


Il team di ricerca sul machine learning di Apple ha di recente condiviso sul proprio blog che, oltre agli sforzi in corso per accelerare l’inferenza sul silicio Apple, ha recentemente compiuto progressi significativi nell’accelerazione dell’inferenza LLM per le GPU NVIDIA, ampiamente utilizzate per le applicazioni di produzione in tutto il settore dell’AI.
L’accelerazione dell’inferenza LLM – sottolineano i ricercatori Apple – è un problema importante della ricerca ML, poiché la generazione auto-regressiva di token è computazionalmente costosa e relativamente lenta e il miglioramento dell’efficienza dell’inferenza può ridurre la latenza per gli utenti.
I ricercatori Apple hanno pubblicato e reso open source Recurrent Drafter (ReDrafter), un nuovo approccio alla decodifica speculativa che raggiunge prestazioni allo stato dell’arte. ReDrafter utilizza un modello draft basato su RNN e combina il beam search con la dynamic tree attention per accelerare la generazione di token degli LLM fino a 3,5 token per step di generazione nei modelli open source, superando le prestazioni delle precedenti tecniche di speculative decoding.
Questo lavoro di ricerca secondo il team Apple ha dimostrato risultati solidi, ma il suo impatto maggiore deriva dall’applicazione in produzione per accelerare l’inferenza degli LLM. Per rendere questo progresso pronto per la produzione su NVIDIA GPU, Apple ha collaborato con NVIDIA per integrare ReDrafter nel framework di accelerazione dell’inferenza NVIDIA TensorRT-LLM.
Sebbene TensorRT-LLM supporti numerosi LLM open source e il metodo di speculative decoding Medusa, gli algoritmi di beam search e tree attention di ReDrafter si basano su operatori mai utilizzati in precedenti applicazioni. Per consentire l’integrazione di ReDrafter, NVIDIA ha aggiunto nuovi operatori o reso disponibili quelli esistenti, migliorando significativamente la capacità di TensorRT-LLM di supportare modelli e metodi di decoding avanzati. Gli sviluppatori di ML che utilizzano NVIDIA GPU possono ora beneficiare facilmente della generazione di token accelerata di ReDrafter per le loro applicazioni LLM in produzione con TensorRT-LLM.
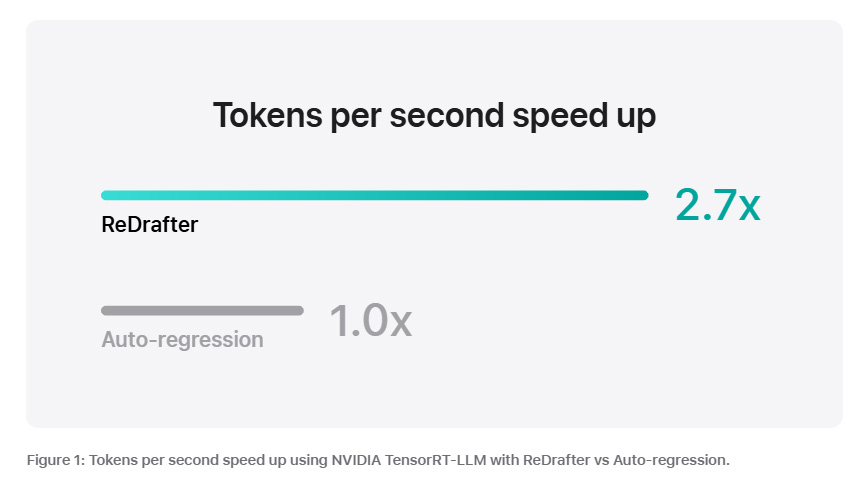
Nel benchmarking di un modello di produzione con decine di miliardi di parametri su NVIDIA GPU, utilizzando il framework di accelerazione dell’inferenza NVIDIA TensorRT-LLM con ReDrafter, il team ha osservato un aumento di 2,7 volte nella velocità di generazione di token per secondo per il greedy decoding. Questi risultati secondo i ricercatori indicano che questa tecnologia potrebbe ridurre significativamente la latenza percepita dagli utenti, utilizzando al contempo un numero inferiore di GPU e consumando meno energia.
Gli LLM sono sempre più utilizzati per alimentare le applicazioni di produzione e il miglioramento dell’efficienza dell’inferenza può sia incidere sui costi di calcolo sia ridurre la latenza per gli utenti. Grazie al nuovo approccio di ReDrafter allo speculative decoding integrato nel framework NVIDIA TensorRT-LLM, gli sviluppatori possono ora beneficiare di una generazione di token più rapida sulle GPU NVIDIA per le loro applicazioni LLM di produzione.
Ulteriori informazioni sono disponibili nel blog Machine Learning Research di Apple e nel blog di NVIDIA.









{kind=link}