


Groq, società specializzata in soluzioni di intelligenza artificiale generativa, è risultato il chiaro vincitore dell’ultimo benchmark sui modelli linguistici di grandi dimensioni (LLM) di ArtificialAnalysis.ai, battendo otto partecipanti in indicatori di prestazioni chiave, tra cui la latenza rispetto al throughput, il throughput nel tempo, il tempo di risposta totale e la varianza del throughput.
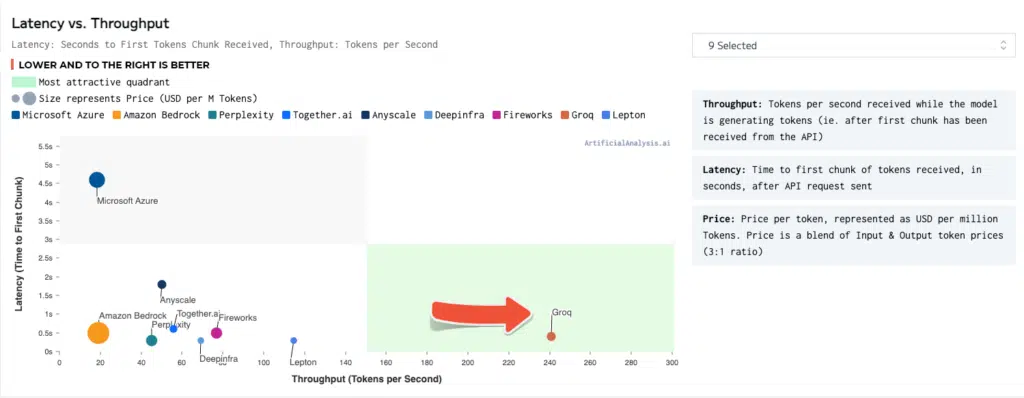
Il motore di inferenza Groq LPU si è comportato così bene – sottolinea l’azienda – con il principale LLM open source di Meta AI, Llama 2-70b, che è stato necessario estendere gli assi per tracciare Groq sul grafico Latency vs. Throughput. Groq ha partecipato al suo primo benchmark pubblico di LLM nel gennaio 2024 con risultati sorprendenti.
“ArtificialAnalysis.ai ha effettuato un benchmark indipendente dell’API Llama 2 Chat (70B) di Groq che ha raggiunto un throughput di 241 token al secondo, più del doppio della velocità di altri hosting provider“, ha dichiarato il co-creatore di ArtificialAnalysis.ai Micah Hill-Smith. “Groq rappresenta un cambio di passo nella velocità disponibile, consentendo nuovi casi d’uso per i modelli linguistici di grandi dimensioni“.
 La startup fondata nel 2016 da Jonathan Ross, ex ingegnere di Google che ha contribuito alla progettazione di quello che è poi diventato il chip Tensor Processing Unit (TPU) di Google, Groq sta sviluppando un processore di intelligenza artificiale progettato specificamente per accelerare l’elaborazione delle reti neurali profonde a una velocità senza precedenti.
La startup fondata nel 2016 da Jonathan Ross, ex ingegnere di Google che ha contribuito alla progettazione di quello che è poi diventato il chip Tensor Processing Unit (TPU) di Google, Groq sta sviluppando un processore di intelligenza artificiale progettato specificamente per accelerare l’elaborazione delle reti neurali profonde a una velocità senza precedenti.
La mission che Groq si è data è quella di stabilire lo standard di velocità di inferenza dell’AI generativa, per abilitare le applicazioni AI in tempo reale. Per raggiungere questo obiettivo, ha sviluppato un motore di inferenza LPU (LPU Inference Engine), dove LPU sta per Language Processing Unit, un nuovo tipo di sistema di unità di elaborazione end-to-end che fornisce l’inferenza più veloce per le applicazioni ad alta intensità di calcolo con una componente sequenziale, come le applicazioni linguistiche AI (LLM).
Secondo Groq, l’LPU è progettato per superare i due colli di bottiglia degli LLM: la densità di calcolo e la larghezza di banda della memoria. Una LPU ha una capacità di calcolo superiore a quella di una GPU e di una CPU per quanto riguarda gli LLM. Ciò riduce il tempo di calcolo di ogni parola, consentendo di generare sequenze di testo molto più velocemente. Inoltre, l’eliminazione dei colli di bottiglia della memoria esterna consente al motore di inferenza LPU di fornire prestazioni di ordini di grandezza superiori su LLM rispetto alle GPU.
Groq ha eseguito diversi benchmark interni, sottolinea l’azienda, raggiungendo costantemente i 300 token al secondo, stabilendo un nuovo standard di velocità per le soluzioni AI che non è ancora stato raggiunto da quelle tradizionali e dai fornitori storici. I benchmark di ArtificialAnalysis.ai sembrano ora confermare la superiorità di Groq rispetto agli altri fornitori, in particolare per quanto riguarda il throughput, pari a 241 token al secondo, e il tempo totale per ricevere 100 token in output, pari a 0,8 secondi, secondo le tecniche di benchmark delle dimensioni del prompt di input e delle dimensioni del prompt di output. Per ulteriori dettagli sui benchmark, visitate il sito https://groq.link/aabenchmark.
 “Groq esiste per eliminare le differenze tra chi ha e chi non ha e per aiutare tutti i membri della community dell’IA a prosperare“, ha dichiarato Jonathan Ross, CEO di Groq. “L’inferenza è fondamentale per raggiungere questo obiettivo, perché è la velocità a trasformare le idee degli sviluppatori in soluzioni aziendali e applicazioni che cambiano la vita. È incredibilmente gratificante che una terza parte abbia convalidato che il motore di inferenza LPU è l’opzione più veloce per l’esecuzione di modelli linguistici di grandi dimensioni e siamo grati alle persone di ArtificialAnalysis.ai per aver riconosciuto Groq come un vero concorrente tra gli acceleratori di IA“.
“Groq esiste per eliminare le differenze tra chi ha e chi non ha e per aiutare tutti i membri della community dell’IA a prosperare“, ha dichiarato Jonathan Ross, CEO di Groq. “L’inferenza è fondamentale per raggiungere questo obiettivo, perché è la velocità a trasformare le idee degli sviluppatori in soluzioni aziendali e applicazioni che cambiano la vita. È incredibilmente gratificante che una terza parte abbia convalidato che il motore di inferenza LPU è l’opzione più veloce per l’esecuzione di modelli linguistici di grandi dimensioni e siamo grati alle persone di ArtificialAnalysis.ai per aver riconosciuto Groq come un vero concorrente tra gli acceleratori di IA“.
I benchmark di ArtificialAnalysis.ai sono condotti in modo indipendente e sono “live”, cioè vengono aggiornati ogni tre ore (otto volte al giorno). I prompt sono unici, lunghi circa 100 token e generano circa 200 token in uscita. I benchmark sono progettati per riflettere l’uso reale e misurano le variazioni del throughput (token al secondo) e della latenza (tempo al primo token) nel tempo. I benchmark sono presenti su ArtificialAnalyis.ai anche con prompt più lunghi per riflettere i casi d’uso della retrieval augmented generation (RAG).
Il motore di inferenza LPU è disponibile attraverso l’API di Groq, per l’esecuzione di applicazioni LLM in un modello di tariffazione basato su token.
Groq supporta framework standard di apprendimento automatico (ML) come PyTorch, TensorFlow e ONNX per l’inferenza. Invece, non supporta attualmente il training ML con il motore di inferenza LPU.
Per lo sviluppo personalizzato, la suite GroqWare, che include Groq Compiler, offre un’esperienza immediata per rendere i modelli rapidamente operativi. Per l’ottimizzazione dei carichi di lavoro, l’azienda offre la possibilità di trasferire il codice all’architettura Groq e il controllo a grana fine di qualsiasi processore GroqChip, consentendo ai clienti di sviluppare applicazioni custom e massimizzare le prestazioni.









{kind=link}