


TensorFlow Similarity è un package Python progettato per rendere facile e veloce il training di modelli di similarità utilizzando la piattaforma open source end-to-end di machine learning TensorFlow.
La capacità di cercare elementi correlati ha molte applicazioni nel mondo reale, ha illustrato il team di TensorFlow: dal trovare vestiti simili, all’identificare la canzone che sta suonando, all’aiutare a salvare animali domestici scomparsi.
Più in generale, essere in grado di recuperare rapidamente elementi correlati è una parte vitale di molti sistemi informativi di base come le ricerche multimediali, i sistemi di raccomandazione e le pipeline di clustering.
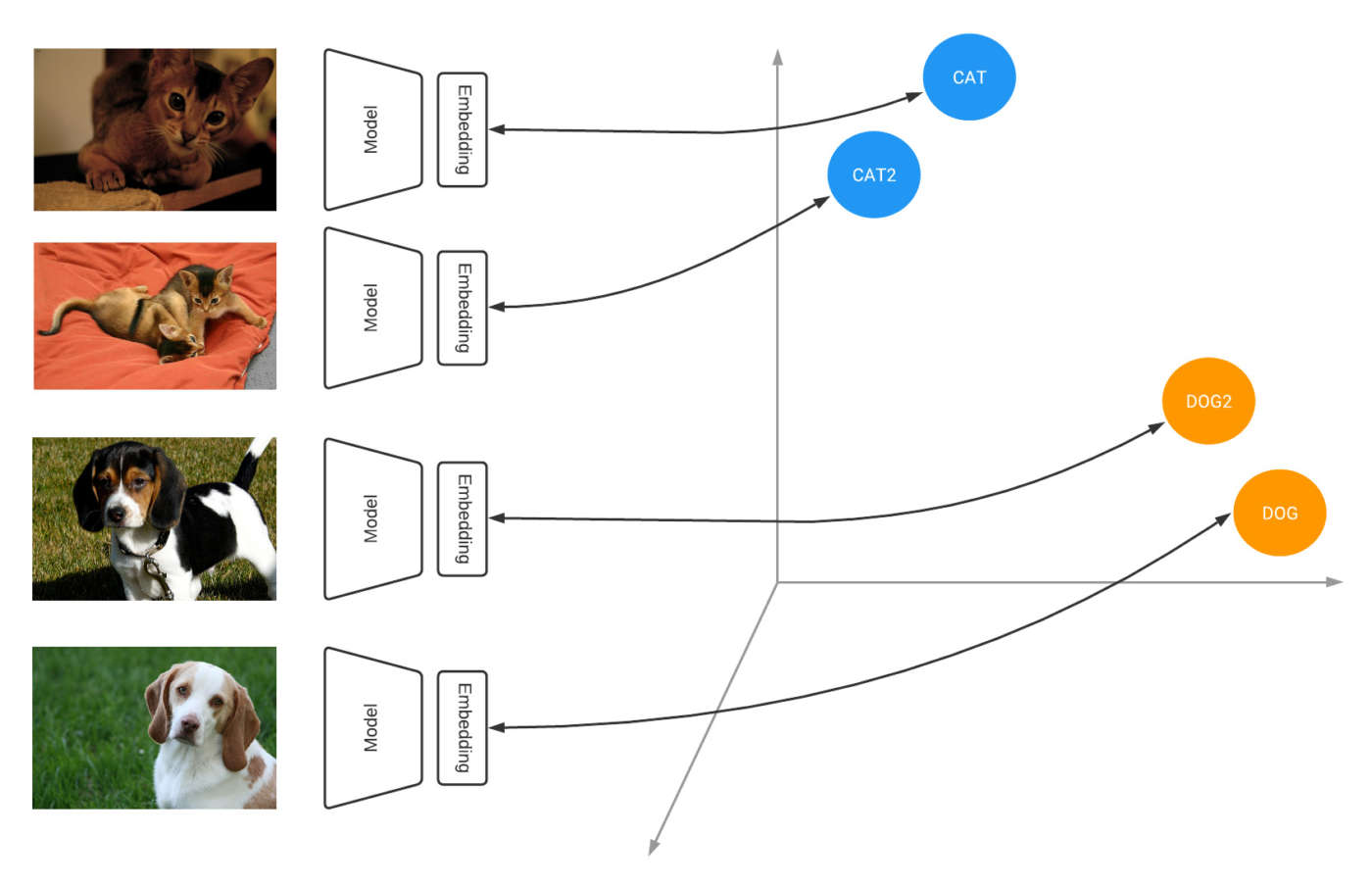
Sotto il cofano, molti di questi sistemi sono potenziati da modelli di deep learning che sono addestrati utilizzando il contrastive learning. L’apprendimento contrastivo insegna al modello ad apprendere uno spazio di inclusione in cui gli esempi simili sono vicini, mentre quelli dissimili sono lontani. Ad esempio, le immagini appartenenti alla stessa classe sono riunite insieme, mentre le classi distinte sono allontanate l’una dall’altra.
Se applicate a un intero set di dati, spiega ancora il team di TensorFlow, le perdite contrastive permettono a un modello di imparare come proiettare gli elementi nello spazio di embedding in modo che le distanze tra gli embedding siano rappresentative di quanto sono simili gli esempi in input.
Alla fine del training ci si ritrova con uno spazio ben clusterizzato dove la distanza tra elementi simili è piccola e la distanza tra elementi dissimili è grande.

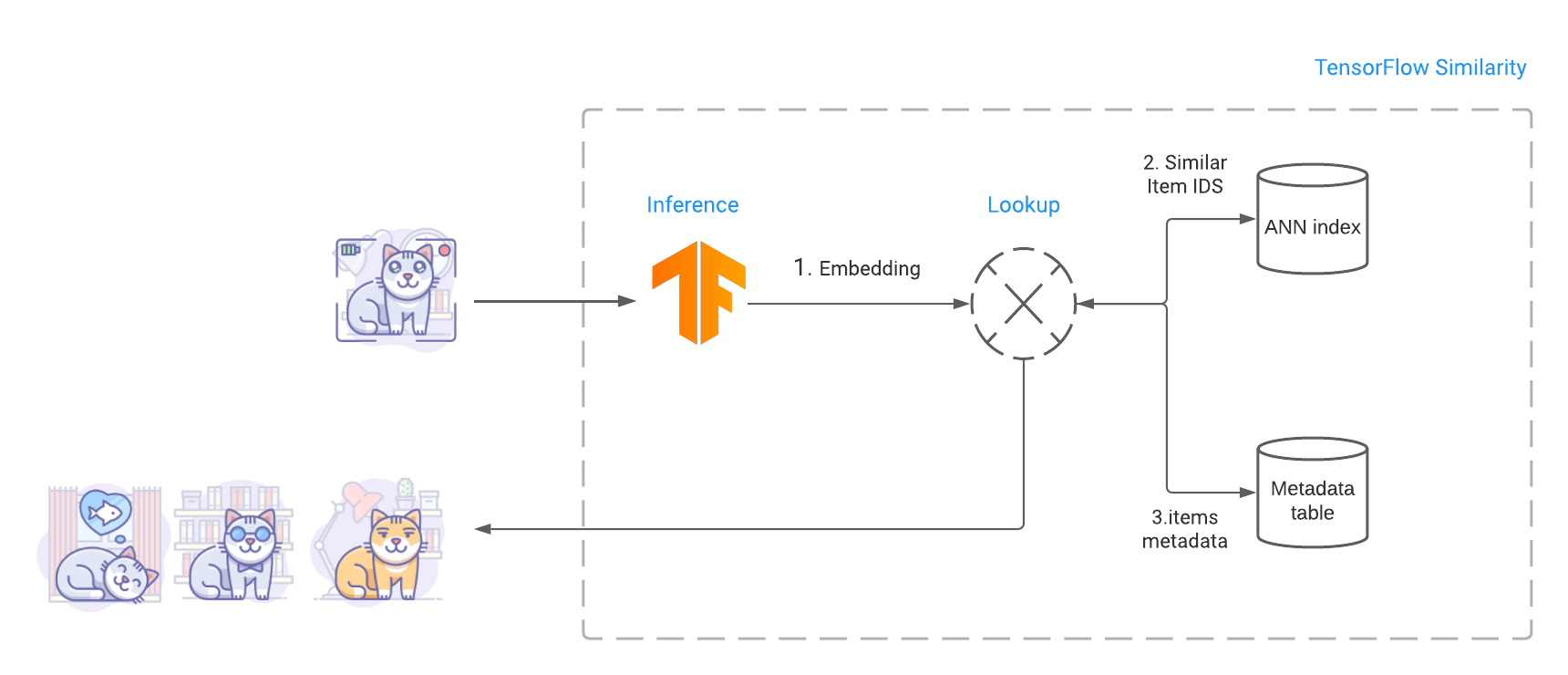
Una volta che il modello è addestrato, si costruisce un indice che contiene gli embedding dei vari elementi che si vuole rendere ricercabili. Poi, al momento della query, TensorFlow Similarity sfrutta la ricerca Fast Approximate Nearest Neighbor (ANN) per recuperare gli elementi più vicini dall’indice in tempo sub-lineare.
Questa ricerca è veloce e porta ad un’alta precisione di recupero, sottolinea il team di TensorFlow, oltre a essere più facilmente scalabile. Il sistema di indicizzazione Approximate Nearest Neighboring integrato in TensorFlow Similarity, che si basa su NMSLIB, rende possibile la ricerca su milioni di elementi indicizzati, recuperando le top-K corrispondenze simili in una frazione di secondo.
Oltre all’accuratezza e alla velocità di recupero, l’altro grande vantaggio dei modelli di similarità è che permettono di aggiungere un numero illimitato di nuove classi all’indice senza dover riqualificare. C’è solo bisogno di calcolare gli embedding per elementi rappresentativi delle nuove classi e aggiungerli all’indice.
Questa capacità di aggiungere dinamicamente nuove classi è particolarmente utile quando si affrontano problemi in cui il numero di elementi distinti è sconosciuto in anticipo, cambia costantemente o è estremamente grande.
TensorFlow Similarity fornisce tutti i componenti necessari per rendere la valutazione del similarity training e l’interrogazione intuitivi e facili. In particolare, TensorFlow Similarity introduce SimilarityModel(), un nuovo modello Keras che supporta nativamente l’indicizzazione e l’interrogazione di embedding. Ciò consente di eseguire il training e la valutazione end-to-end in modo rapido ed efficiente.
È possibile iniziare a sperimentare con TensorFlow Similarity con il tutorial “Hello World” pubblicato online e tutte le informazioni sono sul repository GitHub del progetto.









{kind=link}