


La visione di Fabio Pascali, Regional Vice President Italy di Cloudera, sui limiti dell’AI Generativa all’interno delle organizzazioni e sulle possibili soluzioni per sfruttarne appieno le potenzialità.
Cavalcando l’onda della rivoluzione dell’AI generativa, i servizi di terze parti di modelli linguistici di grandi dimensioni (LLM – Large Language Model) come ChatGPT e Bard sono rapidamente diventati argomenti centrali dell’opinione pubblica, convertendo gli scettici e trasformando il modo in cui interagiamo con la tecnologia.
Simbolo di questo trend è stato l’istantaneo successo di ChatGPT, che, tra i vari risultati, ha stabilito il record per la più rapida crescita del numero di utenti, raggiungendo i 100 milioni in soli 2 mesi dal lancio. Gli LLM hanno il potenziale per trasformare quasi tutti i settori e siamo solo agli inizi della nuova era dell’intelligenza artificiale generativa.
I vantaggi delle nuove soluzioni AI sono molteplici, ma non rappresentano un’opzione adatta a tutte le realtà presenti sul mercato: pensiamo ad esempio alle imprese che vogliono adottare l’intelligenza artificiale generativa per casi d’uso specifici per la propria organizzazione, che dovranno quindi essere alimentati da dati proprietari. Inoltre, per quanto i servizi di AI generativa possano migliorare le attività aziendali, essi non sono privi di rischi e svantaggi.
Le sfide per le aziende che adottano l’AI generativa
Data Privacy
La privacy dei dati è una preoccupazione cruciale per ogni impresa, in quanto sia i singoli che le organizzazioni sono alle prese con le sfide di sicurezza dei dati personali, dei clienti e dell’azienda, all’interno di un contesto in rapida evoluzione grazie a tecnologie digitali e innovazioni alimentate da tali dati.
Le applicazioni di intelligenza artificiale generativa SaaS, come ChatGPT, sono un esempio perfetto dei progressi tecnologici che espongono individui e organizzazioni a rischi per la privacy e tengono in allerta i team IT. Le applicazioni di terze parti possono memorizzare ed elaborare informazioni aziendali sensibili, che, in caso di violazione dei dati o di accesso non autorizzato, potrebbero essere esposte.
Limiti contestuali degli LLM
Una delle sfide significative affrontate dai modelli LLM è la loro mancanza di comprensione contestuale delle questioni aziendali specifiche. Gli LLM come GPT-4 e BERT sono addestrati su vaste quantità di testi pubblici e disponibili su Internet che comprendono un’ampia gamma di argomenti e domini. Tuttavia, questi modelli non hanno accesso alle conoscenze aziendali o a fonti di dati proprietarie. Di conseguenza, quando vengono interrogati con domande specifiche sull’impresa, gli LLM possono presentare due tipologie di risposte: falsa o concreta ma fuori contesto.
Con “allucinazioni” si intende la tendenza degli LLM a ricorrere alla generazione di informazioni fittizie che sembrano realistiche. La difficoltà nel discernere le risposte false degli LLM è data dal fatto che si tratta di un efficace mix di fatti e finzione. Un esempio recente è rappresentato dai falsi casi giudiziari suggeriti da ChatGPT e successivamente utilizzati da un avvocato in una causa reale. Applicato al contesto aziendale, se un dipendente chiede informazioni sulle politiche aziendali in materia di viaggi e trasferimenti, un LLM generico produrrà una serie di indicazioni di buon senso che però non corrispondono a quelle pubblicate dall’azienda.
Le risposte fattuali ma fuori contesto si verificano quando un LLM non ha una risposta esatta e specifica a una domanda relativa ad un contesto preciso e, quindi, fornirà una risposta sì vera ma non adattata al contesto.
Come le imprese possono affrontare queste sfide?
Le aziende che ospitano gli LLM garantiscono la Data Privacy
Un’opzione per garantire la privacy dei dati è l’utilizzo da parte delle aziende di LLM sviluppati e ospitati nelle applicazioni. Sebbene l’addestramento di un LLM da zero possa sembrare un’opzione valida, il costo è proibitivo. Sam Altman, CEO di OpenAI, stima che il costo per addestrare GPT-4 sia superiore a 100 milioni di dollari.
La buona notizia è che la comunità open source arriva in aiuto a questa problematica. Ogni giorno vengono rilasciati su HuggingFace nuovi LLM sviluppati da vari team di ricerca e organizzazioni, costruiti su tecniche e architetture all’avanguardia, sfruttando l’esperienza collettiva della più ampia comunità di AI. HuggingFace semplifica l’accesso a questi modelli open source pre-addestrati, in modo che le aziende possano iniziare il proprio percorso di implementazione degli LLM da un punto di partenza più vantaggioso. Inoltre, continuano ad essere rese disponibili nuove e potenti alternative open (MPT-7B da MosaicML, Vicuna).
I modelli open source consentono alle aziende di ospitare le proprie soluzioni di AI all’interno della propria infrastruttura senza costi eccessivi in ricerca, infrastruttura e sviluppo. Ciò significa che le interazioni con questo modello sono mantenute all’interno dell’organizzazione, eliminando i problemi di privacy associati alle soluzioni LLM SaaS come ChatGPT e Bard.
Aggiungere un contesto aziendale agli LLM
La limitazione contestuale non è un’esclusiva delle aziende. I servizi LLM SaaS come OpenAI hanno offerte a pagamento per integrare i dati dell’utente nei loro servizi, ma questo ha implicazioni molto evidenti sulla privacy. Anche la comunità AI ha riconosciuto le lacune e ha già fornito una serie di soluzioni, per cui è possibile aggiungere un contesto agli LLM ospitati dalle imprese senza esporre i propri dati.
Sfruttando tecnologie open source come Ray o LangChain, gli sviluppatori possono perfezionare i modelli linguistici con dati specifici dell’azienda, migliorando così la qualità delle risposte attraverso lo sviluppo di una comprensione precisa del compito e la fedeltà ai toni desiderati. In questo modo il modello è in grado di comprendere le richieste dei clienti, fornire risposte più concrete e gestire abilmente le sfumature del linguaggio specifico dei clienti. La messa a punto è efficace per aggiungere un contesto aziendale agli LLM.
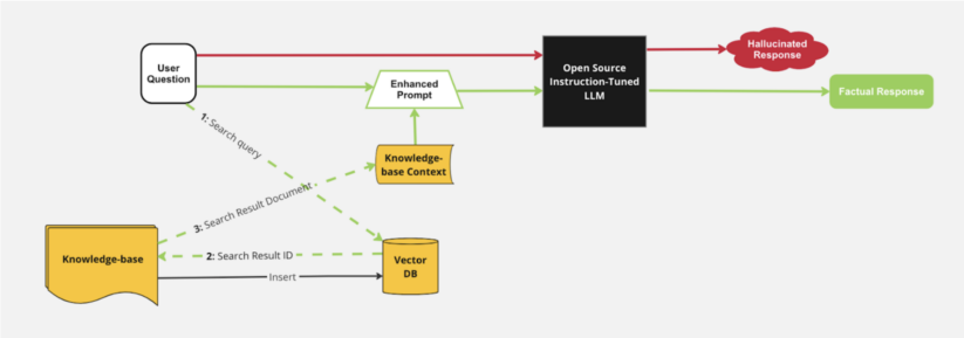
Un’altra potente soluzione alle limitazioni contestuali è l’uso di architetture come la Retrieval-Augmented Generation (RAG). Questo approccio combina le capacità generative con la possibilità di recuperare le informazioni da una base di conoscenza utilizzando database vettoriali come Milvus. Integrando un database di conoscenze, gli LLM possono accedere a informazioni specifiche durante il processo di generazione. Questa integrazione consente al modello di generare risposte non solo basate sulla lingua, ma anche fondate sul contesto della base di conoscenze.
Grazie all’open source, le aziende sono in grado di creare e ospitare LLM esperti in materia, che vengono sintonizzati per eccellere in casi d’uso specifici piuttosto che generalizzati per essere abbastanza bravi in tutto.
Come abilitare l’AI generativa per l’impresa
Sfruttando i servizi di machine learning, come Cloudera Machine Learning (CML), le imprese possono costruire la propria applicazione di AI alimentata da un LLM open source di loro scelta, sulla base dei propri dati, all’interno dell’infrastruttura aziendale, abilitando il contributo anche da parte di sviluppatori e linee di business – non solo da data scientist e team di ML – e democratizzando realmente l’AI. Cloudera ha recentemente rilasciato un nuovo Applied ML Prototype (AMP) per accelerare la sperimentazione di AI e LLM. LLM Chatbot Augmented with Enterprise Data è il primo di una serie di AMP che dimostreranno come utilizzare librerie e tecnologie open source per abilitare l’AI generativa a livello enterprise.









{kind=link}