


Il team della società israeliana Run:AI ha sviluppato un layer di virtualizzazione (primo al mondo nel suo genere, sostiene l’azienda) per il training di modelli di deep learning.
Astraendo i carichi di lavoro dall’infrastruttura sottostante, Run:AI crea un pool condiviso di risorse che possono essere fornite in modo dinamico, abilitando il pieno utilizzo di costosi sistemi di computing basati su Gpu.
Perché l’infrastruttura di intelligenza artificiale dovrebbe essere virtualizzata? Run:AI ha le idee chiare in merito. I workload di intelligenza artificiale vengono spesso eseguiti su bare metal e assegnati staticamente ai data scientist. Tuttavia, l’allocazione statica delle risorse porta a limitazioni su: dimensioni e velocità dell’esperimento, basso utilizzo di Gpu e mancanza di controlli It.
Oggi le aziende sono abituate alla semplicità e disponibilità delle risorse dei data center virtualizzati, ma si accorgono che i vantaggi dell’infrastruttura virtualizzata non sono necessariamente disponibili nello stack di intelligenza artificiale.
In ogni fase del processo di deep learning, i data scientist hanno esigenze specifiche riguardo alle risorse di calcolo: le fasi di build richiedono Cpu o Gpu in sessioni interattive; il training richiede un’elevata intensità di calcolo e una notevole potenza della Gpu. Tuttavia, l’attività di training è irregolare: a volte sono in esecuzione carichi di lavoro simultanei, altre volte non è in esecuzione alcun workload poiché i data scientist stanno ottimizzando i modelli. Lo stadio Inference, infine, richiede in genere un utilizzo inferiore della Gpu.
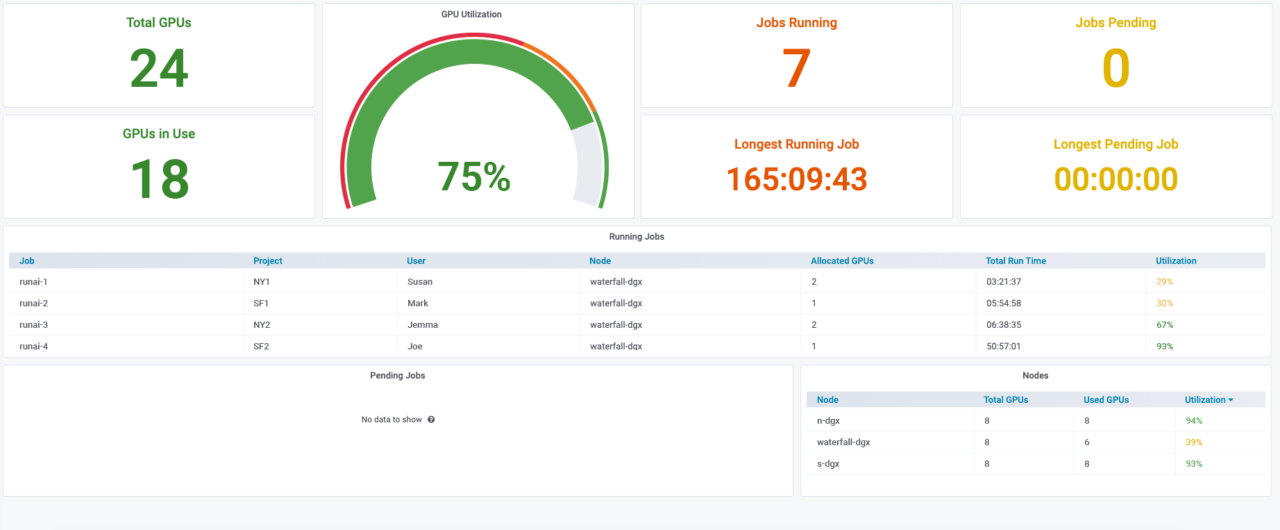
Le allocazioni dinamiche delle risorse, che tengono conto del processo di deep learning, afferma Run:AI, sono dunque fondamentali per lo sviluppo dell’intelligenza artificiale. La soluzione Kubernetes Run:AI è stata ideata per semplificare i workflow e offrire agilità e portabilità ai data scientist.

Run:AI ha di recente rilasciato il primo sistema di condivisione Gpu frazionata per i carichi di lavoro di deep learning su Kubernetes. Indicato dall’azienda come particolarmente adatto per compiti di intelligenza artificiale leggeri su larga scala, quali l’inferenza, il fractional Gpu system offre in modo trasparente ai team di data science e d’ingegneria dell’intelligenza artificiale la capacità di eseguire più carichi di lavoro contemporaneamente su una singola Gpu.
Ciò consente alle aziende di eseguire più workload, quali computer vision, riconoscimento vocale ed elaborazione del linguaggio naturale, sullo stesso hardware, riducendo i costi.
L’attuale standard di fatto per i workload di deep learning, sottolinea Run:AI, è di eseguirli in container orchestrati da Kubernetes. Tuttavia, aggiunge l’azienda, Kubernetes è in grado di allocare solo intere Gpu fisiche ai container, e non possiede le capacità di isolamento e virtualizzazione necessarie per consentire la condivisione delle risorse Gpu senza memory overflow o conflitti di elaborazione.
Il fractional Gpu system di Run:AI crea in modo efficace Gpu logiche virtualizzate, con la propria memoria e spazio di elaborazione, che i container possono utilizzare e a cui possono accedere come se fossero processori autonomi. Ciò consente di eseguire diversi carichi di lavoro di deep learning in container affiancati sulla stessa Gpu, senza che interferiscano tra loro. La soluzione, sostiene Run:AI, è trasparente, semplice e portatile, e non richiede modifiche ai container stessi.









{kind=link}