


OpenAI, sottolinea lo specialista dell’intelligenza artificiale, lavora con molte aziende – tra cui Klarna, Morgan Stanley, Oscar, Salesforce e Wix – per aiutarle a sviluppare soluzioni di AI da zero e a implementare in modo sicuro l’AI nelle loro organizzazioni e nei loro prodotti.
Per questo, il team di OpenAI sta approfondendo il supporto alle imprese con nuove funzionalità utili sia per le grandi aziende che per gli sviluppatori che scalano rapidamente sulla piattaforma dei creatori di ChatGPT.
Per quel che riguarda la sicurezza, la società di AI ha introdotto Private Link, un nuovo modo in cui i clienti possono garantire la comunicazione diretta tra Azure e OpenAI riducendo al minimo l’esposizione a Internet.
Il team ha anche rilasciato la Multi-Factor Authentication (MFA) nativa per garantire la conformità ai crescenti requisiti di controllo degli accessi. Si tratta di nuove aggiunte al pacchetto esistente di funzionalità di sicurezza enterprise, tra cui la certificazione SOC 2 Type II, il single sign-on (SSO), la crittografia dei dati a riposo con AES-256 e in transito con TLS 1.2 e i controlli di accesso role-based. La piattaforma offre anche Business Associate Agreements per le aziende sanitarie che richiedono la conformità HIPAA e una politica di zero data retention per i clienti API con un caso d’uso qualificante.
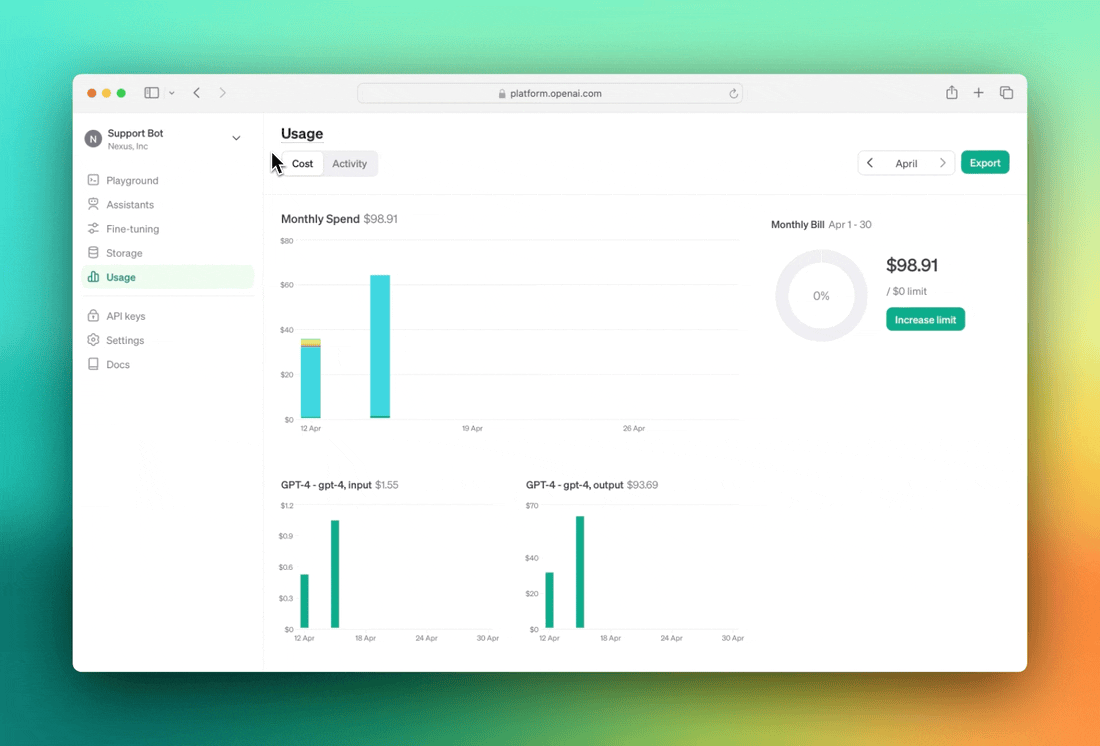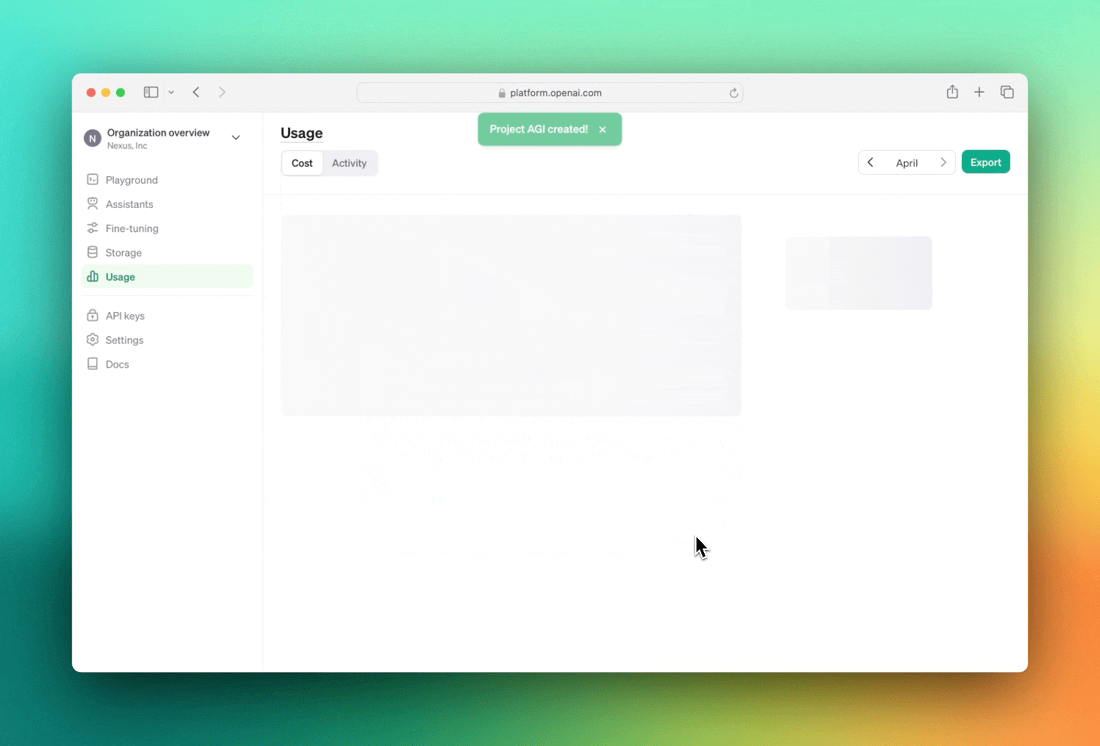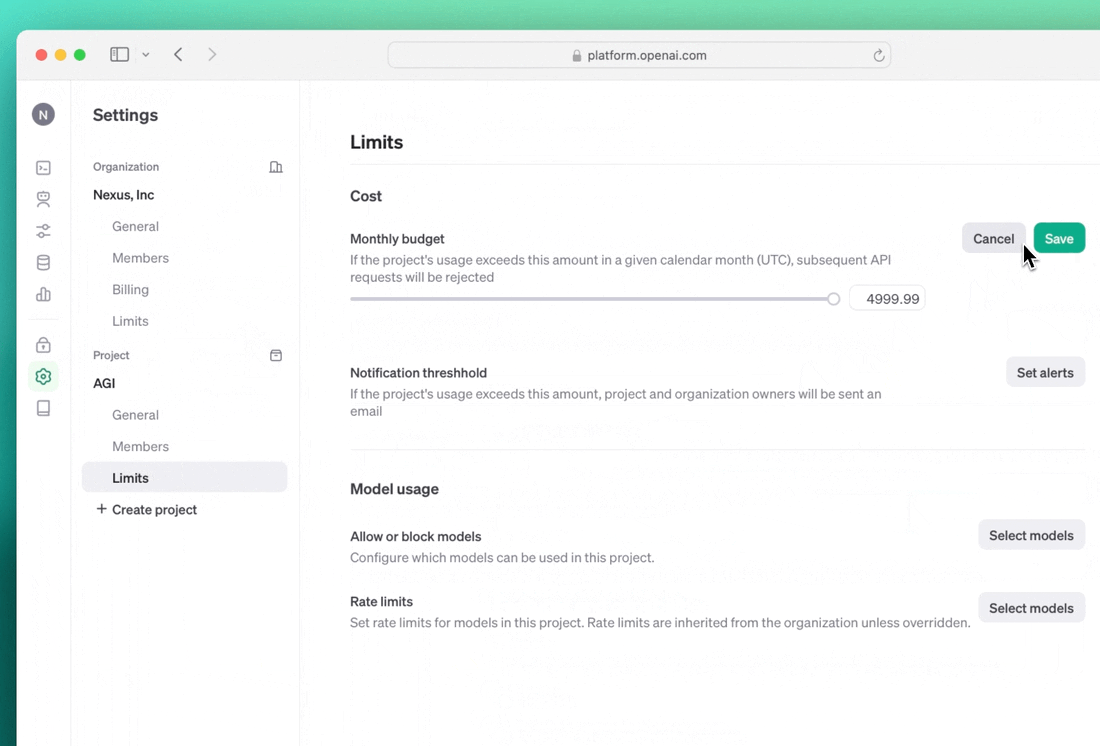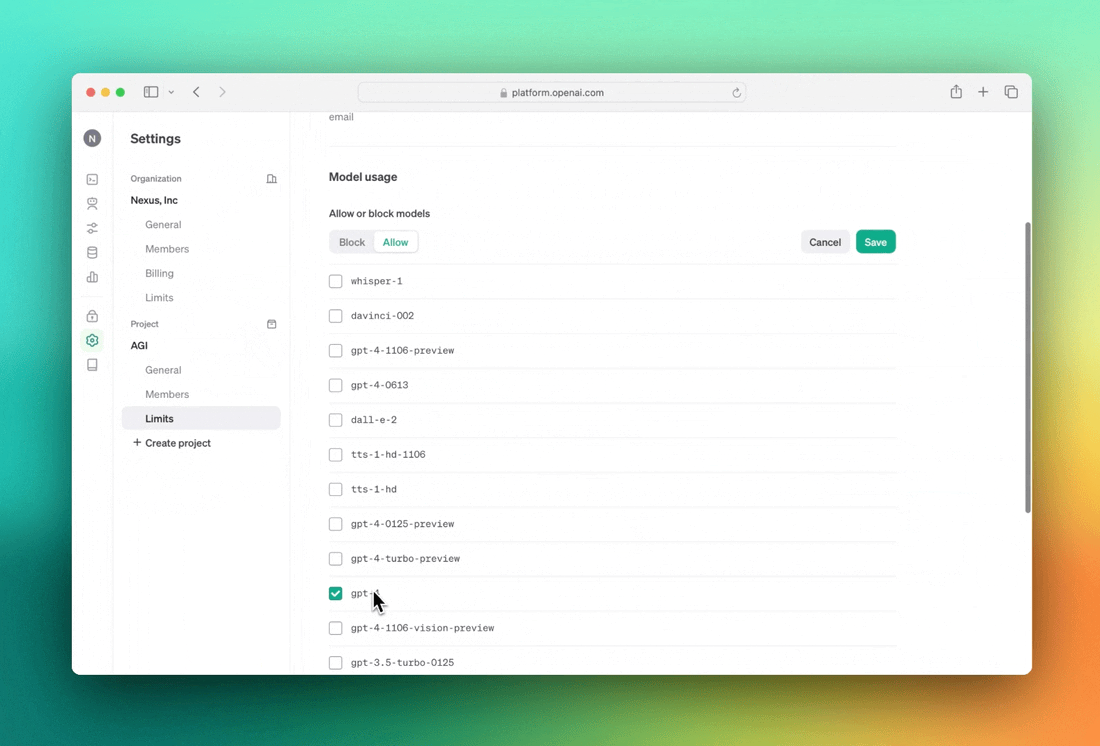 Il team sta introducendo poi un migliore controllo d’amministrazione. Con la nuova funzione Projects, le organizzazioni avranno un controllo e una supervisione più granulari sui singoli progetti di OpenAI. Questo include la possibilità di assegnare ruoli e chiavi API a progetti specifici, di limitare/consentire quali modelli rendere disponibili e di impostare limiti di utilizzo e tariffe per consentire l’accesso ed evitare sovraccarichi imprevisti. Gli owner dei progetti avranno anche la possibilità di creare chiavi API per gli account di servizio, che consentono l’accesso ai progetti senza essere legati a un singolo utente.
Il team sta introducendo poi un migliore controllo d’amministrazione. Con la nuova funzione Projects, le organizzazioni avranno un controllo e una supervisione più granulari sui singoli progetti di OpenAI. Questo include la possibilità di assegnare ruoli e chiavi API a progetti specifici, di limitare/consentire quali modelli rendere disponibili e di impostare limiti di utilizzo e tariffe per consentire l’accesso ed evitare sovraccarichi imprevisti. Gli owner dei progetti avranno anche la possibilità di creare chiavi API per gli account di servizio, che consentono l’accesso ai progetti senza essere legati a un singolo utente.
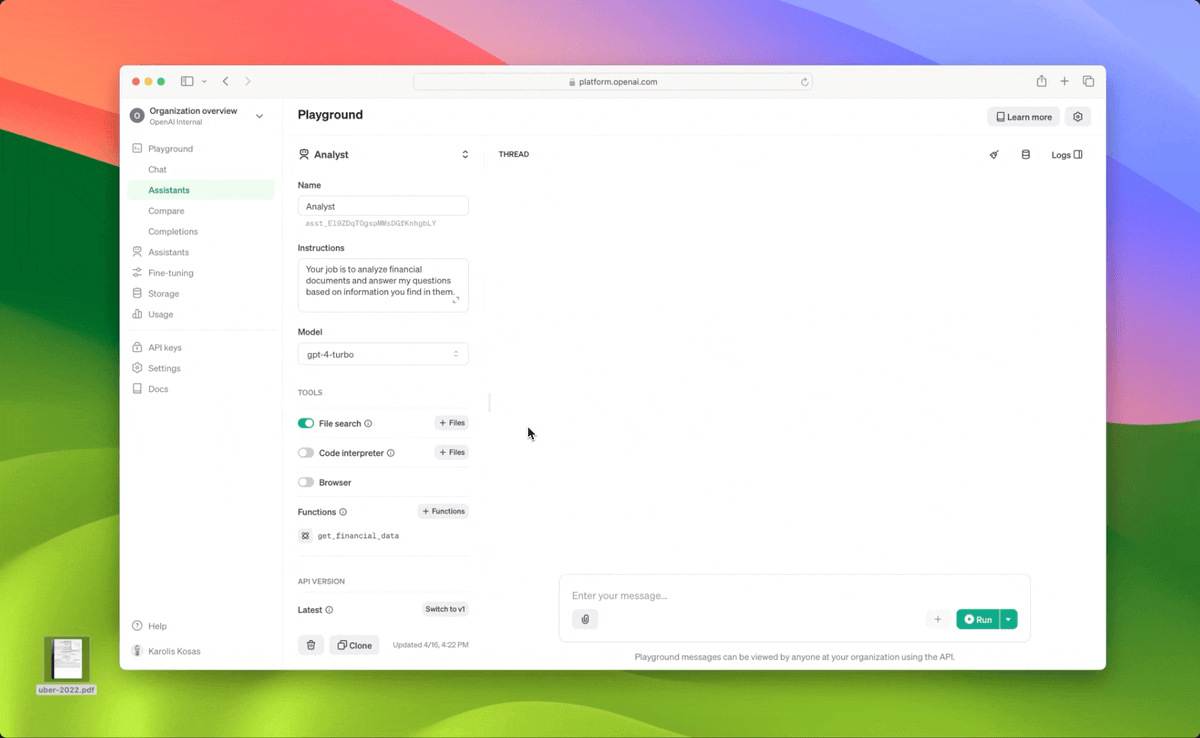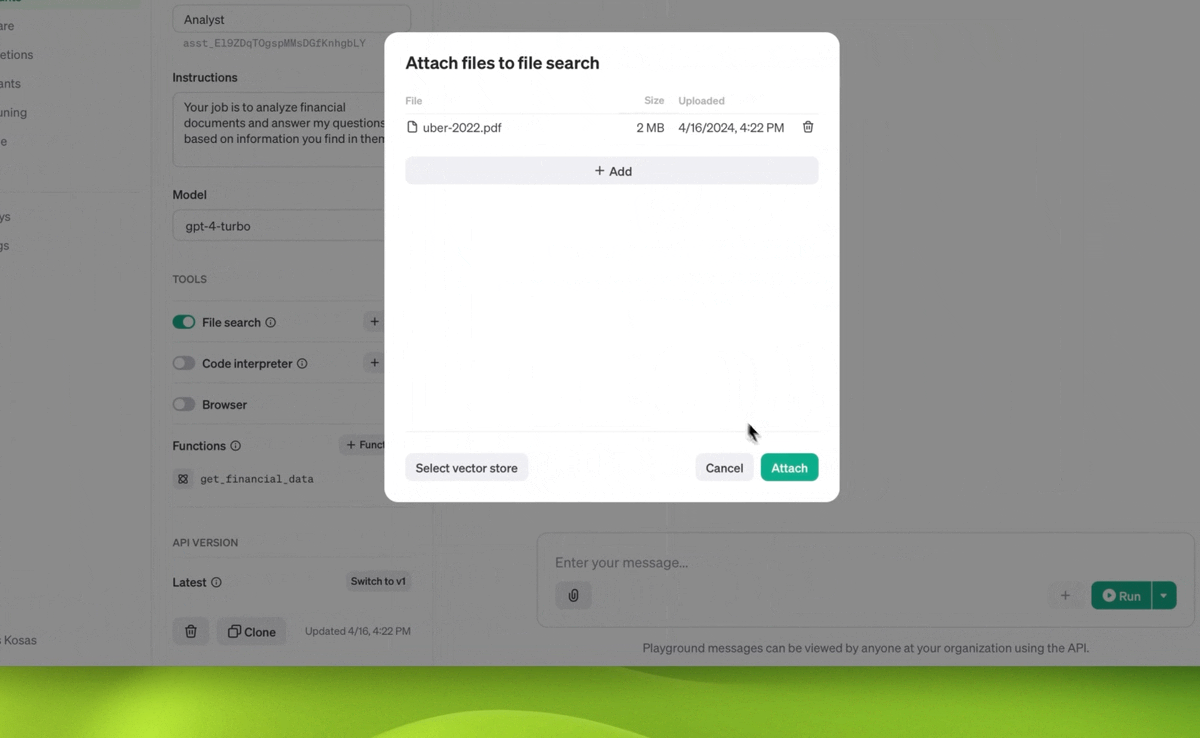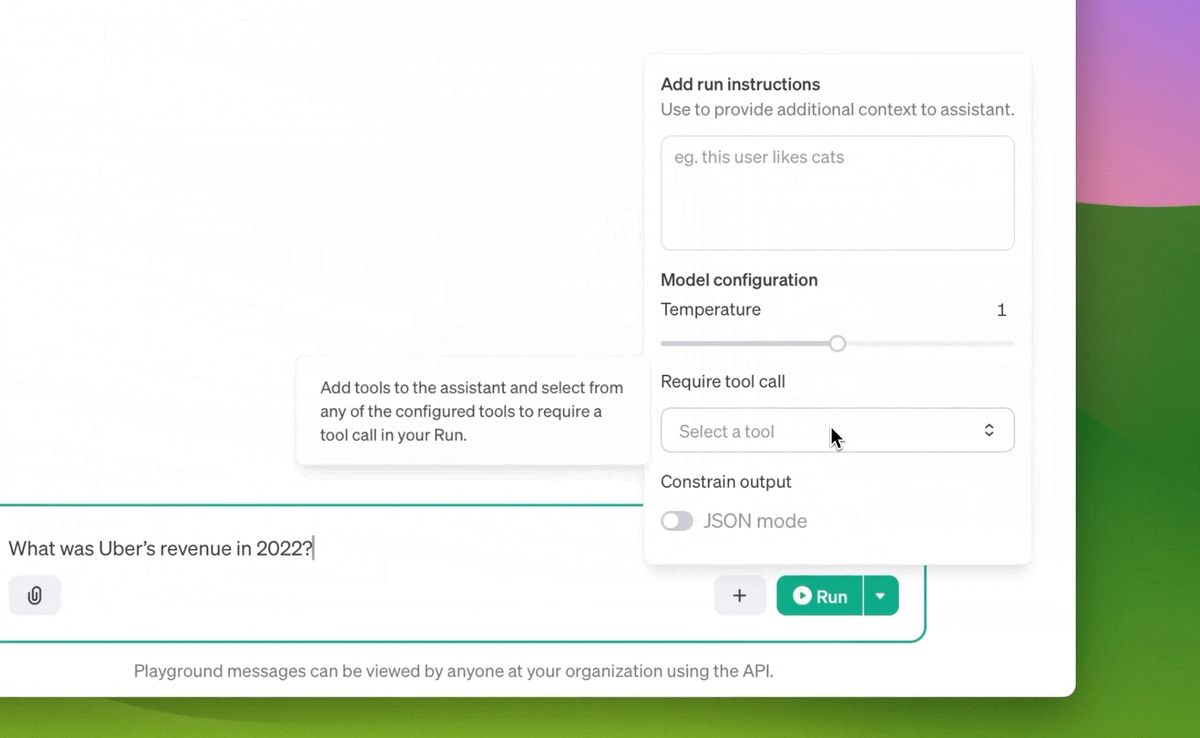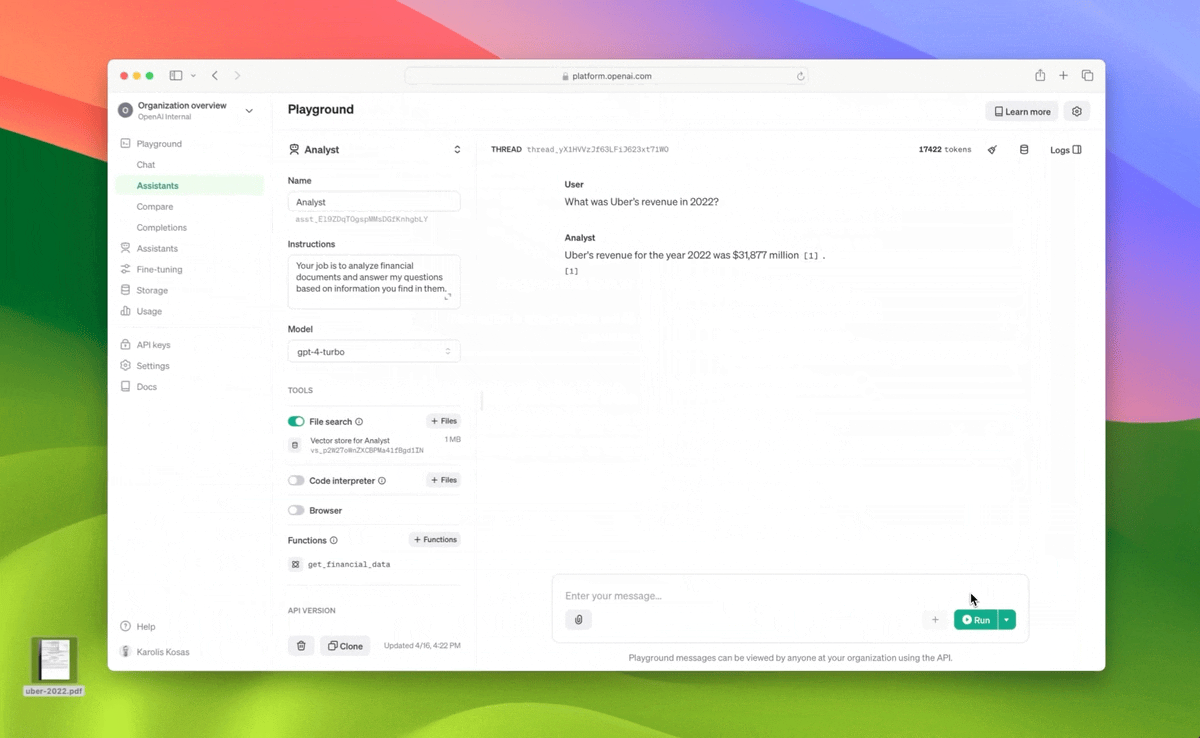
OpenAI ha inoltre introdotto diversi aggiornamenti alla Assistants API per un recupero più accurato, per la flessibilità del comportamento del modello e degli strumenti utilizzati per completare le attività e per un migliore controllo dei costi.
Queste caratteristiche includono:
- Miglioramento del retrieval con “file_search” che può inserire fino a 10.000 file per assistente, un aumento di 500 volte rispetto al precedente limite di 20 file. Lo strumento è più veloce, supporta le query in parallelo attraverso ricerche multi-thread e ha migliorato il reranking e la riscrittura delle query.
- Supporto dello streaming per risposte conversazionali in tempo reale, una delle richieste più frequenti da parte di sviluppatori e aziende.
- Nuovi oggetti “vector_store” nell’API, in modo che i file possano essere aggiunti a un vector store e automaticamente analizzati, raggruppati e incorporati in preparazione alla ricerca dei file. Gli archivi vettoriali possono essere utilizzati tra assistenti e thread, semplificando la gestione dei file e la fatturazione.
- Controllo del numero massimo di token utilizzati per ogni esecuzione, oltre a limiti sui messaggi precedenti e recenti utilizzati in ogni esecuzione, in modo da poter gestire i costi di utilizzo dei token.
- Nuovo parametro “tool_choice” per selezionare uno strumento specifico (come “file_search”, “code_interpreter” o “function”) in una particolare sessione.
- Supporto per i modelli GPT-3.5 Turbo fine-tuned nell’API (per iniziare, la piattaforma supporterà fine-tune di ‘gpt-3.5-turbo-0125’).
 Infine, OpenAI sta introducendo più opzioni per la gestione dei costi. Per aiutare le organizzazioni a scalare l’utilizzo dell’intelligenza artificiale senza sforare il budget, il team ha aggiunto due nuovi modi per ridurre i costi dei carichi di lavoro coerenti e asincroni:
Infine, OpenAI sta introducendo più opzioni per la gestione dei costi. Per aiutare le organizzazioni a scalare l’utilizzo dell’intelligenza artificiale senza sforare il budget, il team ha aggiunto due nuovi modi per ridurre i costi dei carichi di lavoro coerenti e asincroni:
- Utilizzo scontato sul committed throughput: I clienti con un livello sostenuto di utilizzo di token al minuto (TPM) su GPT-4 o GPT-4 Turbo possono richiedere l’accesso al throughput in provisioning per ottenere sconti che vanno dal 10 al 50% in base all’entità dell’impegno.
- Costi ridotti per i carichi di lavoro asincroni: I clienti possono utilizzare la nuova API Batch per eseguire carichi di lavoro non urgenti in modo asincrono. Le richieste API Batch hanno un prezzo ridotto del 50% rispetto ai prezzi condivisi, spiega OpenAI, offrono limiti di velocità molto più elevati e restituiscono i risultati entro 24 ore. È l’ideale per casi d’uso come la valutazione dei modelli, la classificazione offline, la sintesi e la generazione di dati sintetici.
Per maggiori informazioni sulle novità e sulle funzionalità, è possibile consultare la documentazione dell’API di OpenAI.









{kind=link}