


Uno dei principi di Apple nello sviluppo di Apple Intelligence è che l’azienda non utilizza i dati personali degli utenti o le loro interazioni per addestrare i suoi modelli foundation e, per i contenuti disponibili pubblicamente su Internet, applica filtri per rimuovere le informazioni di identificazione personale come i numeri di previdenza sociale e di carta di credito.
In un post sul suo sito Machine Learning Research Apple ha condiviso i modi in cui l’azienda sta sviluppando nuove tecniche che consentono al team di scoprire le tendenze d’uso e gli insight aggregati per migliorare le funzioni potenziate da Apple Intelligence senza rivelare il comportamento individuale o i contenuti unici.
Un’area in cui il team ha applicato il suo lavoro sulla privacy differenziale con Apple Intelligence è quella delle Genmoji. Per gli utenti che decidono di condividere i dati analitici del dispositivo con Apple, il team utilizza metodi di privacy differenziata per identificare i prompt più popolari e i pattern dei prompt, fornendo al contempo una garanzia matematica che non vengano scoperti prompt unici o rari e che non sia possibile collegare prompt specifici a singoli utenti.
Conoscere i prompt più diffusi è importante – spiega il team – perché aiuta Apple a valutare le modifiche e i miglioramenti da apportare ai suoi modelli in base ai tipi di prompt più rappresentativi del coinvolgimento reale degli utenti.
Questo approccio funziona interrogando in modo casuale i dispositivi partecipanti per sapere se hanno visto un particolare frammento e i dispositivi rispondono in modo anonimo con un segnale “rumoroso”. Per “rumoroso” si intende che i dispositivi possono fornire il vero segnale di aver visto un frammento o un segnale selezionato a caso per un frammento alternativo o nessuna corrispondenza. Calibrando la frequenza con cui i dispositivi inviano risposte selezionate a caso, il team si assicura che siano necessarie centinaia di persone che utilizzano lo stesso termine prima che la parola possa essere scoperta. Di conseguenza, Apple vede solo i prompt comunemente usati, non può vedere il segnale associato a un particolare dispositivo e non recupera alcun prompt unico. Inoltre, il segnale che Apple riceve dal dispositivo non è associato a un indirizzo IP o a un ID che potrebbe essere collegato a un account Apple. Ciò impedisce ad Apple di associare il segnale a un particolare dispositivo.
Attualmente Apple utilizza la privacy differenziale per migliorare le Genmoji e nelle prossime versioni utilizzerà questo approccio, con le stesse protezioni della privacy, anche per Image Playground, Image Wand, Memories Creation e Writing Tools in Apple Intelligence, oltre che in Visual Intelligence.
Per le funzioni di Apple Intelligence come il riassunto o gli strumenti di scrittura che operano su frasi più lunghe o su interi messaggi di posta elettronica, i metodi che Apple utilizza per capire le tendenze di messaggi brevi come le Genmoji non sono efficaci, quindi il team ha bisogno di un nuovo metodo per capire le tendenze rispettando gli standard di privacy dell’azienda, il che significa non raccogliere i contenuti dei singoli utenti. Per affrontare questa sfida, il team può ampliare la ricerca recente per creare dati sintetici utili che siano rappresentativi delle tendenze aggregate nei dati reali degli utenti, senza raccogliere e-mail o testi reali dai dispositivi.
I dati sintetici – spiega Apple – sono creati per imitare il formato e le proprietà importanti dei dati degli utenti, ma non contengono alcun contenuto reale generato dall’utente. Quando il team crea dati sintetici, il suo obiettivo è quello di produrre frasi o e-mail sintetiche che siano sufficientemente simili per argomento o stile a quelle reali per contribuire a migliorare i modelli per la sintesi dei contenuti, ma senza che Apple raccolga e-mail dal dispositivo. Un modo per creare un messaggio di posta elettronica sintetico è utilizzare un modello linguistico di grandi dimensioni (LLM).
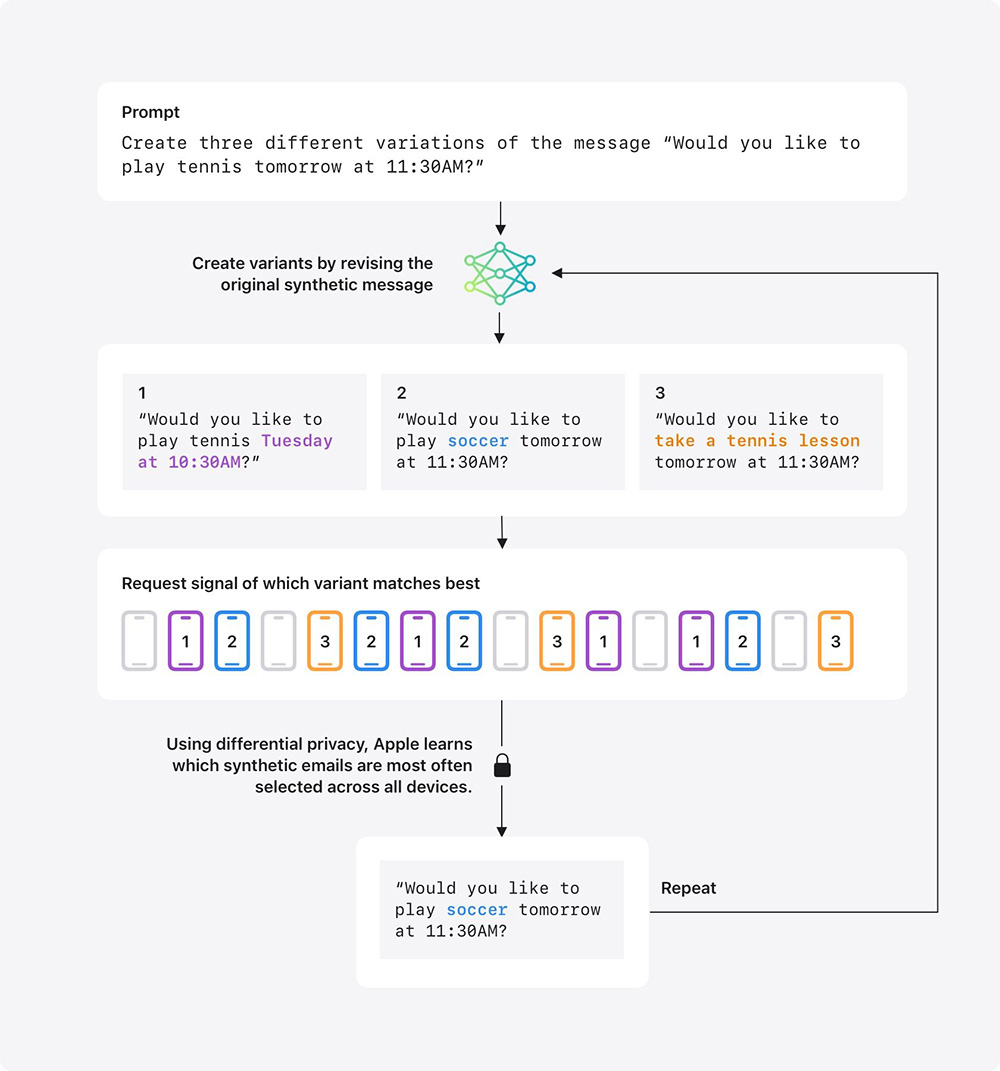 La creazione di una singola email sintetica su un argomento specifico è solo il primo passo. Per migliorare i suoi modelli, Apple deve generare un insieme di molte e-mail che coprano gli argomenti più comuni nei messaggi. Per raccogliere un insieme rappresentativo di email sintetiche, inizia a creare un’ampia serie di messaggi sintetici su una varietà di argomenti. Ad esempio, potrebbe creare un messaggio sintetico: “Ti piacerebbe giocare a tennis domani alle 11:30?“. Questo viene fatto senza conoscere le email dei singoli utenti. Quindi si ricava una rappresentazione, chiamata embedding, di ogni messaggio sintetico che cattura alcune delle dimensioni chiave del messaggio, come la lingua, l’argomento e la lunghezza. Questi embedding vengono poi inviati a un piccolo numero di dispositivi dell’utente che hanno fatto l’opt-in per i Device Analytics.
La creazione di una singola email sintetica su un argomento specifico è solo il primo passo. Per migliorare i suoi modelli, Apple deve generare un insieme di molte e-mail che coprano gli argomenti più comuni nei messaggi. Per raccogliere un insieme rappresentativo di email sintetiche, inizia a creare un’ampia serie di messaggi sintetici su una varietà di argomenti. Ad esempio, potrebbe creare un messaggio sintetico: “Ti piacerebbe giocare a tennis domani alle 11:30?“. Questo viene fatto senza conoscere le email dei singoli utenti. Quindi si ricava una rappresentazione, chiamata embedding, di ogni messaggio sintetico che cattura alcune delle dimensioni chiave del messaggio, come la lingua, l’argomento e la lunghezza. Questi embedding vengono poi inviati a un piccolo numero di dispositivi dell’utente che hanno fatto l’opt-in per i Device Analytics.
I dispositivi partecipanti selezionano quindi un piccolo campione di e-mail recenti dell’utente e ne calcolano gli embedding. Ciascun dispositivo decide poi quale degli embedding sintetici si avvicina di più a questi campioni. Utilizzando la privacy differenziale, Apple può quindi apprendere gli embedding sintetici selezionati con maggiore frequenza su tutti i dispositivi, senza sapere quale embedding sintetico è stato selezionato su un determinato dispositivo. Questi embedding sintetici selezionati più di frequente possono essere utilizzati per generare dati di addestramento o di test, oppure si possono eseguire ulteriori passaggi per affinare ulteriormente il set di dati.
Ad esempio, se il messaggio che parla di giocare a tennis è uno degli embedding migliori, si può generare un messaggio simile che sostituisce “tennis” con “calcio” o con un altro sport e aggiungerlo all’insieme per la successiva fase di curatela. Questo processo permette al team di Apple di migliorare gli argomenti e il linguaggio delle sue e-mail sintetiche, il che aiuta ad addestrare i modelli a creare output testuali migliori in funzioni come i riassunti delle e-mail, proteggendo al contempo la privacy.
Le protezioni fondamentali della privacy che Apple applica quando crea dati sintetici per migliorare la generazione del testo sono molto simili a quelle utilizzate per le Genmoji. Partecipano solo gli utenti che hanno scelto di inviare le informazioni di Device Analytics ad Apple. Il contenuto delle e-mail campionate non lascia mai il dispositivo e non viene mai condiviso con Apple. Un dispositivo partecipante invierà solo un segnale che indica quale variante si avvicina di più ai dati campionati sul dispositivo, e Apple apprende quali sono le e-mail sintetiche selezionate più spesso tra tutti i dispositivi, non quale embedding è stato selezionato da un singolo dispositivo.
Gli stessi sistemi utilizzati in Genmoji vengono utilizzati per determinare la quantità appropriata di rumore e per condividere con Apple solo le statistiche aggregate. Grazie a queste protezioni, Apple può costruire dati sintetici che riflettono tendenze aggregate, senza mai raccogliere o leggere il contenuto delle e-mail degli utenti. Questi dati sintetici possono essere utilizzati per testare la qualità dei modelli su dati più rappresentativi e per identificare aree di miglioramento per funzioni come la sintesi.
Apple utilizza i dati sintetici per migliorare la generazione di testo nelle e-mail nelle versioni beta del software. Presto inizierà a usare i dati sintetici con gli utenti che hanno optato per Device Analytics per migliorare i riassunti delle e-mail.
In definitiva, Apple afferma che, grazie alla pluriennale esperienza dell’azienda nell’utilizzo di tecniche come la privacy differenziale e di nuove tecniche come la generazione di dati sintetici, è in grado di migliorare le funzionalità di Apple Intelligence proteggendo al contempo la privacy degli utenti che aderiscono al programma di analisi dei dispositivi. Queste tecniche consentono ad Apple di comprendere le tendenze generali, senza conoscere informazioni su ogni singolo individuo, come ad esempio i prompt utilizzati o il contenuto delle loro e-mail. Apple intende continuare a far progredire lo stato dell’arte dell’apprendimento automatico e dell’intelligenza artificiale per migliorare le esperienze dei prodotti, continuando al tempo stesso a impegnarsi a sviluppare e implementare tecniche all’avanguardia per proteggere la privacy degli utenti.
L’articolo originale completo è consultabile sul sito Machine Learning Research di Apple.









{kind=link}