


Nel suo evento virtuale di presentazione delle ultime innovazioni nel campo dell’intelligenza artificiale, oltre che di assistenti digitali, Meta ha parlato anche di novità importanti nelle tecnologie di traduzione automatica.
Tecnologie di traduzioni dalle quali – ha sottolineato Meta –, miliardi di persone rimangono però ancora escluse. Perché non possono accedere facilmente alle informazioni presenti su Internet oppure non nella propria lingua madre.
I sistemi di traduzione automatica (machine translation, MT) odierni fanno passi da gigante, ma il loro apprendimento è ancora basato su enormi quantità di dati testuali, mette in evidenza Meta.
Per questo motivo, difficilmente ottengono prestazioni elevate con lingue che dispongono di poche risorse, ovvero prive di dati di training e che non dispongono di un sistema di scrittura standardizzato.
Eliminare le barriere linguistiche sarebbe un cambiamento fondamentale che consentirebbe a miliardi di persone di accedere a informazioni online nella propria lingua madre, o in quella che preferiscono.
Secondo la società di Mark Zuckerberg, i progressi nella traduzione automatica non solo aiuteranno le persone che non parlano una delle lingue oggi predominanti su Internet. Ma cambieranno anche radicalmente il modo in cui le persone nel mondo si connettono e condividono idee.
E, nel costruire il metaverso, Meta intende impegnarsi per abilitare spazi virtuali immersivi a cui le persone possano prendere parte e dove riescano a comunicare tra loro indipendentemente dalle lingue che parlano.
Gli impegni di Meta per la traduzione automatica
In questo campo, Meta AI ha annunciato ora un impegno a lungo termine volto a creare strumenti linguistici e di traduzione automatica, che includeranno la maggior parte delle lingue presenti nel mondo.
Questo sforzo comprende due nuovi progetti.
Il primo è No Language Left Behind, nell’ambito del quale Meta sta costruendo un nuovo modello di intelligenza artificiale avanzato in grado di apprendere dalle lingue che dispongono di meno esempi da usare per l’addestramento.
In seguito, Meta lo utilizzerà per realizzare traduzioni di qualità professionale in centinaia di lingue, dall’asturiano al luganda e all’urdu.
Il secondo progetto è Universal Speech Translator, nell’ambito del quale l’azienda sta ideando nuovi approcci per tradurre in tempo reale il testo parlato da una lingua a un’altra. Con l’obiettivo di poter supportare sia le lingue prive di un sistema di scrittura standard, sia quelle scritte e parlate.
La condivisione dei dettagli e l’inserimento nell’ambito open source del codice e dei modelli previsti in futuro, significa che altri potranno potenziare il lavoro di Meta per raggiungere questo importante obiettivo.
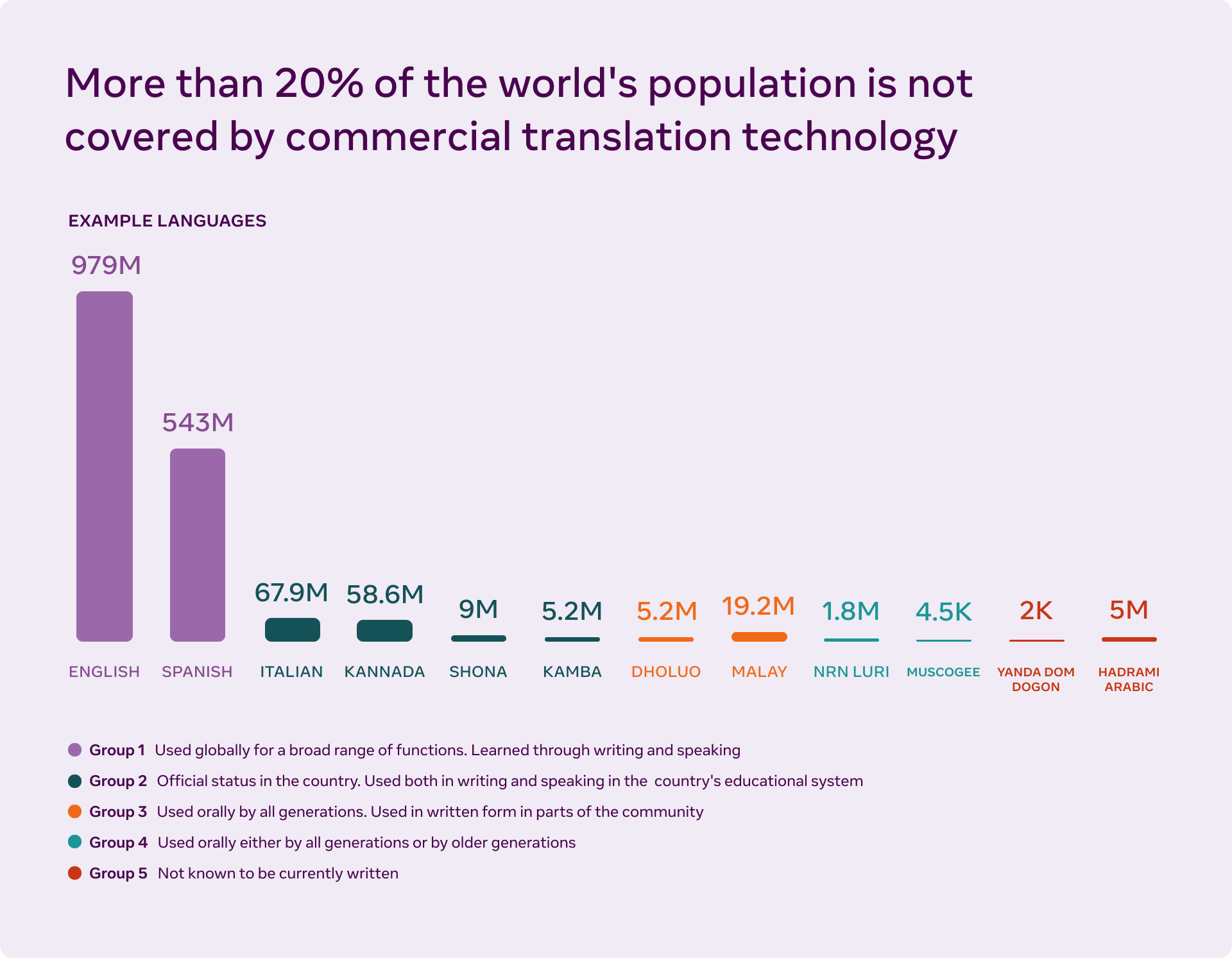
Questa necessità, secondo Meta, nasce dal fatto che i sistemi di traduzione di oggi basati sull’intelligenza artificiale non sono progettati per servire le migliaia di lingue utilizzate in tutto il mondo o per fornire la traduzione vocale in tempo reale.
Per riuscire a servire veramente tutti, la comunità di ricerca sulla traduzione automatica dovrà superare tre importanti sfide.
In promo luogo, la carenza di dati, e lo si può fare acquisendo un numero maggiore di dati di addestramento in più lingue e trovando nuovi modi per sfruttare i dati attualmente disponibili.
Poi, i ricercatori dovranno superare le sfide di modellazione che si presentano, man mano che i modelli aumentano per servire molte più lingue.
Inoltre, sarà anche necessario trovare nuovi modi per valutare e migliorare i risultati.
Come abbattere le barriere linguistiche
La carenza di dati rimane, secondo Meta, uno dei maggiori ostacoli allo sviluppo degli strumenti di traduzione automatica in più lingue.
I sistemi di MT per le traduzioni di testo, in genere, si basano sull’apprendimento a partire da milioni di frasi di dati annotati.
Per questo motivo, sono stati sviluppati sistemi di MT in grado di eseguire traduzioni di alta qualità solo per un numero ristretto di lingue che dominano il web.
Includere altre lingue significa trovare nuovi modi per acquisire e utilizzare esempi per l’addestramento, a partire da lingue con scarse presenze sul web.
Per quanto riguarda la traduzione vocale diretta, la sfida legata all’acquisizione dei dati è ancora più ardua.
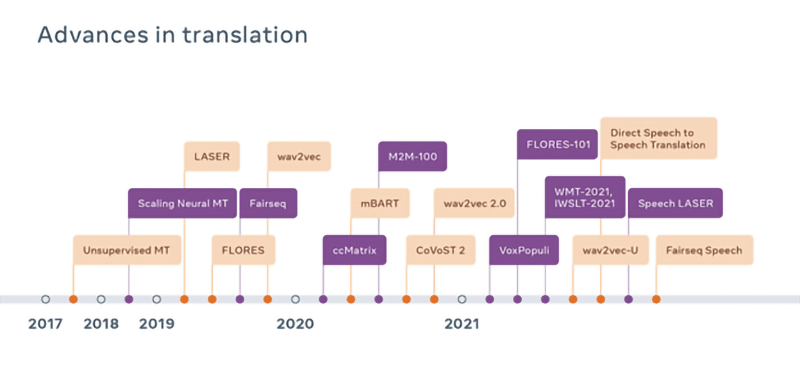
La maggior parte dei sistemi di traduzione automatica vocale utilizza il testo come passaggio intermedio, sottolinea Meta. Questo significa che il parlato in una lingua viene prima convertito in testo, quindi tradotto in testo nella lingua di destinazione, e infine inserito in un sistema di sintesi vocale (text to speech) per generare l’audio.
Ciò rende le traduzioni vocali dipendenti dal testo, in un modo che ne limita l’efficienza e ne rende difficile l’adattamento alle lingue prevalentemente orali.
I modelli di traduzione vocale diretta possono consentire traduzioni per lingue che non dispongono di sistemi di scrittura standardizzati, mette in evidenza Meta.
Questo approccio potrebbe anche portare a sistemi di traduzione molto più veloci ed efficienti, dal momento che non necessiteranno dei passaggi aggiuntivi.
I sistemi di MT, oltre a richiedere dati di addestramento adeguati in migliaia di lingue, oggi semplicemente non sono progettati per adattarsi alle esigenze di tutti a livello globale.
Le sfide da superare
Molti di questi sistemi sono bilingue, il che significa che esiste un modello separato per ogni coppia di lingue, come inglese-russo o giapponese-spagnolo.
È estremamente difficile adattare questo approccio a dozzine di coppie di lingue, per non parlare di tutte le lingue usate nel mondo. Si dovrebbero creare e gestire molte migliaia di modelli diversi per ogni combinazione.
Molti esperti hanno suggerito che, in questo caso, potrebbero rivelarsi utili i sistemi multilingue.
Ma inserire molte lingue in un unico modello multilingue efficiente e a elevate prestazioni, con una capacità tale da rappresentare la totalità delle lingue, è stato estremamente difficile.
I modelli di traduzione vocale in tempo reale affrontano molte delle stesse sfide dei modelli testuali. Ma, prima di poter essere utilizzati efficacemente per traduzioni in tempo reale, devono anche superare la latenza, ovvero il ritardo che si verifica quando una lingua viene tradotta in un’altra.
La sfida principale deriva dal fatto che una frase può essere pronunciata usando diversi ordini di parole in lingue differenti. Anche gli interpreti simultanei professionisti hanno un ritardo di circa tre secondi, rispetto al discorso originale.

Inoltre, man mano che i ricercatori si concentrano su un numero sempre maggiore di lingue, bisogna anche sviluppare nuovi modi per valutare i risultati prodotti dai modelli di traduzione automatica.
Esistono già delle risorse per valutare la qualità delle traduzioni, ad esempio, dall’inglese al russo, ma che dire della combinazione – ad esempio – amarico-kazako?
Oltre a valutare le prestazioni dei sistemi di MT in termini di accuratezza, è anche importante assicurarsi che le traduzioni vengano eseguite in modo responsabile.
Occorre trovare dei modi per assicurarsi che i sistemi di traduzione automatica preservino le sensibilità culturali, senza creare o intensificare i pregiudizi.
Meta AI sta affrontando ciascuna di queste tre sfide.
Traduzione vocale diretta
Meta sta sviluppando le sue tecniche di creazione automatica di set di dati per rendere possibili le traduzioni in lingue con poche risorse. E per creare gli elementi di base per traduzioni future in un numero maggiore di lingue scritte o parlate, indipendentemente dalla loro diffusione.
Una di queste tecniche è Laser, un toolkit open source che ora comprende più di 125 lingue scritte in 28 script diversi.
Laser converte frasi di varie lingue in un’unica rappresentazione multilingue.
In seguito, Meta utilizza una ricerca di similarità multilingue su vasta scala per identificare le frasi che hanno una rappresentazione simile, cioè quelle che è probabile che abbiano lo stesso significato in lingue diverse.
Per le lingue con risorse limitate, Meta ha creato un nuovo metodo di addestramento teacher-student che consente a Laser di concentrarsi su sottogruppi linguistici specifici e di apprendere da set di dati molto più ridotti.
Ciò consente a Laser di operare efficacemente su vasta scala in tutte le lingue.

Ognuno di questi progressi – secondo Meta – consentirà all’azienda di coprire più lingue mentre lavora per ridimensionarle, migliorarle ed ampliarle al fine di supportare l’accesso a centinaia di lingue. E, in seguito, di supportare l’accesso a ogni lingua con un sistema di scrittura.
Di recente Meta ha ampliato Laser affinché funzioni anche con il testo parlato.
La creazione di rappresentazioni per il parlato e per il testo nello stesso spazio multilingue, consente di estrarre traduzioni tra il parlato in una lingua e il testo in un’altra, o persino traduzioni vocali dirette.
Grazie a questo metodo, Meta ha già identificato quasi 1.400 ore di testo parlato allineato in francese, tedesco, spagnolo e inglese.
I dati e le risorse
I dati del testo sono importanti, ma non sufficienti per creare strumenti di traduzione in grado di soddisfare le esigenze di tutti.
I dati di riferimento della traduzione vocale erano disponibili in precedenza per un numero limitato di lingue, quindi Meta ha creato CoVoST 2, che copre 22 lingue e 36 direzioni linguistiche con un diverso stato di risorse.
Inoltre, è difficile trovare grandi quantità di audio in lingue diverse. VoxPopuli, che comprende 400.000 ore di parlato in 23 lingue, consente l’apprendimento semi-supervisionato e auto-supervisionato su vasta scala per applicazioni come il riconoscimento vocale e la traduzione vocale.
VoxPopuli è stato successivamente utilizzato per creare il più grande modello pre-addestrato aperto e universale per 128 lingue e task vocali, compresa la traduzione vocale.
Questo modello – sottolinea Meta – ha migliorato lo stato dell’arte precedente per la traduzione da parlato a testo da 21 lingue all’inglese, raggiungendo un punteggio BLEU di 7,4 sul set di dati di CoVoST 2.
Modelli per traduzioni multilingue
Meta sta poi lavorando al perfezionamento della capacità del modello al fine di poter gestire le traduzioni tra una gamma molto più ampia di lingue.
Oggi, i sistemi di traduzione automatica spesso funzionano all’interno di un’unica modalità e in un numero limitato di lingue. Se le dimensioni del modello sono troppo piccole per rappresentare molte lingue, le sue prestazioni potrebbero risentirne e quindi introdurre imprecisioni sia nella traduzione del testo che del parlato.
Le innovazioni nel campo della modellazione – sostiene Meta – consentiranno di creare un futuro in cui le traduzioni si sposteranno rapidamente e senza interruzioni attraverso le varie modalità. Passando dal parlato al testo, dal testo al parlato, dal testo al testo o dal parlato al parlato in una miriade di lingue.
Per migliorare le prestazioni di MT, Meta ha investito in maniera considerevole nella creazione di nuovi modelli che si addestrano in modo efficiente nonostante le dimensioni.
Per estendere la traduzione automatica testuale a 101 lingue, Meta ha creato il primo sistema di traduzione di testi multilingue non incentrato sull’inglese.
I sistemi bilingue solitamente funzionano traducendo prima dalla lingua di partenza all’inglese e poi dall’inglese alla lingua di destinazione. Per aumentare l’efficienza e la qualità di questi sistemi, Meta ha eliminato l’elemento intermedio rappresentato dalla lingua inglese.
In questo modo le lingue possono essere tradotte direttamente in altre lingue senza dover passare appunto dall’inglese.
Ciò aumenta la capacità del modello, ma i modelli multilingue in precedenza non erano in grado di raggiungere lo stesso livello di qualità dei sistemi bilingue personalizzati.
Recentemente, però, il sistema di traduzione multilingue di Meta ha vinto il concorso Workshop on Machine Translation, superando anche le prestazioni dei migliori modelli bilingue.
Una tecnologia inclusiva
Meta vuole che la sua tecnologia sia inclusiva, quindi capace di supportare sia le lingue scritte che le lingue prive di un sistema di scrittura standard.
Con questo obiettivo in mente, l’azienda sta sviluppando un sistema di traduzione vocale che non si basa sulla generazione di una rappresentazione testuale intermedia durante l’inferenza.
Questo approccio – afferma l’azienda – si è rivelato essere più veloce di un tradizionale sistema a cascata che combina modelli separati di riconoscimento vocale, traduzione automatica e sintesi vocale.
Grazie a una maggiore efficienza e a un’architettura semplificata, la traduzione vocale diretta potrebbe risolvere una traduzione in tempo reale con una qualità quasi umana per i dispositivi futuri, come gli occhiali di realtà aumentata.
Inoltre, per creare traduzioni vocali in grado di conservare l’espressività e il carattere tipici dei discorsi di ognuno di noi, Meta sta lavorando per includere nelle traduzioni audio generate alcuni aspetti dell’audio in ingresso, come ad esempio l’intonazione.
Infine, la terza sfida da superare, è riuscire a valutare le prestazioni di un modello multilingue su vasta scala. Si tratta di una sfida complicata, che richiede tempo, molte risorse ed è spesso impraticabile.
Per questo Meta ha creato FLORES-101, il primo set di dati per la valutazione della traduzione multilingue.
Questo copre 101 lingue, consentendo ai ricercatori di testare e migliorare rapidamente i modelli di traduzione multilingue.
A differenza dei set di dati esistenti, FLORES-101 consente ai ricercatori di quantificare le prestazioni dei sistemi attraverso qualsiasi direzione linguistica, e quindi non solo traducendo da e verso l’inglese.
Nel caso dei milioni di persone in tutto il mondo che vivono in luoghi dove sono presenti dozzine di lingue ufficiali, questo permette di creare sistemi di traduzione in grado di soddisfare importanti necessità del mondo reale.
Il futuro della traduzione automatica
Meta ritiene che sta riuscendo a raggiungere progressi tangibili verso la traduzione universale, ma non dimentica l’importanza di svolgere questo lavoro in modo responsabile.
Per questo l’azienda collabora con linguisti per l’accuratezza dei dataset e la precisione delle traduzioni.
Inoltre, sta conducendo case study per più di 20 lingue per capire quali funzioni di traduzione sono importanti per persone con background diversi. E come queste utilizzeranno le traduzioni prodotte dai modelli di intelligenza artificiale di Meta.
Riuscire a raggiungere gli obiettivi di traduzione a lungo termine – sottolinea Meta – richiederà non solo esperienza nell’ambito dell’intelligenza artificiale, ma anche il contributo costante di numerosi esperti, ricercatori e persone da tutto il mondo.
Nella vision di Meta, se i progetti No Language Left Behind e Universal Speech Translator, uniti agli sforzi della comunità di ricerca, riusciranno a creare tecnologie di traduzione automatica che coinvolgono tutto il mondo, assisteremo all’apertura del mondo fisico e di quello digitale in modi prima di adesso impossibili.
Secondo Meta l’azienda sta già facendo progressi nell’abilitare le traduzioni per le lingue con poche risorse. Questa è una barriera significativa alla traduzione universale per la maggior parte della popolazione mondiale.
Facendo passi avanti nel suo lavoro e rendendolo open source con la creazione di corpus per la modellazione e la valutazione multilingue, Meta si augura che altri ricercatori possano potenziarlo e avvicinare i vari usi dei sistemi di traduzione alla quotidianità del mondo reale.
Leggi tutti i nostri articoli su Meta








{kind=link}