


Le applicazioni della cosiddetta Precision Agriculture possono assumere aspetti diversi fra loro, che ci portano a parlare di fog computing. Presupposto è che in comune c’è un flusso di informazioni che va dal campo, tipicamente dai sensori collocati nel terreno o da altri elementi che raccolgono dati ambientali, sino a un qualche sistema cloud. Questo li analizza in dettaglio, li confronta con informazioni raccolte altrove e indica eventuali azioni da compiere per ottimizzare le coltivazioni.
Anche in altre applicazioni del paradigma IoT questo modello ideale mostra un punto critico: la dipendenza dal cloud. È il cloud che raccoglie e memorizza le informazioni, è il cloud che le analizza e le contestualizza per dare indicazioni. D’altronde non è (ancora) possibile trasformare una fattoria in un centro anche piccolo per l’elaborazione dati e quando si sono immaginate le prime applicazioni di smart farming era difficile pensare a qualcosa di diverso da quanto abbiamo descritto.
Dalla nuvola alla nebbia
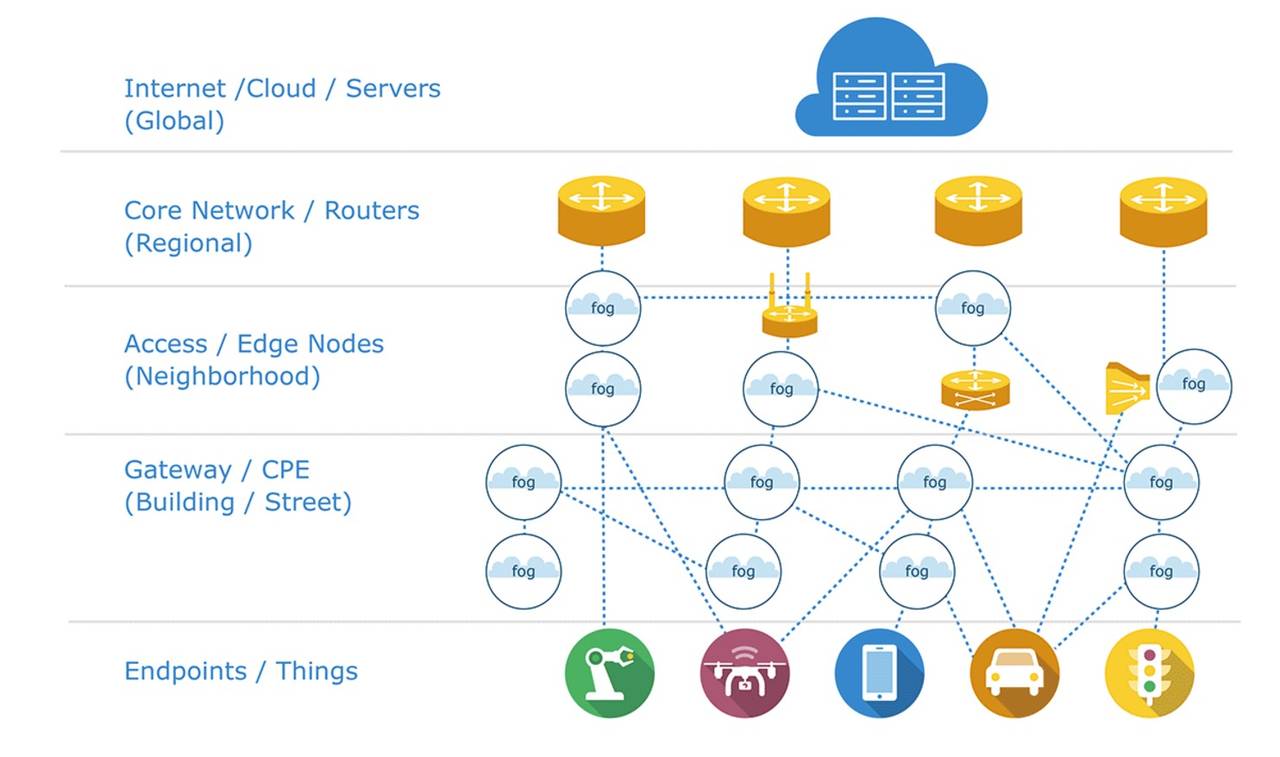
Ma la tecnologia evolve e anche gli elementi periferici di una rete IoT si sono fatti abbastanza potenti da poter prendere in carico parte dell’elaborazione dati che inizialmente si pensava passasse completamente in cloud. In questo modo si è affermato concettualmente il modello del fog computing, che fa da complemento al cloud computing: non c’è una nuvola centralizzata per la gestione delle informazioni ma una “nebbia” di componenti più semplici che, insieme, possono svolgere varie funzioni arrivando a un’architettura più agile.
La contrapposizione dei due termini sottolinea anche la diversa vicinanza dell’elaborazione al sistema che si monitora: una nuvola è in alto, lontana, la nebbia in fondo è una nuvola vicina, che tocca il terreno.
 Meglio spiegarsi con un esempio. Immaginiamo che un coltivatore distribuisca una rete di sensori in un campo per valutare la presenza nel terreno di vari composti chimici.
Meglio spiegarsi con un esempio. Immaginiamo che un coltivatore distribuisca una rete di sensori in un campo per valutare la presenza nel terreno di vari composti chimici.
Oggi questi sensori possono avere a bordo abbastanza memoria e intelligenza da non limitarsi a rilevare i parametri fisici e inviarli “a monte” verso il cloud. Possono ad esempio confrontare in autonomia i dati che raccolgono con un modello della distribuzione standard dei composti chimici nel terreno della zona dove si trovano.
In questo modo i sensori possono avere un ruolo decisionale direttamente sul posto: limitarsi a registrare i dati quando tutto è nella norma ma inviare un alert immediatamente quando i dati non corrispondono al modello previsto, magari anche derivando il perché dal modello con cui sono stati istruiti.
Modelli complementari
L’importanza concettuale del fog computing sta nel fatto che introduce un modello di elaborazione decentrata, a più livelli e idealmente aperto a tecnologie diverse che nella concezione iniziale delle applicazioni di smart farming e IoT in generale mancava.
O meglio, per essere più precisi: era contemplato per la parte di gestione e trasmissione delle informazioni ma solo marginalmente per la loro elaborazione. Possiamo pensare ad esempio a diversi sensori “smart” distribuiti per una certa area geografica e che comunicano usando le reti più indicate (cellulare, Wi-Fi, Sigfox…), inviando dati ed elaborazioni a nodi intermedi sempre più intelligenti sino alla piattaforma cloud vera e propria. C
iascuno di questi livelli può eseguire elaborazioni e trarre conclusioni, in modo da consentire una reazione (anche solo parziale, ma rapida) vicina al punto dove è più necessaria.
Fog e cloud computing non sono in contrapposizione ma agiscono in sinergia, puntando ciascuno a elementi specifici di forza. Chiaramente il fog computing ha il pregio della rapidità di reazione ma ha anche il limite di un ridotto “campo visivo”: i device periferici possono intervenire solo nell’ambito delle informazioni che hanno raccolto.
Al contrario il cloud ha tempi più lunghi ma il vantaggio di poter elaborare informazioni che provengono da un numero anche enorme di sensori e anche da fonti completamente diverse. Statistiche storiche, informazioni meteorologiche, dati degli altri coltivatori, algoritmi sofisticati di analisi e previsione: sono tutti elementi che possono trovarsi solo in cloud.
Uno scenario stimolante su cui però c’è ancora parecchio da fare. Il concetto del fog computing non è ancora chiarissimo agli utenti potenziali, che ad esempio spesso lo considerano un sinonimo dell’edge computing (la differenza principale sta nella visione a più livelli e nella gestione dinamica delle risorse del primo rispetto alla staticità del secondo).
Poi c’è il problema dell’interoperabilità, essenziale quando si vogliono “spalmare” i servizi prima concentrati in cloud lungo un continuum di dispositivi di vario genere.
Le aziende che puntano sul fog computing stanno lavorando alle architetture di riferimento che affrontano proprio questo aspetto, ci sono però ancora molte tessere del puzzle tecnologico che vanno combinate fra loro.









{kind=link}