


Con Amazon Redshift, il data warehouse su cloud di Aws, è possibile usare l’SQL per interrogare e combinare exabyte di dati strutturati e semi-strutturati nel proprio warehouse, nei database operativi e nel data lake.
Ora che Aqua (Advanced Query Accelerator) è generalmente disponibile, ha inoltre messo in evidenza Amazon Aws, è possibile migliorare le prestazioni delle query fino a 10 volte senza costi aggiuntivi e senza modifiche al codice.
Ma cosa succede se si desidera elaborare questi dati per addestrare modelli di machine learning e utilizzare questi modelli per generare insight dai dati del warehouse della propria azienda? Ad esempio, per implementare casi d’uso come il revenue forecasting, la previsione del customer churn e il rilevamento di anomalie?
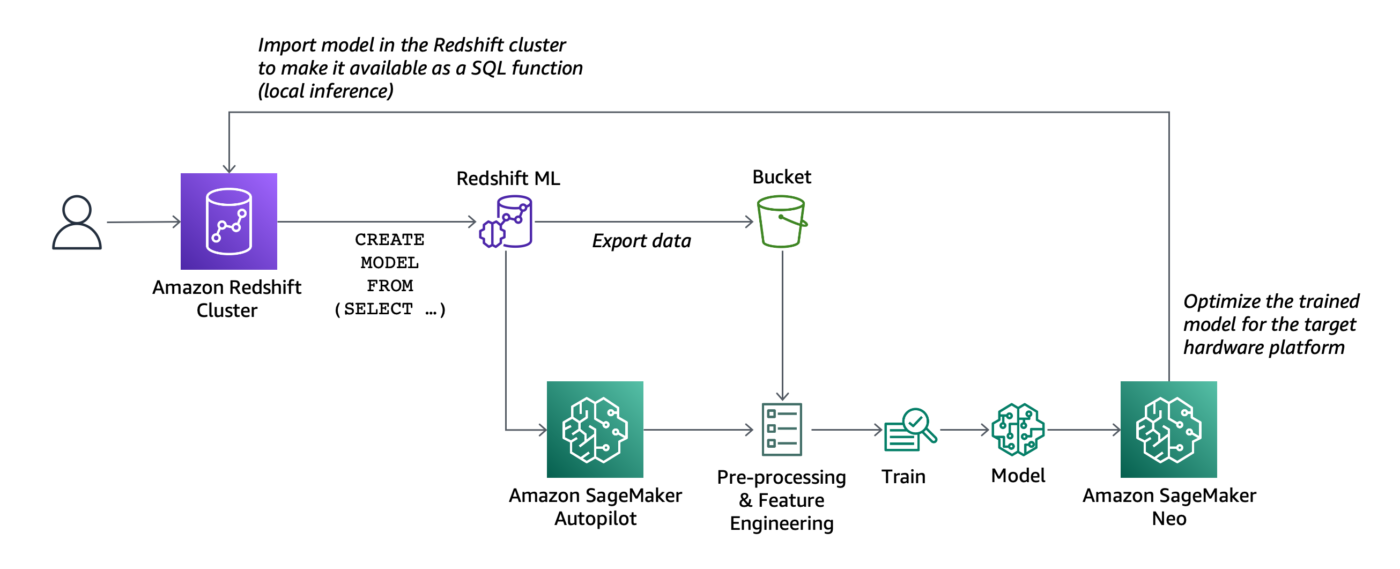
In passato, ha sottolineato Aws, era necessario esportare i dati di training da Amazon Redshift a un bucket Amazon Simple Storage Service (Amazon S3) e poi configurare e avviare un processo di machine learning (ad esempio, utilizzando Amazon SageMaker). Questo processo, però, richiedeva molte competenze diverse e di solito più di una persona per completarlo. Ed è per questo che Amazon Aws si è messa al lavoro per renderlo più facile.
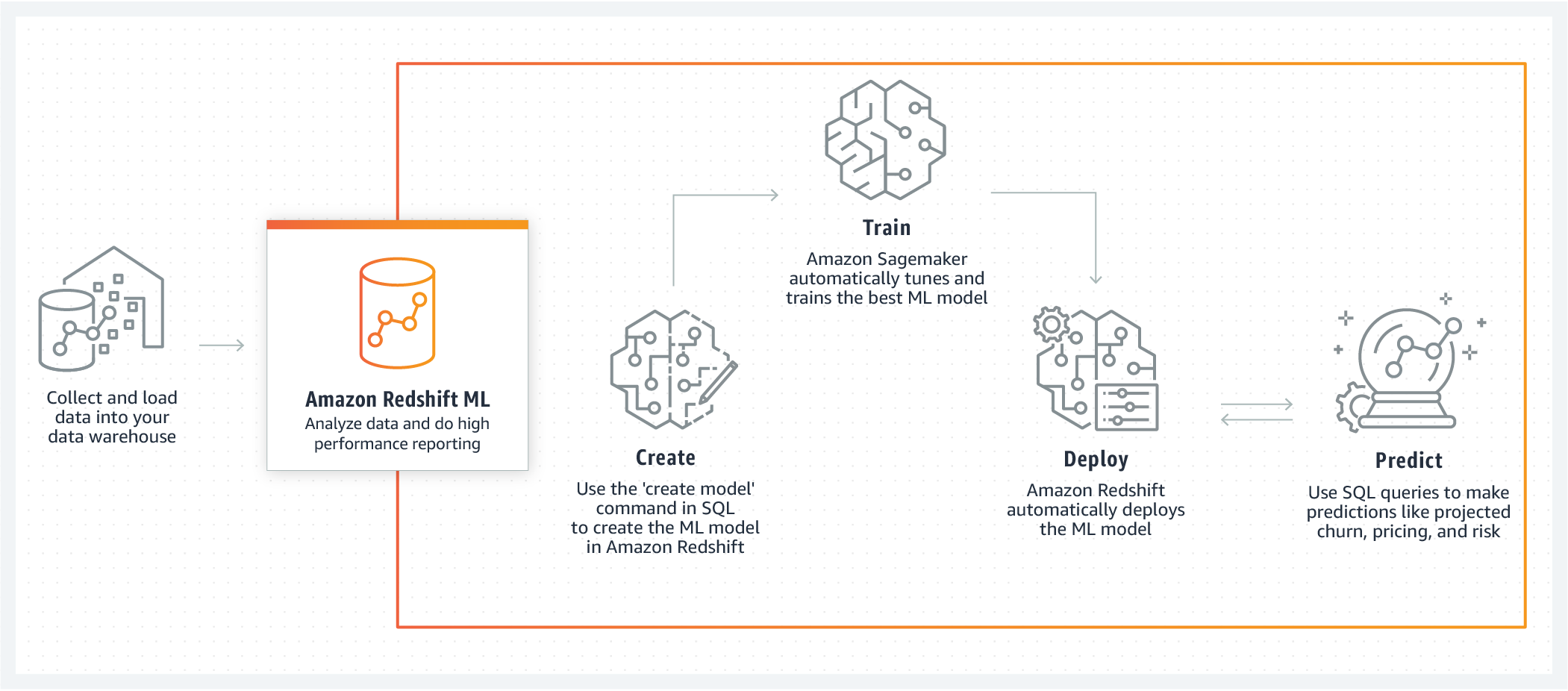
Ora, Amazon Redshift ML è generalmente disponibile per aiutare le aziende a creare, addestrare e distribuire modelli di machine learning direttamente dal proprio cluster Amazon Redshift.
Per creare un modello di machine learning, ha spiegato Amazon Aws, si utilizza una semplice query SQL per specificare i dati che si desidera utilizzare per il training, e il valore di uscita che si desidera prevedere.
Aws fa l’esempio della creazione di un modello che prevede il tasso di successo delle attività di marketing: l’azienda definisce gli input, selezionando le colonne (in una o più tabelle) che includono i profili dei clienti e i risultati delle precedenti campagne di marketing, e la colonna di output di cui si desidera ottenere una previsione. In questo esempio, la colonna di output potrebbe essere quella che indica se un cliente ha mostrato interesse in una campagna.
Dopo aver eseguito il comando SQL per creare il modello, Redshift ML esporta in modo sicuro i dati specificati da Amazon Redshift al bucket S3 e chiama Amazon SageMaker Autopilot per preparare i dati (pre-processing e feature engineering), selezionare l’algoritmo appropriato pre-costruito e applicare l’algoritmo per il training del modello.
È possibile, opzionalmente, specificare l’algoritmo da utilizzare, per esempio XGBoost.
Redshift ML gestisce tutte le interazioni tra Amazon Redshift, S3 e SageMaker, compresi tutti i passaggi coinvolti nel training e nella compilazione. Quando è stato addestrato, Redshift ML utilizza Amazon SageMaker Neo per ottimizzare il modello per il deployment e lo rende disponibile come funzione SQL. È possibile utilizzare la funzione SQL per applicare il modello di machine learning ai dati in query, report e dashboard.
Oltre alla disponibilità generale, Redshift ML ora include anche nuove funzionalità che non erano disponibili durante l’anteprima, tra cui il supporto di Amazon Virtual Private Cloud (VPC).









{kind=link}