e utile, ma privata e sicura
Requisito fondamentale per un’AI rilevante e utile per il business è che possa utilizzare i dati aziendali per dare risposte pertinenti. Ma affinché rimanga privata e sicura è che i dati non siano utilizzati per addestrare i modelli né per farne il fine tuning, né che le informazioni contenute nelle richieste ai modelli siano utilizzate successivamente. La tecnica al momento in auge per soddisfare entrambi i requisiti è la RAG, Retrieval Augmented Generation.
Non si addestra l’algoritmo dell’AI; invece, ogni volta che c’è una domanda che si vuole sottoporre all’AI, si trovano rapidamente i dati che corrispondono a quella domanda, qualsiasi cosa sia pertinente, indipendentemente da dove si trovi nell’azienda, si vanno a cercare quei dati e si forniscono all’AI insieme alla domanda. Se si forniscono le due cose insieme, l’intelligenza artificiale vede la domanda e i dati pertinenti in una volta sola; si ottiene una risposta di qualità.
La RAG sta diventando popolare, ma dipende assolutamente da un buon data fabric. Se non si dispone di un buon data fabric, se non si ha la comprensione di dove si trovano i dati e la connessione per andare alla fonte e riportarli in tempo reale, non si sarà in grado di informare correttamente l’AI con ogni nuova domanda.
Quest’anno si sente molto parlare di RAG e data fabric: alcuni grandi fornitori, secondo il CEO di Appian, hanno capito di essere indietro e vogliono usare questi termini. Ma si tratta più di rumore che di realtà. L’approccio alla RAG dipende dall’avere un buon data fabric; se non si dispone di un data fabric di ampia portata e ben collegato a tutte le fonti di dati, non si riuscirà a informare accuratamente l’AI della Retrieval Augmented Generation.
“La ragione per cui investiamo nel data fabric è perché crediamo in una strategia di decentralizzazione dei dati.
Questo è il problema, perché i nostri grandi concorrenti non ci credono, credono nella centralizzazione delle informazioni all’interno del loro database, Quando parlano di Retrieval Augmented Generation, in realtà stanno dicendo: faremo un ottimo lavoro per darvi l’AI sul database che ci è già stato dato e quando parlano di data fabric parlano di come hanno un nuovo strumento che vi aiuterà a dare i dati a loro, quindi in realtà si tratta di centralizzare i dati, mentre il nostro approccio è l’opposto; si tratta di trattare l’azienda nel modo in cui è e di trarne valore nel modo in cui è, quindi la differenza è come tra il giorno e la notte: i termini utilizzati sono gli stessi, ma intendiamo cose completamente diverse”, obietta, senza fare nomi ma con forza, Calkins.
LLM + RAG + data fabric, i vantaggi
Innanzitutto, per definizione, non è necessario caricare i dati.
In secondo luogo, l’accesso tramite il data fabric permette di implementare livelli di sicurezza granulare fornendo alle funzione RAG soltanto i dati privati a cui chi fa la domanda può accedere.
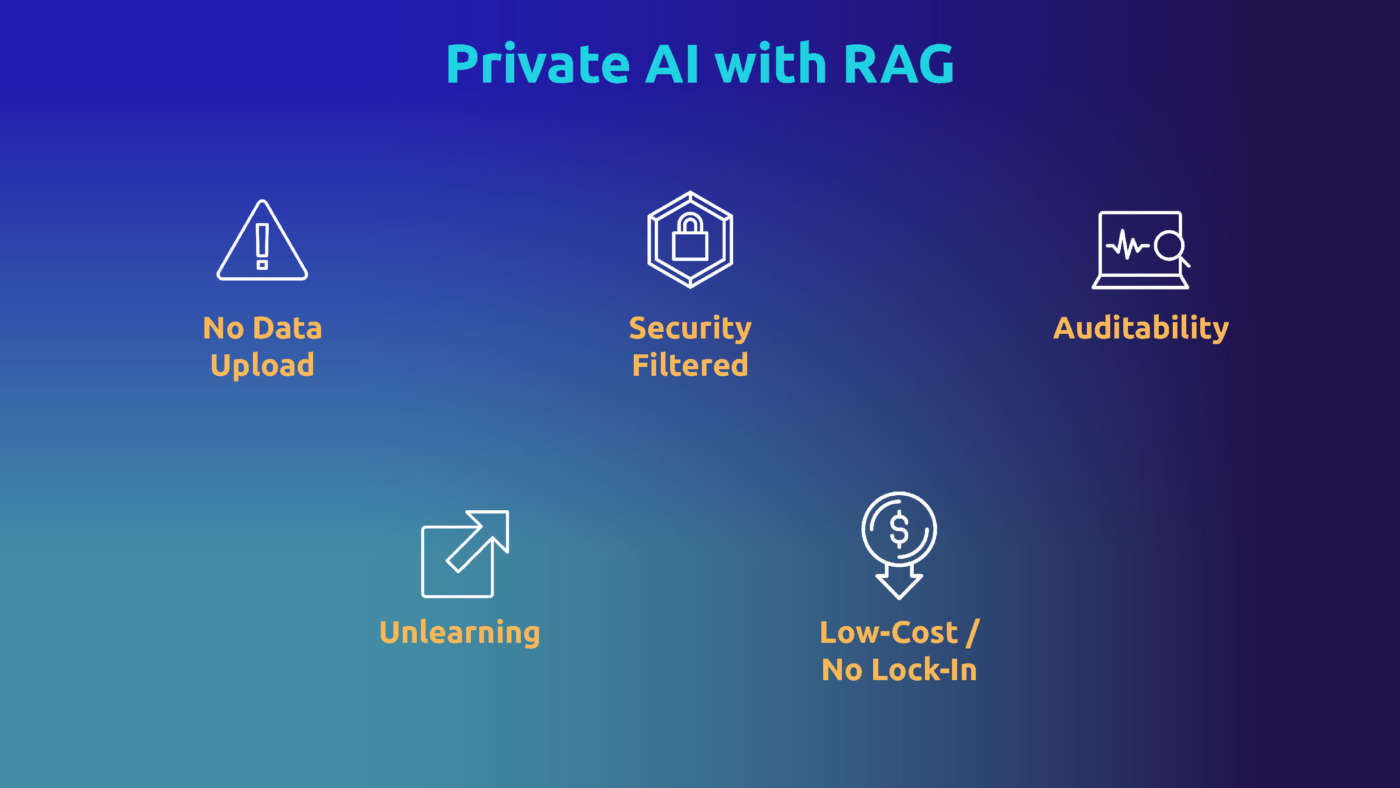
Terzo, è verificabile. L’AI generativa è soggetta ad allucinazioni e può comunque dare risposte strane. Anche se il motore di AI è una scatola nera, quando l’AI ti dà una risposta strana vuoi sapere perché, vuoi verificare cosa ha spinto l’AI a dire questo. Con il nostro approccio è possibile verificare quei dati, si può guardare esattamente il pacchetto di informazioni che è stato inviato e questo è il motivo che ti dice perché l’AI ha dato quella risposta.
Quarto, l’unlearning: questo è un grosso problema nell’AI: fondamentalmente non funziona. L’AI non dimentica le cose che non le si dicono, non rende obsoleti i propri archivi di dati, ma ciò non costituisce un problema perché non si è mai insegnato nulla all’algoritmo e si può sempre decidere quali informazioni sono pertinenti e ritirarle quando non lo sono.
Quinto e ultimo punto: non c’è alcun lock-in, perché non avendo addestrato l’AI, si può facilmente sostituire un algoritmo con un altro e ottenere risposte altrettanto valide, il che migliora la posizione negoziale con i vendor di strumenti AI.
Regolare l’utilizzo dell’AI, con un approccio prudente e responsabile
Ci sono molti regolamenti in arrivo in materia di AI, come la dichiarazione della Casa Bianca, la legge sull‘Intelligenza Artificiale europea, la dichiarazione congiunta del Regno Unito e degli Stati Uniti.
Appian ha un approccio all’AI che tutelerà i clienti, perché è già rispettoso della sicurezza, della privacy, fornisce una quantità minima di informazioni all’algoritmo dell’AI, non permette all’AI di prendere le proprie decisioni in modo sfrenato.
Semplificare adozione, avvio e valutazione dei costi
Una delle attività per cui l’AI è più utile è dare raccomandazioni in situazioni complesse. Anche se i casi d’uso possono essere molto differenti, si tratta di raccogliere dati provenienti da fonti sparse, sintetizzarli e formulare una raccomandazione. Appian ritiene di essere in grado di risolvere questo tipo di problemi, al punto di proporre una soluzione: l’AI Kickstart. “Prenderemo qualsiasi processo che avete già in esecuzione in Appian e in un mese, a un prezzo fisso, implementeremo quel tipo di AI. La implementeremo nel vostro processo e vi daremo la potenza, l’efficienza, il throughput, il miglior servizio clienti, i risparmi sui costi che otterrete a quel prezzo fisso di un mese e se avete bisogno di qualche altro tipo di AI, lo aggiungeremo.”, annuncia Matt Calkins, che ribadisce come un processo sia il modo più semplice e veloce per utilizzare l’AI. Non solo è il modo più produttivo perché ha una struttura, un obiettivo, un team e una quantificazione; è anche il modo più semplice per utilizzare l’AI oggi.
La semplificazione dell’offerta passa per un nuovo starter kit destinato ai nuovi clienti, progettato per ottenere il massimo successo nel lancio iniziale, includendo servizi, supervisione, livello di supporto, licenze, funzionalità; e per una drastica razionalizzazione dei prezzi.
Process HQ, il futuro del process mining
Matt Calkins lo annuncia con orgoglio: “Pensavamo che, avendo accesso ai dati, avremmo potuto rendere il process mining in tempo reale; e pensavamo che, avendo accesso ai processi, avremmo potuto rendere il process mining actionable ed è esattamente quello che abbiamo fatto. Dopo un lungo periodo di beta, il mese prossimo sarà disponibile Process HQ, il futuro del process mining.”

“Process HQ fa tre cose fantastiche. La prima è la navigazione dei dati. Potete navigare nella vostra azienda, aggregare, individuare, andare a qualsiasi fonte di dati, non solo alle fonti di dati Appian, ma a qualsiasi cosa sia collegata dal nostro data fabric, ricordate che abbiamo questo livello di database virtuale in tutta l’azienda. È possibile seguirlo, andare ovunque e fare un drill fino al caso, all’istante, alla riga o all’aggregazione e vedere gli schemi. Non è come la business intelligence, dove bisogna caricare un database prima di poterlo analizzare, ma si tratta di una navigazione a livello aziendale.”
Abbinato ad Appian AI Copilot, Data fabric insights consente agli utenti di ottenere nuovi insight ancora più velocemente. Abilita la creazione di report da parte di utenti aziendali senza competenze di sviluppo su Appian e permette loro di rispondere più rapidamente ai quesiti di business più comuni, senza dover ricorrere a un esperto di dati o a uno sviluppatore per creare un report. Le organizzazioni possono risparmiare tempo e denaro grazie a queste funzionalità e sono certe che solo gli utenti autorizzati possano visualizzare determinati dati protetti. Appian AI Copilot automatizza le attività di sviluppo più ripetitive generando esempi di dati e test dell’applicazione. È sufficiente fornire il contesto utilizzando il linguaggio naturale e la quantità di dati e lasciare che l’AI copilot si occupi del resto, generando dati per singoli record e per insiemi complessi di record correlati. I dati campione generati dall’intelligenza artificiale sono ideali per i test di accettazione dell’utente e le dimostrazioni agli stakeholder, e accelerano il ciclo di vita dello sviluppo di dati realistici per qualsiasi applicazione. AI Copilot utilizza anche l’intelligenza artificiale generativa per automatizzare la generazione dei casi di test, semplificando una delle attività più lunghe che gli sviluppatori devono affrontare, suggerendo casi di test allineati ai ruoli aziendali degli utenti e garantendo una copertura completa della logica aziendale. Di conseguenza, gli sviluppatori possono accelerare le attività di test, ridurre al minimo l’impegno manuale e migliorare la qualità complessiva e l’affidabilità delle loro applicazioni.
“La seconda cosa è la capacità di misurare tutto; questo è il battito cardiaco del vostro processo: qualsiasi cosa stia accadendo, qualsiasi ritardo, qualsiasi sbalzo momentaneo, ne sarete consapevoli. Avete un display che vi dice tutto ciò che sta accadendo nel vostro processo e se avete apportato delle modifiche, se avete implementato qualcosa di nuovo di cui volete vedere l’impatto lo vedrete. se c’è un problema che vi sta rallentando lo individuerete. Non avete mai avuto una visione del vostro processo così acuta, così in tempo reale, così reattiva, il livello di misurazione è ora in una dimensione diversa.
E poi ottimizzare: questo potrebbe essere addirittura la funzionalità migliore delle tre. Esaminiamo l’intero flusso del processo, proprio come farebbe il process mining, e individuiamo cosa vi blocca, dove è l’inefficienza, dove è la correlazione tra il tempo e una certa attività, quali sono le variabili correlate; quindi, vi diciamo dove sono i rallentamenti e li analizziamo in relazione al volume di quell’istanza e vi raccomandiamo alcune cose da fare per migliorare la vostra efficienza.
Questa funzione si ripagherà da sola in pochissimo tempo, è così potente che vi farà cambiare idea sul process mining; infatti, il futuro del process mining è proprio qui e io sono davvero molto orgoglioso di questa funzione.”
Processi che scalano elasticamente
“Abbiamo un cliente – non posso dire chi – che ha bisogno di elaborare 8 milioni di transazioni 401K (i piani pensionistici negli USA), in una finestra di 4 ore alla fine della settimana lavorativa e ci sono altri clienti che sanno che arriverà un picco di richieste, ma non sanno quando arriverà: questa è un’esigenza comune e quindi quello che abbiamo qui è un paradigma di scalabilità che vi porterà a 10 volte o 100 volte da dove siete oggi.”, sostiene Matt Calkins, implicitamente evidenziando quanto la piattaforma Appian sia utilizzata per casi d’uso di alto livello.
Per rispondere a queste esigenze Appian introduce Elastic Process Execution; Process On Demand, la definisce il CEO, facendo intuire che le risorse vengono dinamicamente attivate e disattivate avendo visibilità dei processi da eseguire, non soltanto dell’utilizzo complessivo di CPU, memoria e storage.
Ulteriori miglioramenti dell’IA generativa nell’ultima versione di Appian includono:
Undici nuove skill di IA grazie all’IA generativa. Appian offre ora undici nuove AI Skills che utilizzano un Large Language Model (LLM) incorporato in Appian Cloud. Le skill utilizzano un design low-code che consente agli utenti di sfruttare un LLM per un facile tuning dei prompt dell’IA per casi d’uso specifici, tra cui: riassunto di documenti, identificazione di PII (Personal Identifiable Information), estrazione di dati da documenti ed e-mail, generazione di testi e altro ancora. Presentando un elenco particolareggiato di casi d’uso comuni, le AI Skills semplificano l’incorporazione dell’AI generativa nelle applicazioni Appian, consentendo agli utenti di partire da una richiesta contestualmente rilevante e di generare in modo efficiente risposte AI affidabili.
Il Comune di Milano tra i vincitori degli Appian Innovation Awards 2024
Ogni anno gli Innovation Awards premiano i clienti che hanno realizzato soluzioni d’impatto con la piattaforma Appian implementando con successo l’automazione dei processi AI per offrire un significativo valore aggiunto. Il Comune di Milano utilizza Appian per automatizzare e digitalizzare i processi chiave, trasformare l’esperienza dei cittadini e innovare l’erogazione dei servizi per oltre 1,3 milioni di abitanti. Partendo da una sola applicazione, la gestione dei pass per parcheggi per disabili, che è stata sviluppata nel 2022 in meno di due mesi, riducendo il tempo di richiesta e consegna dei pass da tre settimane a 13 ore, Milano consente ora ai propri cittadini di avviare 23 tipi di richieste online per servizi residenziali, assistenza sociale e sanitaria, permessi edilizi e catastali, appalti, gestione dei biglietti e altro ancora. La piattaforma Appian si integra inoltre con 90 sistemi esistenti per automatizzare e semplificare le operazioni di back-office dei dipendenti comunali.






{kind=link}