


Amazon Timestream, il servizio di database di serie temporali veloce, scalabile e serverless, è ora generalmente disponibile.
Timestream, sottolinea Amazon Web Services, è progettato per semplificare la raccolta, l’archiviazione, l’elaborazione e l’analisi di migliaia di miliardi di eventi di time series — serie temporali — al giorno, in modo fino a 1.000 volte più veloce e con fino a un 1/10 del costo rispetto a un database relazionale.
Ciò, spiega ancora Amazon AWS, è reso possibile dal modo in cui Timestream gestisce i dati: quelli recenti sono tenuti in memoria e i dati storici vengono spostati in un’archiviazione ottimizzata in base a una policy di retention definita dal cliente.
Tutti i dati vengono sempre replicati automaticamente in più zone di disponibilità (AZ, availability zones) nella stessa regione AWS. I nuovi dati vengono scritti nel memory store, dove i dati sono replicati in tre zone di disponibilità prima di restituire il successo dell’operazione. La replica dei dati è basata sul quorum in modo tale che la perdita di nodi, o di un’intera availability zone, non pregiudichi la durevolezza o la disponibilità.
Inoltre, i dati nel memory store vengono continuamente sottoposti a backup su Amazon Simple Storage Service (S3) come ulteriore precauzione.
Le query accedono automaticamente e combinano i dati recenti e storici tra i vari tier senza la necessità di specificare la posizione di archiviazione e supportano funzionalità specifiche per le serie temporali per aiutare a identificare trend e pattern nei dati in tempo quasi reale.
Non ci sono costi iniziali per il servizio, si paga solo per i dati che si scrivono, si memorizzano o si interrogano. In base al carico, Timestream scala automaticamente verso l’alto o verso il basso per regolare la capacità, senza la necessità di gestire l’infrastruttura sottostante.
Le serie temporali sono un formato di dati molto comune che descrive come le cose cambiano nel tempo. Alcune delle fonti di dati più comuni sono i macchinari industriali e dispositivi IoT, stack di infrastrutture It (come hardware, software e componenti di rete) e applicazioni che condividono i loro risultati nel tempo. La gestione efficiente dei dati delle serie temporali non è facile perché il loro data model non si adatta a database generici.
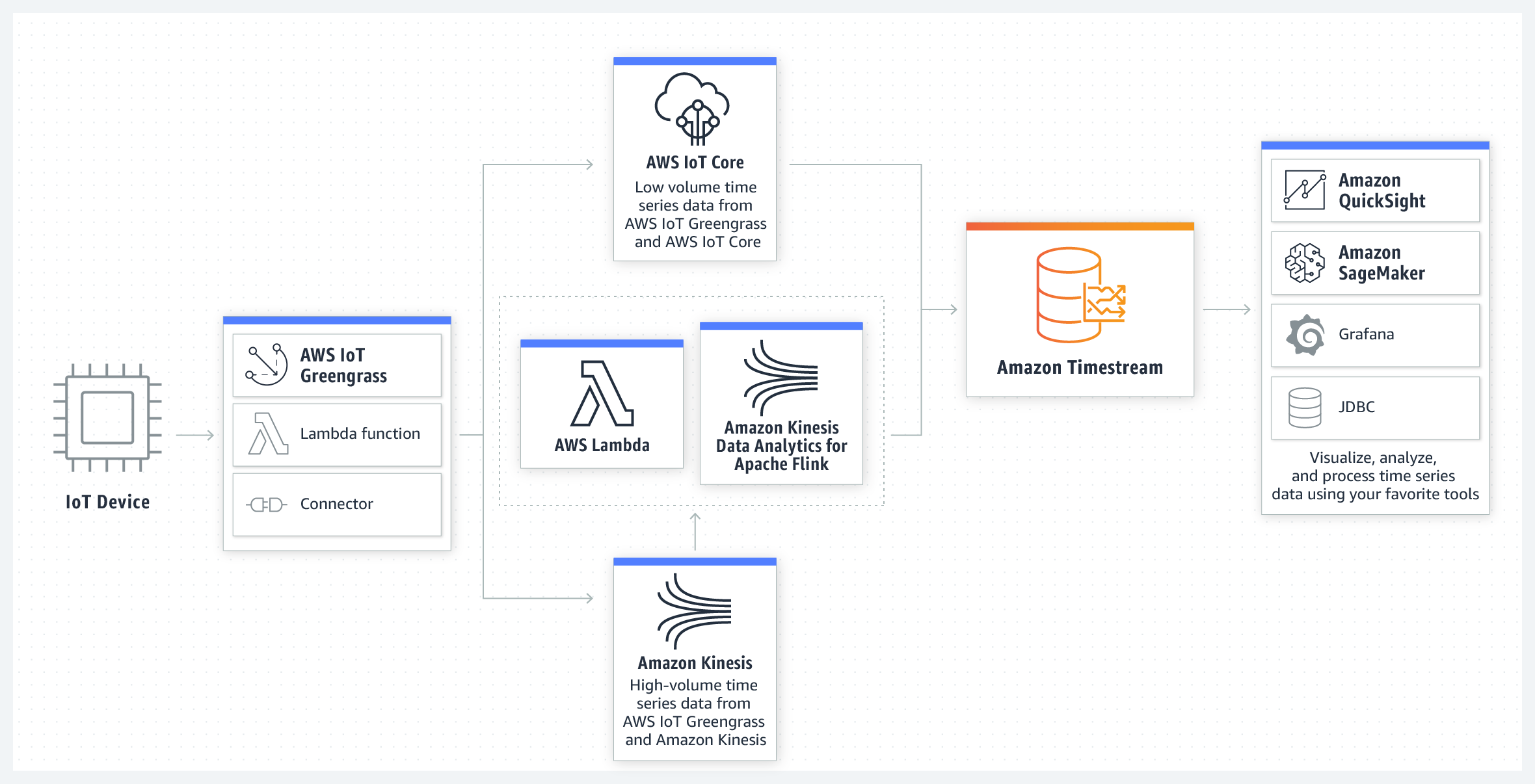
Amazon Timestream si integra con i più diffusi servizi di data collection, visualizzazione dei dati e machine learning, in modo che risulti facile da usare con applicazioni esistenti e nuove.
Ad esempio, è possibile eseguire l’ingesting dei dati direttamente da AWS IoT Core, Amazon Kinesis Data Analytics per Apache Flink e Amazon MSK. È possibile visualizzare i dati memorizzati in Timestream da Amazon QuickSight e utilizzare Amazon SageMaker per applicare algoritmi di machine learning ai dati delle serie temporali, ad esempio per il rilevamento di anomalie.
È anche possibile utilizzare i permessi AWS Identity and Access Management (IAM) di Timestream a grana fine per l’ingest o interrogare facilmente i dati da una funzione AWS Lambda. Amazon è impegnata anche a fornire gli strumenti per utilizzare Timestream con piattaforme open source come Apache Kafka, Telegraf, Prometheus e Grafana.









{kind=link}