


Ogni giorno miliardi di persone utilizzano sulle piattaforme Meta esperienze basate sull’intelligenza artificiale, dalle raccomandazioni personalizzate agli assistenti AI. Allo stesso tempo, i modelli che definiranno la prossima era del computing stanno evolvendo a una velocità superiore rispetto a quella con cui l’hardware tradizionale riesce ad anticiparne le esigenze.
Servire modelli AI molto diversi tra loro su scala globale, mantenendo al tempo stesso i costi il più possibile contenuti, rappresenta una delle sfide infrastrutturali più complesse per l’intero settore tecnologico. La risposta di Meta consiste nello sviluppare una strategia hardware flessibile e iterativa, capace di offrire soluzioni efficaci oggi e migliorarle continuamente con l’evoluzione dei modelli.
Pur continuando a puntare su un portafoglio di soluzioni hardware diversificato — che include tecnologie interne ed esterne — la famiglia di chip Meta Training and Inference Accelerator (MTIA), sviluppata internamente in collaborazione con Broadcom, rappresenta un pilastro fondamentale della strategia infrastrutturale AI dell’azienda. I chip MTIA consentono infatti di alimentare in modo economicamente efficiente le esperienze AI utilizzate ogni giorno da miliardi di utenti.
L’evoluzione dei chip MTIA: dal ranking ai modelli generativi
Meta ha pubblicato diversi studi scientifici sulle prime due generazioni della famiglia MTIA, presentati alle conferenze ISCA 2023 e ISCA 2025. Questi lavori descrivono l’architettura dei chip MTIA 100 e MTIA 200 (precedentemente indicati come MTIA 1 e MTIA 2i).
Parallelamente alla ricerca, Meta ha già distribuito centinaia di migliaia di chip MTIA in ambienti di produzione, integrandoli in numerosi modelli utilizzati internamente e testandoli anche con modelli linguistici di grandi dimensioni come Llama.
Dopo le prime due generazioni, lo sviluppo della piattaforma è stato accelerato con quattro nuove generazioni successive: MTIA 300, MTIA 400, MTIA 450 e MTIA 500. Questi chip sono già in fase di distribuzione oppure verranno implementati tra il 2026 e il 2027.
L’evoluzione progressiva delle nuove generazioni amplia il raggio di applicazione dei chip MTIA: dai modelli di ranking e recommendation (R&R) fino al training e all’inferenza dei modelli di generative AI, con ottimizzazioni specifiche per ciascun tipo di workload.
Una strategia iterativa per stare al passo con l’evoluzione dei modelli AI
Lo sviluppo dei chip tradizionali segue cicli molto lunghi. Le architetture vengono progettate sulla base di carichi di lavoro previsti, ma quando l’hardware arriva in produzione — spesso due anni dopo — le esigenze dei modelli AI possono essere già cambiate radicalmente.
Per evitare questo disallineamento, Meta ha scelto un approccio iterativo: ogni nuova generazione MTIA si basa sulla precedente utilizzando un’architettura modulare basata su chiplet, integrando le più recenti tecnologie hardware e le informazioni più aggiornate sui workload AI.
Questo ciclo di sviluppo più rapido consente di mantenere l’hardware allineato con l’evoluzione dei modelli e di accelerare l’adozione delle nuove tecnologie.
La famiglia MTIA: quattro nuove generazioni

La famiglia MTIA oggi comprende quattro nuove generazioni principali.
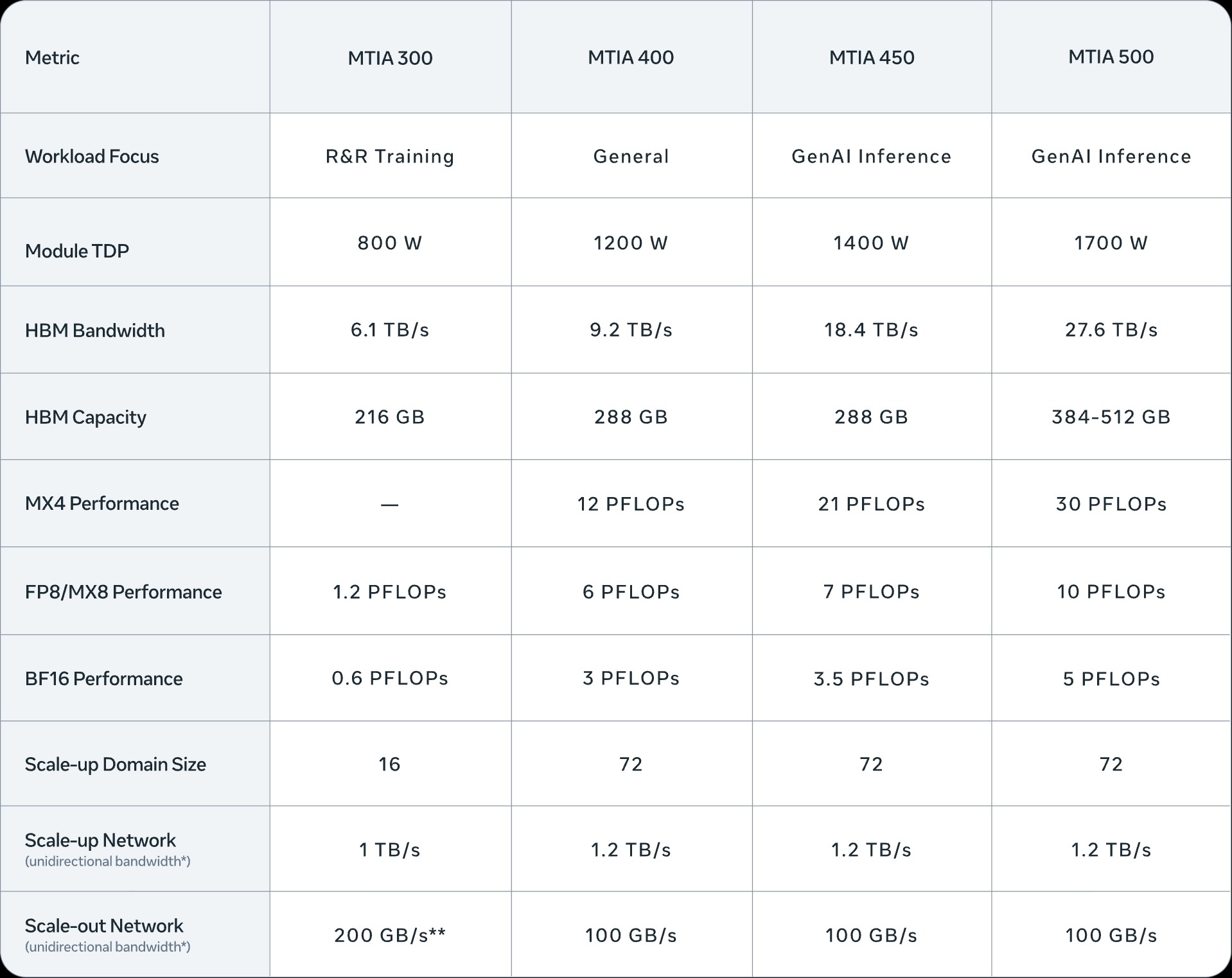
MTIA 300
È stato inizialmente progettato per i modelli di ranking e recommendation, che rappresentavano il principale carico di lavoro per Meta prima dell’esplosione della GenAI. Le sue componenti architetturali hanno costituito la base per i chip successivi ottimizzati per i modelli generativi. MTIA 300 è già in produzione per il training dei modelli R&R.
MTIA 400
Con l’espansione della generative AI, MTIA 300 è stato evoluto nel chip MTIA 400 per supportare meglio i workload GenAI mantenendo la compatibilità con i carichi R&R. Con un dominio di scale-up composto da 72 acceleratori, MTIA 400 offre prestazioni comparabili ai principali prodotti commerciali. Il chip è stato già testato nei laboratori Meta ed è in fase di implementazione nei data center.
MTIA 450
Per anticipare la crescita della domanda di inferenza GenAI, MTIA 400 è stato ulteriormente evoluto in MTIA 450 con ottimizzazioni specifiche per l’inferenza. Poiché la larghezza di banda della memoria HBM è uno dei fattori più critici per le prestazioni dell’inferenza generativa, MTIA 450 raddoppia la banda HBM rispetto alla generazione precedente. Introduce inoltre nuovi formati di dati a bassa precisione progettati specificamente per i workload di inferenza. La distribuzione su larga scala è prevista per l’inizio del 2027.
MTIA 500
La generazione successiva continua a concentrarsi sull’inferenza GenAI aumentando ulteriormente la banda HBM del 50% rispetto a MTIA 450 e introducendo ulteriori innovazioni nei formati a bassa precisione. La distribuzione su larga scala è prevista nel corso del 2027.
Nel passaggio da MTIA 300 a MTIA 500 la banda HBM aumenta di 4,5 volte, mentre la potenza di calcolo cresce di 25 volte, passando da MX8 a MX4.
MTIA 300: una base architetturale efficiente
MTIA 300 introduce diverse innovazioni rispetto alle generazioni precedenti, tra cui:
-
chiplet NIC integrati
-
motori di messaggistica dedicati per l’offloading delle comunicazioni collettive
-
capacità di near-memory compute per operazioni di riduzione.
Queste caratteristiche consentono comunicazioni a bassa latenza e alta banda tra i chip, creando le basi per i successivi chip GenAI.
L’architettura di MTIA 300 include:
-
un compute chiplet
-
due network chiplet
-
diversi stack di memoria HBM.
Ogni compute chiplet contiene una griglia di processing elements (PE), con alcuni elementi ridondanti per migliorare il rendimento produttivo.
Ogni PE include:
-
due core vettoriali RISC-V
-
un Dot Product Engine per la moltiplicazione matriciale
-
una Special Function Unit per attivazioni e operazioni element-wise
-
un Reduction Engine per accumulo e comunicazione inter-PE
-
un DMA engine per il trasferimento dei dati tra memoria locale e sistema.
MTIA 400: prestazioni comparabili alle GPU commerciali
MTIA 400 rappresenta un miglioramento significativo rispetto a MTIA 300.
Le prestazioni FP8 FLOPS sono quattro volte superiori, mentre la banda HBM cresce del 51%. Se MTIA 300 era stato progettato principalmente per l’efficienza economica, MTIA 400 introduce anche prestazioni grezze competitive con i prodotti commerciali di fascia alta.
Il chip integra due compute chiplet per raddoppiare la densità di calcolo e supporta versioni migliorate dei formati a bassa precisione MX8 e MX4, fondamentali per l’inferenza GenAI.
Un rack composto da 72 chip MTIA 400 collegati tramite backplane switch costituisce un unico dominio scale-up.
Il sistema rack-scale include inoltre dispositivi di networking dedicati e sistemi di raffreddamento air-assisted liquid cooling (AALC), che consentono la distribuzione anche nei data center legacy senza necessità di infrastrutture di raffreddamento a liquido complete.
MTIA 450: un salto di qualità per l’inferenza generativa
Per rispondere alla crescita dell’inferenza GenAI, MTIA 450 introduce miglioramenti in quattro aree principali:
- raddoppio della banda HBM per accelerare la fase di decoding
- aumento del 75% delle prestazioni MX4 FLOPS per l’elaborazione dei modelli Mixture-of-Experts
- accelerazione hardware per operazioni di attenzione e feed-forward network
- nuovi formati di dati a bassa precisione.
- MTIA 450 supera FP8 e MX8 offrendo sei volte le prestazioni MX4 FLOPS rispetto ai formati FP16/BF16, evidenziando l’importanza delle operazioni a bassa precisione nell’inferenza.
Il chip supporta inoltre calcoli misti a bassa precisione senza introdurre overhead software per la conversione dei tipi di dato.
MTIA 500: più prestazioni con meno risorse
Con la crescita dell’inferenza GenAI, MTIA 500 introduce ulteriori miglioramenti:
- banda HBM superiore del 50%
- capacità HBM fino all’80% più elevata
- 43% di incremento nelle MX4 FLOPS.
- Il chip utilizza una configurazione 2×2 di compute chiplet più piccoli, circondati da stack HBM e due network chiplet, oltre a un chiplet SoC che gestisce la connettività PCIe verso la CPU host e le NIC di scale-out.
La strategia MTIA: velocità, inferenza e standard aperti
La strategia di Meta nello sviluppo dei chip AI si basa su tre pilastri principali:
- sviluppo iterativo ad alta velocità
- priorità ai workload di inferenza
- integrazione nativa con standard software diffusi.
Meta ha sviluppato la capacità di introdurre un nuovo chip circa ogni sei mesi, consentendo di adattarsi rapidamente alle nuove tecniche AI e adottare le più recenti tecnologie hardware, tra cui nuovi nodi produttivi e memorie HBM.
Un ecosistema software nativo PyTorch
L’intero stack software MTIA è progettato con un approccio PyTorch-native, consentendo agli sviluppatori di lavorare in un ambiente familiare.
Il sistema supporta:
- PyTorch
- vLLM
- Triton
- standard hardware dell’Open Compute Project.
Il compilatore MTIA traduce i grafi dei modelli in codice altamente ottimizzato utilizzando tecnologie come Torch FX IR, TorchInductor, Triton, MLIR e LLVM.
Il runtime gestisce memoria, scheduling dei kernel e coordinamento tra dispositivi, utilizzando un driver user-space basato su Rust e firmware scritto in bare-metal Rust per garantire basse latenze e maggiore sicurezza.
Strumenti di produzione per centinaia di migliaia di chip
Per operare su larga scala, Meta ha sviluppato strumenti di monitoraggio, profilazione e debugging comparabili a quelli disponibili per le GPU commerciali, con funzionalità avanzate di osservabilità dell’intero stack — dal software al firmware fino all’hardware.
Il debugger consente controlli granulari fino al livello dei singoli processing element.
Verso la prossima generazione di infrastrutture AI
Le distribuzioni su larga scala dei chip MTIA hanno già dimostrato capacità elevate nei workload di ranking e recommendation. Le nuove generazioni — introdotte o previste tra il 2026 e il 2027 — puntano ora a spingere ulteriormente le prestazioni nell’inferenza generativa e a preparare il terreno per il training dei futuri modelli GenAI.
Grazie a un design modulare basato su chiplet e a un approccio di co-design tra hardware e software, la famiglia MTIA mira a offrire miglioramenti prestazionali rapidi e cumulativi mantenendo la compatibilità a livello di sistema.
L’obiettivo finale è fornire le infrastrutture necessarie per alimentare le esperienze AI più avanzate, oggi e nel futuro, per tutti gli utenti delle piattaforme Meta.






{kind=link}