


Nel campo della virtualizzazione siamo passati dalle macchine virtuali alla logica dei container. Ma se per molti utenti questo passo è ancora da digerire bene, i cloud provider di primo piano come Amazon, Google, IBM e Microsoft hanno già bene in mente il prossimo salto del serverless computing, in cui la logica applicativa si astrae sempre più dall’hardware sottostante sino a esserne indipendente.
I servizi ci sono già, il punto ora è cercare di farli capire ad aziende e sviluppatori, perché il concetto dello sviluppo “senza server” non è proprio intuitivo.
Non esiste un modello “ufficiale” del serverless computing, ma gli approcci seguiti per implementarlo hanno tutti alcuni punti comuni.
La logica di fondo è che le applicazioni (in senso lato) cloud-native e di ultima generazione sono sempre più connotate da microservizi mirati che svolgono operazioni specifiche in concomitanza con il verificarsi di determinate condizioni.
Ad esempio, un microservizio può attivarsi quando un sensore di tipo IoT gli invia dei dati, controllare la correttezza formale dei dati stessi, memorizzarli in un database cloud.
Sempre più astrazione
I container sono nati proprio per la necessità di attivare e disattivare velocemente risorse che eseguano compiti più o meno complessi, ma dal punto di vista dello sviluppo sono ancora elementi articolati che richiedono di conoscere l’hardware sottostante e di saper allocare alle applicazioni le risorse adeguate.
Il serverless computing punta a superare questo limite. Gli sviluppatori si devono preoccupare solamente di creare il codice delle funzioni che svolgono i servizi necessari e di definire gli eventi che le attivano, è la piattaforma cloud sottostante che alloca e toglie risorse hardware (computing, storage; i server “sotto” comunque ci sono) a seconda del carico di lavoro.

I vantaggi del serverless computing per chi sviluppa sono evidenti. L’unita logica di base (la funzione) è chiara, non ci si preoccupa di aspetti infrastrutturali, non c’è rischio di over/under-provisioning delle risorse IT, non ci sono macchine virtuali o container che aspettano a vuoto (ma a pagamento) il verificarsi delle condizioni che scatenano i servizi. E poi c’è l’approccio definito “bring your own code”: le funzioni si possono scrivere in qualsiasi linguaggio (JavaScript, Python, PHP e via dicendo) purché ovviamente compatibile con la piattaforma PaaS che le eseguirà.
L’altro lato della medaglia
Ovviamente anche il serverless computing non è tutto rose e fiori, soprattutto perché il passaggio da un modello di sviluppo basato sulle applicazioni a uno impostato sulle funzioni non è banale. L’elemento principale di differenza è che una funzione è “stateless”: non sa cosa c’era prima della sua esecuzione e non si cura di quello che ci sarà dopo.
Se abbiamo la necessità di conservare lo stato delle entità logiche gestite da una funzione o da una sequenza di funzioni dovremo farlo attraverso servizi esterni (un database o una cache) oppure eseguendo in parallelo una “state machine”.
Altro elemento critico: il serveless computing non impone più i costi di mantenere attivi inutilmente container o macchine virtuali, ma questo non non vuol dire che i cloud provider abbiano iniziato a regalare capacità di calcolo.
Tutti i principali pongono un limite – di solito cinque minuti – al tempo per cui una funzione può essere attiva. Le operazioni che non si completano in quel lasso di tempo potrebbero andare perdute e chi sviluppa deve tenere conto di questo rischio.
Infine, il passaggio dalla classica applicazione alla collezione di funzioni (o nanoservizi, come vengono anche chiamate) introduce una certa complessità dal punto di vista dell’analisi del flusso delle operazioni e del debugging. Qui c’è poco da fare dal punto di vista concettuale: sono gli strumenti a disposizione degli sviluppatori che devono migliorare.
Cosa fanno i cloud provider
Tutti i principali fornitori di servizi PaaS hanno approcciato il serverless computing. Amazon ha lanciato in questo senso AWS Lambda, Microsoft ha le Azure Functions, Google le Google Cloud Functions e IBM propone OpenWhisk, che ha la peculiarità di essere anche un progetto open source.
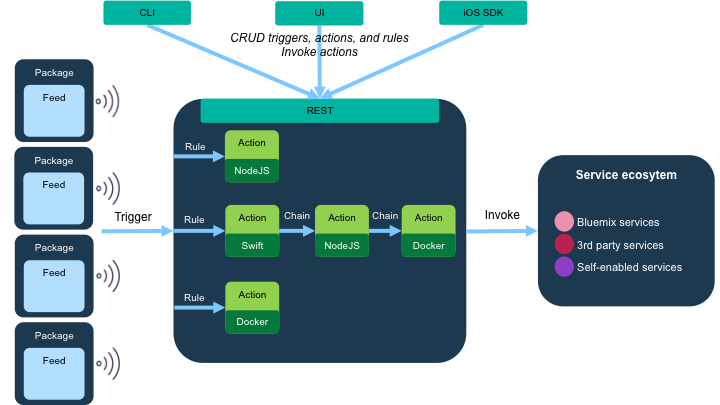
Di recente Mark Russinovich, CTO di Microsoft Azure, ha messo in evidenza quello che probabilmente la maggior parte dei provider pensa, ossia che il mercato PaaS sia quello in cui si avrà in futuro la maggiore crescita rispetto al settore IaaS, molto più cristallizzato.
In questo senso il serverless computing viene considerato come il futuro del PaaS e in generale dell’elaborazione in cloud (e non solo, visto che alcune piattaforme a nanoservizi si possono anche implementare in locale).
C’è certamente spazio per crescere. Al momento le applicazioni del serverless computing sono soprattutto per la parte di integrazione, come elemento di collegamento tra applicazioni classiche e tra sistemi on-premise e cloud.
Solo le startup che non hanno uno “storico” da conservare hanno realizzato sistemi a nanoservizi come piattaforme complessive di backend. Molto ci si aspetta dalle applicazioni Internet of Things, dove il modello delle funzioni scatenate da eventi specifici si applica perfettamente.









{kind=link}