


Stability AI, società specializzata nello sviluppo di soluzioni di AI generativa, nota soprattutto per la famiglia di modelli Stable Diffusion, ha presentato Stable Cascade, al momento in fase di research preview.
Questo modello da testo a immagine, che l’azienda non esita a definire innovativo, introduce un interessante approccio a tre stadi, stabilendo nuovi parametri di riferimento per la qualità, la flessibilità, la messa a punto e l’efficienza, con particolare attenzione all’ulteriore eliminazione delle barriere hardware, sottolinea il team.
Inoltre, l’azienda ha rilasciato il codice per l’addestramento e l’inferenza, disponibile sulla pagina GitHub di Stability, per consentire un’ulteriore personalizzazione del modello e dei suoi risultati. Il modello è disponibile per l’inferenza nella diffusers library.
Questo modello si basa sull’architettura Würstchen e la sua principale differenza rispetto ad altri modelli, come Stable Diffusion, è che lavora su uno spazio latente molto più piccolo. Cià è importante – sottolinea il team – perché, più piccolo è lo spazio latente, più veloce è l’inferenza e meno costoso è l’addestramento.
 Spiega Stability AI: Stable Diffusion utilizza un fattore di compressione di 8, per cui un’immagine di 1024×1024 viene codificata a 128×128. Stable Cascade raggiunge un fattore di compressione di 42, il che significa che è possibile codificare un’immagine di 1024×1024 in 24×24, mantenendo ricostruzioni nitide. Il modello text-conditional viene quindi addestrato nello spazio latente altamente compresso. Le versioni precedenti di questa architettura hanno ottenuto una riduzione dei costi di 16 volte rispetto a Stable Diffusion 1.5, afferma l’azienda.
Spiega Stability AI: Stable Diffusion utilizza un fattore di compressione di 8, per cui un’immagine di 1024×1024 viene codificata a 128×128. Stable Cascade raggiunge un fattore di compressione di 42, il che significa che è possibile codificare un’immagine di 1024×1024 in 24×24, mantenendo ricostruzioni nitide. Il modello text-conditional viene quindi addestrato nello spazio latente altamente compresso. Le versioni precedenti di questa architettura hanno ottenuto una riduzione dei costi di 16 volte rispetto a Stable Diffusion 1.5, afferma l’azienda.
Pertanto, questo tipo di modello è adatto per gli usi in cui l’efficienza è importante. Inoltre, con questo metodo sono possibili tutte le estensioni note come finetuning, LoRA, ControlNet, IP-Adapter, LCM ecc.
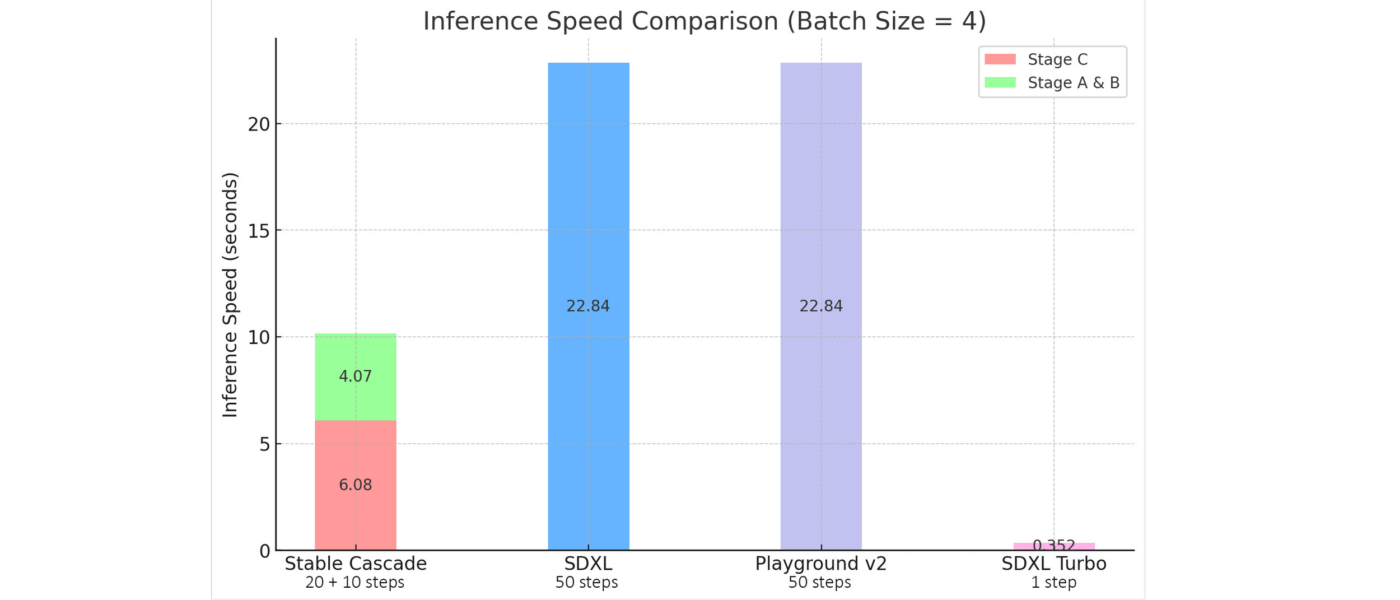
Inoltre, secondo Stability AI Stable Cascade ottiene risultati impressionanti, sia dal punto di vista visivo che da quello della valutazione. Secondo la valutazione del team, Stable Cascade ottiene le migliori prestazioni sia nell’allineamento dei prompt che nella qualità estetica in quasi tutti i confronti.
Stable Cascade si differenzia dalla linea di modelli Stable Diffusion in quanto è costruito su una pipeline che comprende tre modelli distinti: questa architettura consente una compressione gerarchica delle immagini, ottenendo risultati notevoli pur utilizzando uno spazio latente altamente compresso.
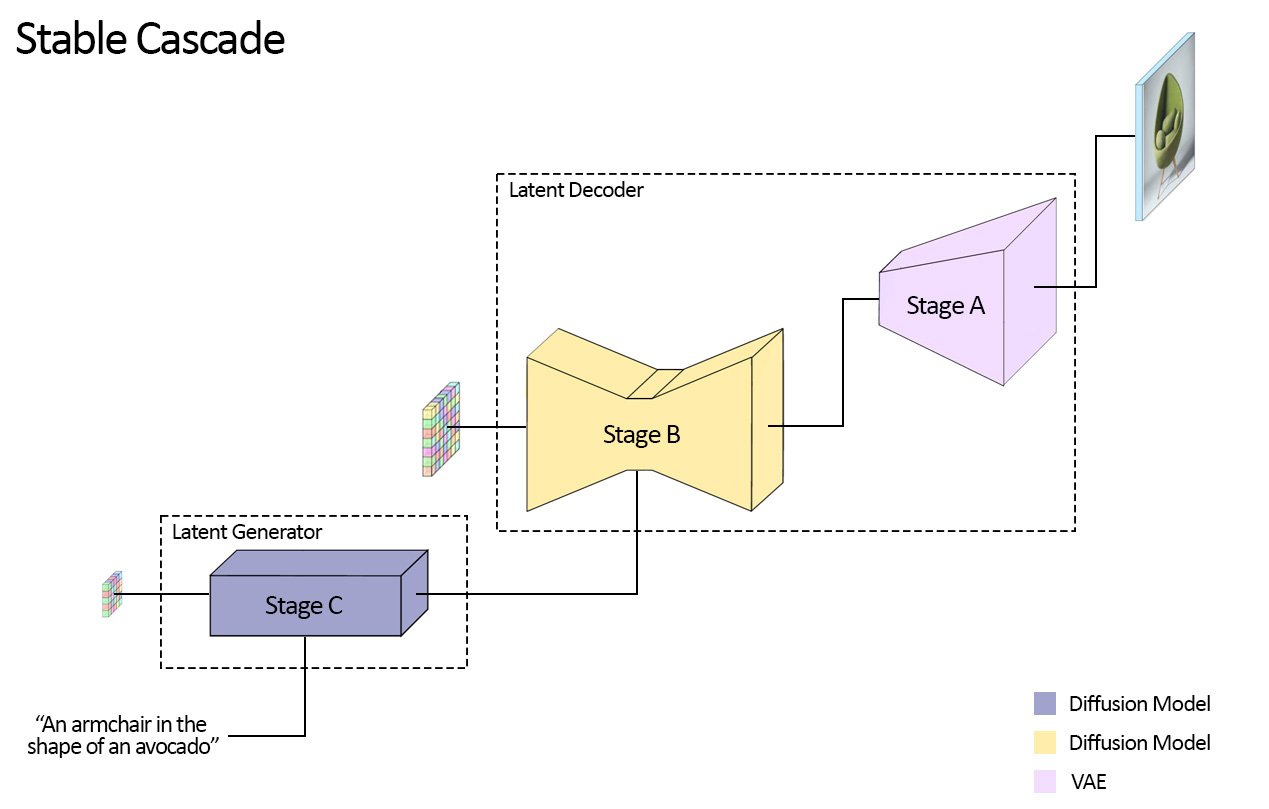 La fase Latent Generator, Stage C, trasforma gli input dell’utente in latenti compatti 24×24 che vengono passai alla fase Latent Decoder (Stage A e B), utilizzata per comprimere le immagini, in modo simile al compito del VAE in Stable Diffusion, ma ottenendo una compressione molto più elevata.
La fase Latent Generator, Stage C, trasforma gli input dell’utente in latenti compatti 24×24 che vengono passai alla fase Latent Decoder (Stage A e B), utilizzata per comprimere le immagini, in modo simile al compito del VAE in Stable Diffusion, ma ottenendo una compressione molto più elevata.
Disaccoppiando la generazione text-conditional (Fase C) dalla decodifica nello spazio dei pixel ad alta risoluzione (Fasi A e B), è possibile consentire l’addestramento aggiuntivo o la messa a punto, compresi ControlNet e LoRA, da completare singolarmente nello Stage C. Ciò comporta una riduzione dei costi di 16 volte rispetto all’addestramento di un modello Stable Diffusion di dimensioni simili. Gli Stage A e B possono essere messi a punto per ottenere un controllo aggiuntivo, ma ciò sarebbe paragonabile al finetuning del VAE in un modello Stable Diffusion. Per la maggior parte degli utilizzi, sottolinea il team, i benefici aggiuntivi saranno minimi e Stability AI suggerisce di addestrare semplicemente lo Stage C e di utilizzare gli Stage A e B nel loro stato originale.
Gli Stage C e B saranno rilasciati con due modelli diversi: 1B e 3,6B per lo Stage C e 700M e 1,5B per il B. Il team consiglia di utilizzare il modello 3,6B per lo Stage C, poiché questo modello offre la massima qualità di uscita. Tuttavia, la versione con parametri 1B può essere utilizzata per coloro che desiderano focalizzarsi sui requisiti hardware più bassi. Per lo Stage B, entrambi ottengono ottimi risultati, afferma il team, tuttavia il modello da 1,5 miliardi eccelle nella ricostruzione dei dettagli fini. Grazie all’approccio modulare di Stable Cascade, i requisiti di VRAM previsti per l’inferenza possono essere mantenuti a circa 20 GB, ma possono essere ulteriormente ridotti utilizzando le varianti più piccole (ma questo può anche diminuire la qualità finale dell’output).
Oltre alla generazione standard da testo a immagine, Stable Cascade può generare variazioni di immagini e generazioni da immagine a immagine.
Nel blog di Stability AI sono disponibili ulteriori dettagli tecnici così come confronti e caratteristiche complete.









{kind=link}