


{kind=link}
L’elaborazione di grandi quantità di dati, prima che diventassero big data e analytics, era diventata stabile su motori Sql affidati ad un modello di elaborazione parallela massiva e affidato all’hardware dedicato delle data warehouse.
Oggi questo modello è messo in discussione dai risultati di Hadoop. Le possibilità sono tre: la gestione di due diversi sistemi, la fine dell’Mpp database o la sua integrazione con il nuovo approccio. Come vedremo, quest’ultima soluzione, inizialmente ritenuta impraticabile, è in realtà già disponibile.
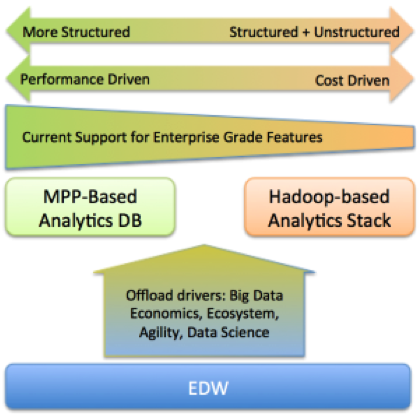 Le data warehouse appliances, in breve Dwa, sono sistemi preconfigurati (hardware e software, o anche solo software) specializzati nella gestione ed analisi dei big data. Per elaborare grandi quantità di dati si usa un’architettura Mpp, massive parallel processing: le risorse alle quali hanno accesso le Dwa non sono condivise, e i dati vengono suddivisi ed elaborati in parallelo su più unità.
Le data warehouse appliances, in breve Dwa, sono sistemi preconfigurati (hardware e software, o anche solo software) specializzati nella gestione ed analisi dei big data. Per elaborare grandi quantità di dati si usa un’architettura Mpp, massive parallel processing: le risorse alle quali hanno accesso le Dwa non sono condivise, e i dati vengono suddivisi ed elaborati in parallelo su più unità.
Dagli inizi all’Sql/NoSql
Le basi delle Dwa furono gettate negli anni ’80 da Model 204 e Teradata, che successivamente acquistò Britton Lee. Sempre in quel periodo erano competitor nel settore anche Tandem e Sequent.
All’epoca i dati erano registrati in Rdbms, database relazionali.
All’inizio degli anni 2000 iniziò un filone basato su hardware innovativo. Netezza annunciò una Fpga (field-programmable data array), un chip con logica e memoria che può essere configurato dopo la produzione; nel 2008 arrivò l’Sql chip di Kickfire.
Tutti i grandi produttori di software e hardware si organizzano con svariate soluzioni per la big data analysis. Tocca anche ad Ibm, che aveva già rielaborato il DB2 Warehouse nella famiglia software InfoSphere: nel 2009 l’integrazione di software ad-hoc porta all’InfoSphere Balanced Warehouse.
Linux diventa il sistema operativo di base, anche se non l’unico. Si opera sui file system. È forte la competizione dei database Sql e NoSql, che evolvono anche verso il cloud e l’elaborazione parallela.
Siamo agli anni nostri. Alla prova dei fatti, le architetture Mpp si mostrano rigide nell’elaborazione, con relativa scalabilità e problemi di affidabilità hardware. Inoltre si tratta di soluzioni quasi interamente proprietarie, che non sempre offrono vantaggi paragonabili a quelli d’un approccio misto aperto/chiuso. Infine, l’estrema verticalità delle soluzioni le rende ben poco adattabili alle variazioni di tipo di carico elaborativo richieste dall’evoluzione tecnologica.
Big data su Mpp
La gestione di due diversi sistemi, uno per dati transazionali e uno per dati non strutturati, può avere un senso. Un modello di coesistenza di Sql su Mpp proprietaria e Big Data con un certo livello di apertura lo si trova in Oracle. Il produttore statunitense aveva sviluppato un’architettura data warehouse molto orientata al cloud, nelle soluzioni composte dal software Oracle Database 12c e dell’hardware con storage Exadata. Nel passaggio ai big, open data, questa architettura resta la base anche per gli analytics del futuro. Il nuovo mondo verrà però gestito dalla Oracle Big Data Appliance, che opererà su due livelli: come un repository di nuove fonti di dati (social, video, machine-generated logs) e nuovi dati transazionali (classici o più granulari) che non troveranno posto nel data warehouse.
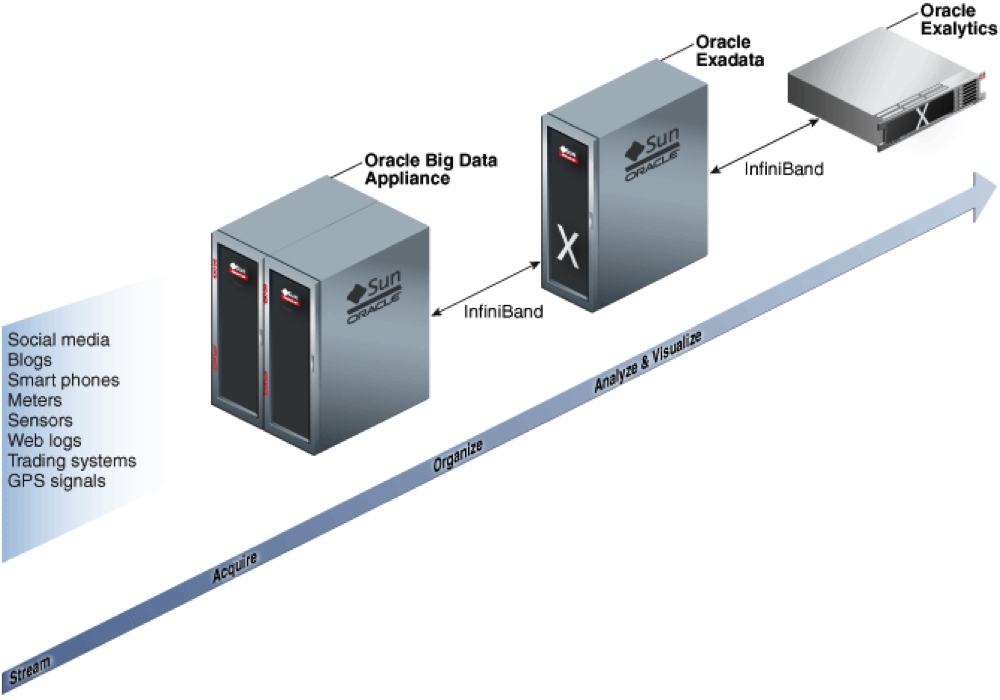 Più in dettaglio, la Bda eseguirà carichi Hadoop e NoSql, interoperando in maniera trasparente con il motore Sql su Exadata, ed affidando gli analytics all’appliance Exalitycs.
Più in dettaglio, la Bda eseguirà carichi Hadoop e NoSql, interoperando in maniera trasparente con il motore Sql su Exadata, ed affidando gli analytics all’appliance Exalitycs.
La virata su Hadoop
Le classiche soluzioni di analytics tramite query su Mpp sono molto diverse dall’approccio di Hadoop. Ci si può chiedere se abbia senso mantenere due diverse soluzioni hardware/software per questi due tipi di carico di lavoro. In linea puramente teorica la risposta dovrebbe essere no, ma l’accelerazione tecnologica e la capacità d’integrazione dei player sta facendo propendere verso un’unica soluzione: una base Hadoop sulla quale montare un Sql engine.
Tra i primi produttori di database classici ad adottare Hadoop troviamo Teradata, Sap ed Hp. Ibm preferisce svilupparne una propria versione.
In quest’ottica è ottima la posizione di Sap Hana, che ripulisce e prepara i dati in un unico sistema Mpp integrato per Oltp e Dw. Anche se Sap investe direttamente in Hadoop, Hana è integrato con questo approccio.
Tra i tradizionali fornitori di Mpp che si sono adattati ad Hadoop c’è Pivotal (nata Greenplum), che ha migrato il suo Mpp su Hdfs e lo chiama Pivotal HD, Hadoop Distribution, 100% compatibile con l’implementazione classica.
 D’altronde Yarn, il resource negotiator di Hadoop, prevede la gestione di query classiche e del mondo Mpp. Tecnicamente, in questo modo si possono supportare richieste analitiche (scan su grandi det di dati, join ed aggregazioni). Impala, Hive/Tez ed altri sono già motori Sql con approccio Mpp montati su Hadoop, e Pivotal ha puntato forte in questa direzione.
D’altronde Yarn, il resource negotiator di Hadoop, prevede la gestione di query classiche e del mondo Mpp. Tecnicamente, in questo modo si possono supportare richieste analitiche (scan su grandi det di dati, join ed aggregazioni). Impala, Hive/Tez ed altri sono già motori Sql con approccio Mpp montati su Hadoop, e Pivotal ha puntato forte in questa direzione.
Oggi tra i principali fornitori di soluzioni e storage per i big data troviamo (in ordine alfabetico) Amazon, Cloudera, Google, Emc2, Hp, Ibm, NetApp, Oracle, Rackspace, Sap e Teradata. La segmentazione tra infrastruttura, software e servizi, secondo quanto proposto da gartner, porta ad analisi più puntuali ma certo più complesse, anche in virtù della coesistenza con le soluzioni legacy.
[…] La rinascita dei dati non strutturati Grandi nuvole sul lago delle cose Hadoop, il framework open source per i big data Dai Data Base ai Big Data […]