

{kind=link}
Ciao a tutti, sono Vincenzo Lomonaco ricercatore all’Università di Pisa.
Nella puntata di oggi discuteremo di Phi-3, una nuova famiglia di Language Models rilasciati recentemente da Microsoft, incredibilmente piccoli ma potenti.
Ci chiederemo: quindi è possibile ottenere modelli competitivi con lo stato dell’arte, ma utilizzando solo una porzione molto ristretta di parametri? E se sì, come? Un gruppo di ricercatori presso Microsoft Research ha dimostrato recentemente che sì, è possibile pensare di progettare dei modelli computazionali del linguaggio di piccole dimensioni, invertendo il trend attuale, che vede una crescita significativa nelle dimensioni e la computazione richiesta generalmente da questi modelli.
In una puntata precedente abbiamo visto come è possibile, a partire da un large model, ridurre le dimensioni e le computazioni richieste per effettuare delle predizioni tramite tre tecniche principali: pruning, quantization e distillation.
Ma l’approccio introdotto dalla famiglia Phi-3 è particolarmente intrigante perché non solo riesce a produrre dei modelli molto piccoli con prestazioni superiori rispetto a modelli di dimensioni anche più grandi, ma perché anche la natura dei dati di addestramento è significativamente più contenuta, riducendo quindi massicciamente i tempi e i costi relativi alla loro creazione e al loro mantenimento.
Ecco, avere dei modelli più piccoli significa essere in grado di utilizzarli direttamente all’interno dei nostri dispositivi meno potenti e in un numero più ampio di servizi e applicazioni.
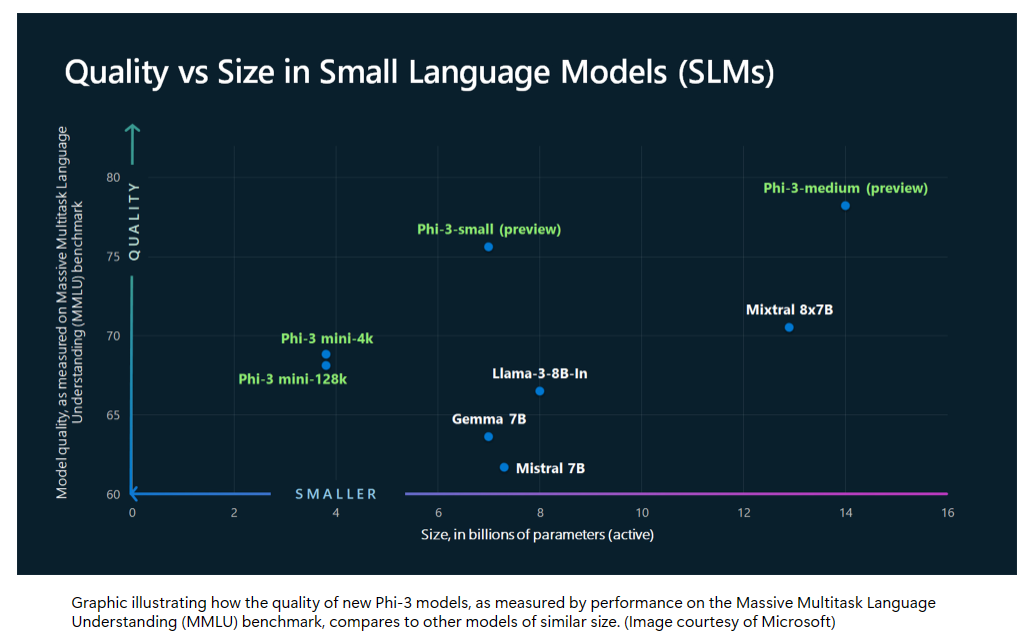
In questa immagine vediamo rappresentate le prestazioni in funzione della dimensione del modello di quattro soluzioni, che vediamo in verde, della famiglia Phi-3 in relazione ad altri modelli, in bianco, recentemente sviluppati ma di dimensioni maggiori.
Come vedete sull’asse X c’è la dimensione del modello in termini di miliardi di parametri, mentre sull’asse delle Y abbiamo la prestazione del modello rispetto al Massive Multitask Language Understanding (MMLU) benchmark, un modo molto comune per valutare le capacità generative di questi sistemi.
È possibile notare come i modelli della famiglia Phi-3 siano in genere più performanti a fronte di una ridotta dimensione.
Per esempio, Phi-3 Medium conta circa 7 miliardi di parametri, ma è circa il 15% più efficace di Mistral 7B, con 7 miliardi di parametri anch’esso rispetto al benchmark di riferimento.
In quest’altro grafico allarghiamo la nostra visuale per capire meglio quello che è lo stato dell’arte rispetto a questo task, a questo modo di valutare questi modelli in funzione del tempo.
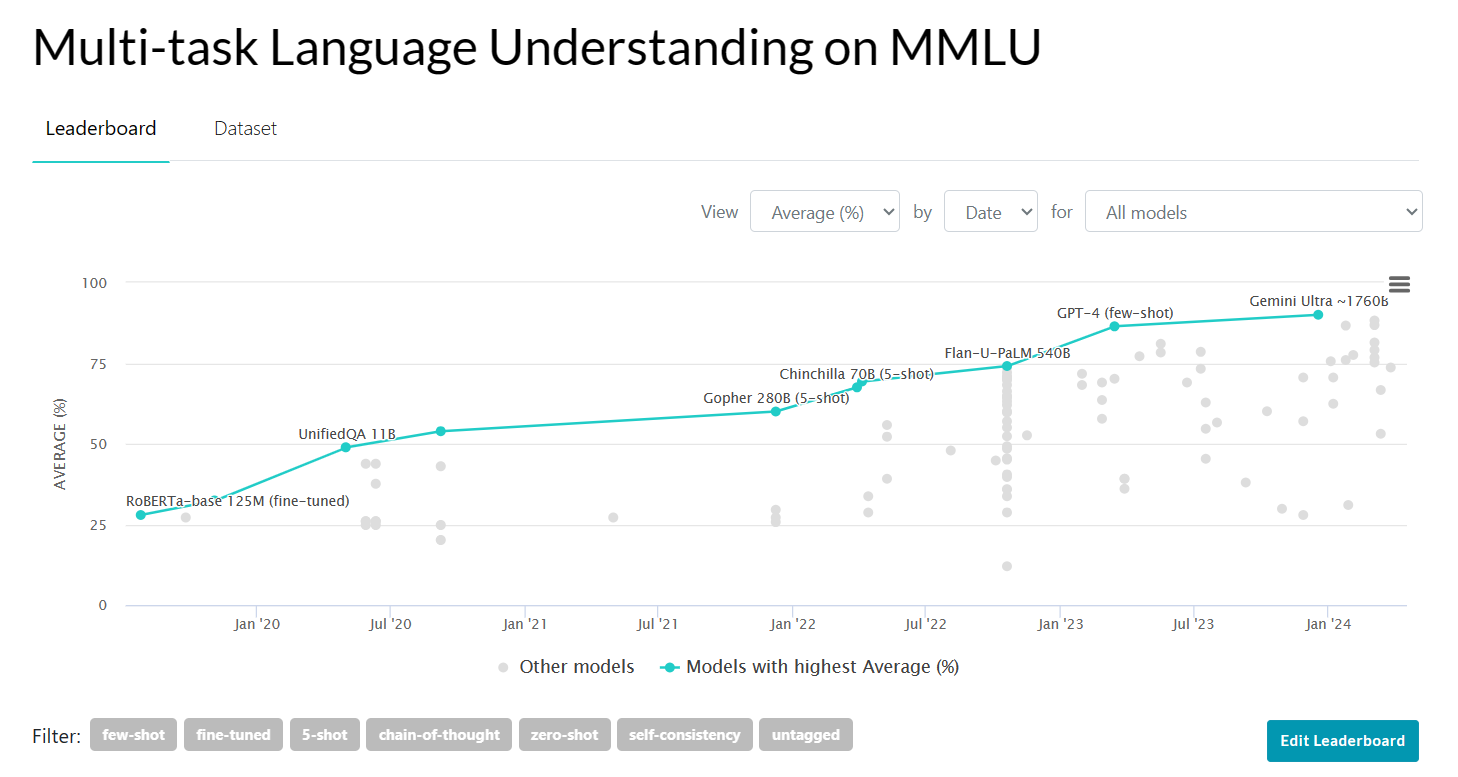
Infatti sull’asse X abbiamo il tempo dal giugno 2020 al gennaio 2024, mentre sull’asse delle Y sempre le performance calcolate sullo stesso benchmark.
Vediamo che tra i migliori modelli rientrano soluzioni ordini di magnitudo più grandi in termini di dimensioni.
Per esempio Gemini Ultra, che conta un numero di parametri di oltre 170 miliardi a fronte dei solo 7 di Phi-3 Mini, con un vantaggio di soli 15 punti percentuali.
È bene chiarire, quindi che non si tratta di modelli capaci di battere lo stato dell’arte e rappresentare una nuova frontiera in senso puramente di efficacia, ma che rappresentano un interessantissimo thread che mette al centro dello sviluppo di questi modelli fondazionali del linguaggio anche su dati di domini diversi, con un migliore trade off in termini di efficienza ed efficacia.
Ma cerchiamo di capire meglio come è stato possibile produrre questi nuovi modelli.
Fino ad oggi il modo standard per creare dei modelli del linguaggio naturale è stato utilizzare enormi quantità di dati provenienti dal web.
Si pensava quindi che questa fosse l’unica strada per soddisfare tutto questo appetito in termini di dati che questi modelli di grandissime dimensioni sembrano necessitare per imparare a comprendere tutte le sfumature del linguaggio in contesti diversi e per rispondere a quesiti di svariata natura.
Invece, la famiglia di modelli di Phi-3 si basa su un concetto molto diverso.
Invece di addestrare solo su dei dati grezzi raccolti sul web, perché non farlo su relativamente pochi dati ma di altissima qualità? E difatti i ricercatori di Microsoft circa un anno fa, un po’ prima, hanno deciso di partire con la prima generazione di questi modelli open, creando un dataset discreto a partire da sole 3.000 parole, tra cui un numero approssimativamente uguale di sostantivi, verbi e aggettivi.
Poi hanno successivamente chiesto un modello del linguaggio naturale più grande, un Large Language Model, di creare una semplice storia per bambini utilizzando un sostantivo, verbo e un aggettivo di questa lista e con un prompt che hanno somministrato al sistema particolarmente congegnato, hanno ripetuto milioni di volte questa procedura per generare milioni di piccole storie per bambini.
Il risultato è stato sorprendente a livello di qualità della creazione, quindi di frasi perfettamente corrette dal punto di vista grammaticale, portando Microsoft a investire maggiormente in questa direzione.
in questa idea fondamentale e innovativa, integrando a questo piccolo insieme di dati di addestramento ulteriori, sebbene limitati, documenti di alta qualità collezionati sempre dal web ma raffinati.
La via che ha portato ai risultati sorprendenti della terza generazione di cui stiamo parlando, è stato dunque un approccio molto sofisticato per la generazione sintetica di dati di alta qualità, a partire da un sottoinsieme accuratamente selezionato dal web.
E poi l’utilizzo fondamentale di un large language model di grandi dimensioni come GPT-4, oltre che un successivo processo di raffinamento per mitigare possibili vulnerabilità e migliorie e migliorare in genere la capacità conversazionale del modello di base.
Pensate che la versione quantizzata a quattro bit di Phi-3 MIDI, una versione particolare di cui abbiamo discusso, può essere utilizzata direttamente su un iPhone con un chip A16 Bionic, generando oltre dodici token, pezzi di parole, per secondo, il che consente un tempo di attesa più che ragionevole per la generazione delle risposte ai nostri quesiti.
Si prospetta dunque finalmente un futuro prossimo, dove avremo degli agenti conversazionali direttamente all’interno dei nostri dispositivi mobili, senza quindi mandare i nostri dati privati, le nostre domande in linguaggio naturale a servizi remoti che computano le risposte su dei server remoti, ma potendo effettivamente calcolare queste risposte, effettuare queste predizioni direttamente in locale.
In ultima analisi, questo risultato di ricerca, con delle ricadute immediate lato applicativo, risulta molto interessante per due ragioni fondamentali.
In primis suggerisce come sia possibile creare modelli fondazionali del linguaggio più piccoli, efficienti, ad appannaggio di tutti, di organizzazioni anche che non posseggono magari il calcolo e le risorse per lavorare su modelli di grandi dimensioni.
In secundis, suggerisce come sia possibile pensare a un agente artificiale che insegna in maniera efficiente ad un altro agente artificiale come parlare.
Un pensiero molto suggestivo.
In ultima analisi, anche un processo di distillazione della conoscenza che passa attraverso il linguaggio naturale, proprio come facciamo noi umani a scuola, per esempio.
Ciao! Alla prossima puntata di Le Voci dell’AI.