


Google Cloud ha annunciato il rilascio di un connettore open source per leggere flussi di messaggi da Pub/Sub Lite in Apache Spark.
Pub/Sub Lite è un servizio di messaging scalabile e gestito per gli utenti Spark su Google Cloud Platform che hanno bisogno di una soluzione di ingestion a basso costo e che supporti volumi elevati.
Il connettore consente di utilizzare Pub/Sub Lite come fonte per il motore di elaborazione di Structured Streaming con garanzie exactly-once e latenze di processing di ~100ms: funziona in tutte le distribuzioni Apache Spark 2.4.X, comprese le installazioni Dataproc, Databricks o Spark manuale.
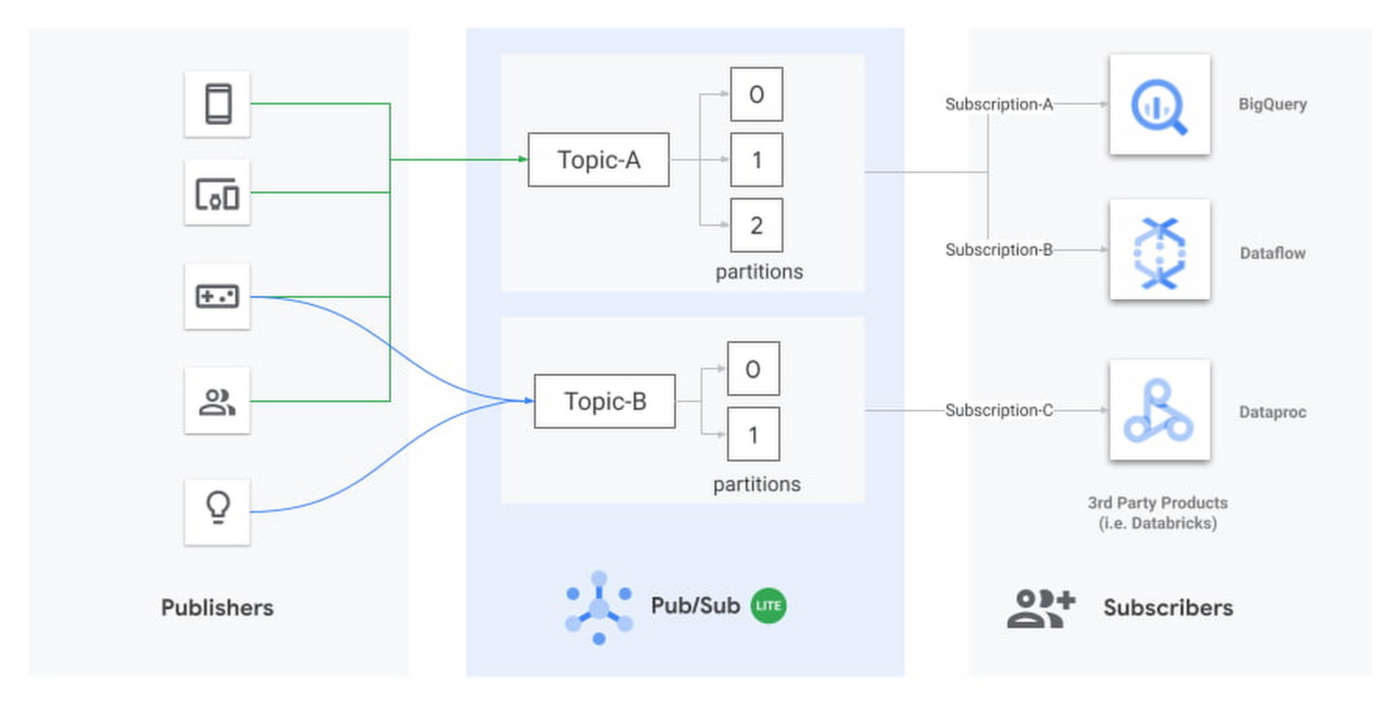
Il servizio di messaging Pub/Sub Lite è stato rilasciato di recente: è scalabile orizzontalmente e permette di inviare e ricevere messaggi in modo asincrono tra applicazioni indipendenti. Le applicazioni publisher pubblicano messaggi su un topic Pub/Sub Lite, e le applicazioni subscriber (come Apache Spark) leggono i messaggi dal topic.
Pub/Sub Lite è un servizio legato alla zona. Mentre è possibile connettersi a Pub/Sub Lite da qualsiasi parte di Internet, l’esecuzione di applicazioni publisher e subscriber nella stessa zona del topic a cui si connettono aiuta a minimizzare i costi di networking in uscita e la latenza.
Un topic Lite consiste in un numero preconfigurato di partizioni. Ogni partizione è un registro di messaggi con timestamp e ciascun messaggio è un oggetto con diversi campi, tra cui il corpo, un timestamp di evento configurabile dall’utente e un publish_timestamp impostato automaticamente in base a quando Pub/Sub Lite memorizza il messaggio in arrivo.
Un topic ha una capacità di throughput e di memorizzazione che l’utente può configurare considerando proprietà quali il numero di partizioni, la capacità di archiviazione/throughput per ogni partizione e il periodo di conservazione dei messaggi. Il modello di pricing di Pub/Sub Lite, sottolinea Google Cloud, si basa sulla capacità di throughput e di archiviazione dei topic forniti.
Apache Spark, dal canto suo, è un popolare framework di elaborazione che è comunemente usato come sistema di elaborazione batch.
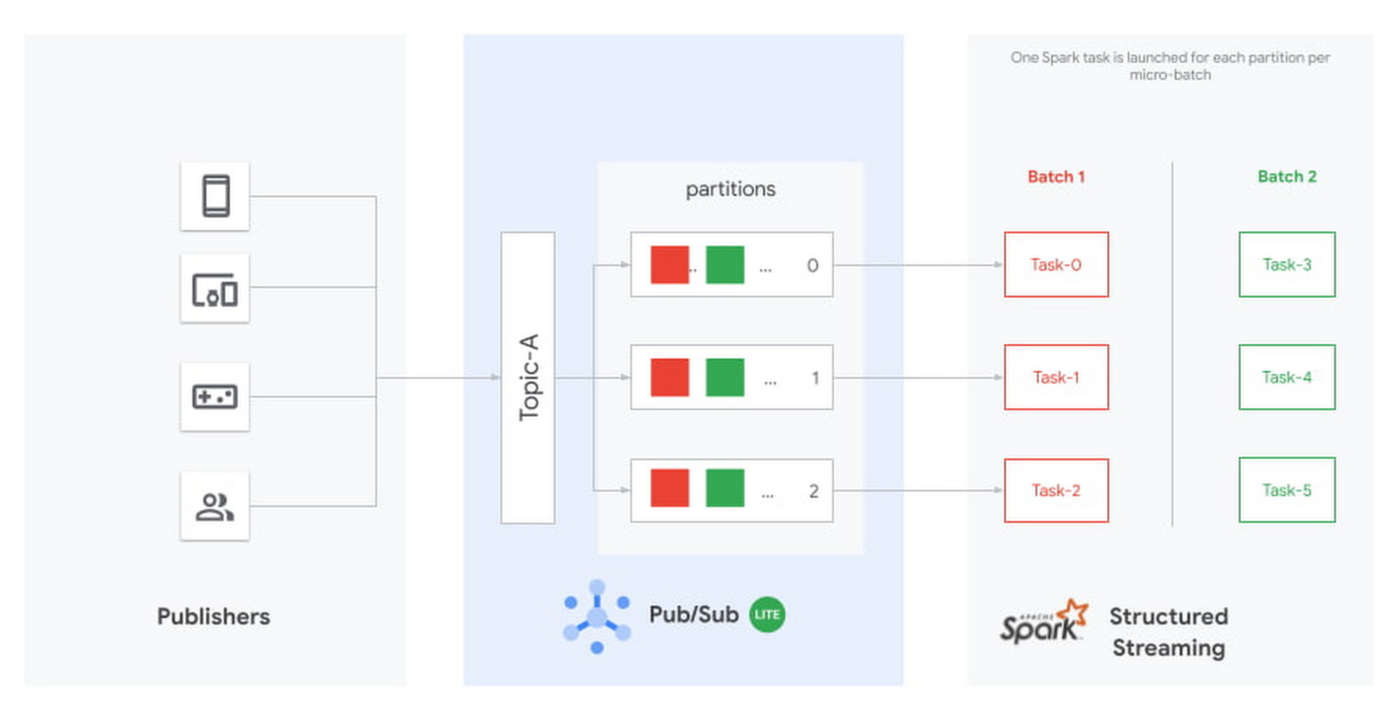
L’elaborazione in streaming è stata introdotta in Spark 2.0 usando un engine micro-batch che elabora i data stream come piccoli job in batch che periodicamente leggono nuovi dati dalla fonte di streaming, quindi eseguono una query o un calcolo su di essi.
Il connettore Pub/Sub Lite Spark supporta Pub/Sub Lite come sorgente di input per Apache Spark Structured Streaming sia nella modalità predefinita di MicroBatch Processing che nella modalità sperimentale di Continuous Processing.









{kind=link}