


L’uso di data analytics per Amazon Web Services si sta espandendo in nuove aree di utenza all’interno delle organizzazioni.
Ad esempio, con utenti come gli sviluppatori e i business analyst che non hanno l’esperienza o il tempo per gestire un data warehouse tradizionale.
Inoltre, alcuni clienti di Aws hanno carichi di lavoro variabili con picchi imprevedibili e può essere molto difficile per loro gestire costantemente la capacità.
Amazon Redshift consente di usare SQL per analizzare dati strutturati e semi-strutturati attraverso data warehouse, database operativi e data lake.
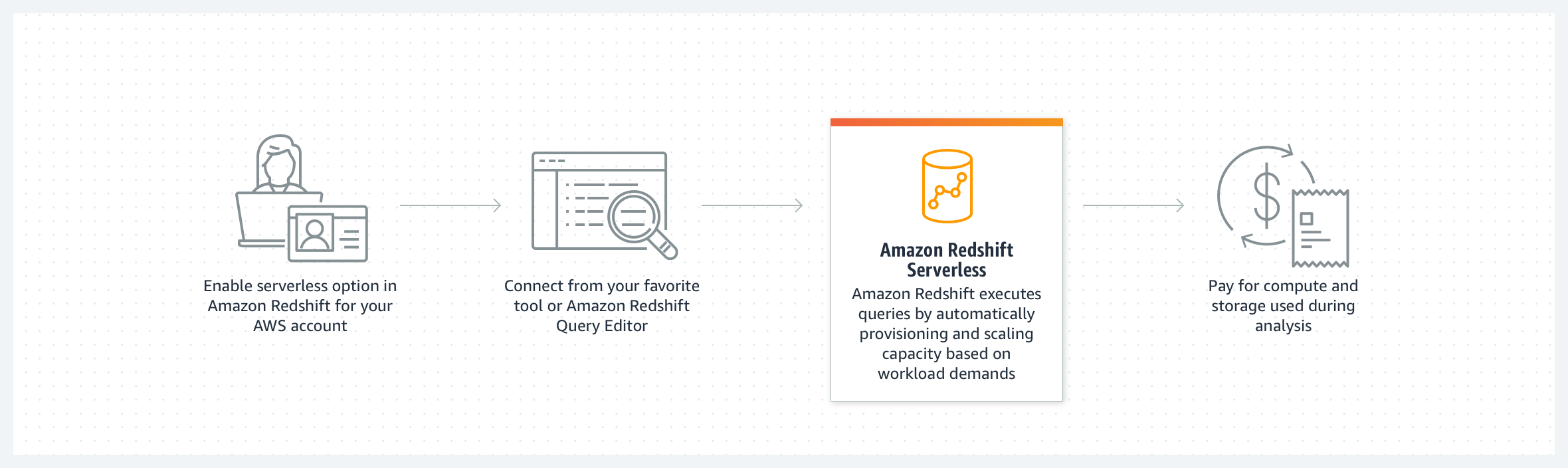
Aws ha ora lanciato, in public preview, Amazon Redshift Serverless, una nuova funzionalità che rende più facile fare analytics nel cloud con prestazioni elevate su qualsiasi scala.
Basta caricare i dati e avviare la query, promette Amazon Web Services. Senza alcun bisogno di impostare e gestire cluster. Inoltre, con un pricing basato sull’uso e che consente di ottimizzare i costi.
Amazon Redshift Serverless fornisce automaticamente le risorse di calcolo che servono per iniziare a eseguire attività di data analytics.
Man mano che le richieste evolvono, con più utenti simultanei e nuovi carichi di lavoro, il proprio data warehouse scala senza soluzione di continuità e automaticamente per adattarsi ai cambiamenti.
È possibile, opzionalmente, specificare le dimensioni del data warehouse di base, per avere un ulteriore controllo sui costi e sugli SLA specifici dell’applicazione.
Con la nuova opzione serverless, è possibile continuare a interrogare i dati in altri data store Aws, come i data lake Amazon Simple Storage Service (Amazon S3) e i database Amazon Aurora e Amazon Relational Database Service (RDS).
Amazon Redshift Serverless – sottolinea Aws – è uno strumento ideale quando è difficile prevedere le esigenze di calcolo, come avviene con carichi di lavoro variabili, workload periodici con tempi di inattività e carichi di lavoro stazionari con picchi.
Questo approccio si adatta anche meglio alle esigenze di analytics ad-hoc che devono essere avviate rapidamente e per gli ambienti di test e sviluppo.









{kind=link}