


Sul proprio blog, Red Hat ha illustrato come sviluppatori, architetti software e team operativi possono ottimizzare applicazioni e servizi di edge computing con le tecnologie open source per ridurre al minimo i costi dell’infrastruttura di cloud computing.
Ci sono diverse tecnologie open source emergenti che possono dare un contributo significativo a questo obiettivo, suggerisce Red Hat, che ne ha evidenziato alcune.
Ad esempio, ottimizzare il codice Java utilizzando Quarkus (un framework Java open source e nativo di Kubernetes) può aiutare a ridurre i requisiti di memoria di runtime di un ordine di grandezza, facendo scendere i tempi di avvio iniziale da secondi a millisecondi.
Bassi tempi di avvio riducono l’utilizzo dell’infrastruttura rendendo pratico scalare in modo significativo quando un’applicazione o un processo è inattivo. Tempi di avvio più lunghi richiedono che un’applicazione o un processo rimanga continuamente “hot”, eseguendo in-memory e usando risorse anche quando è inattivo.
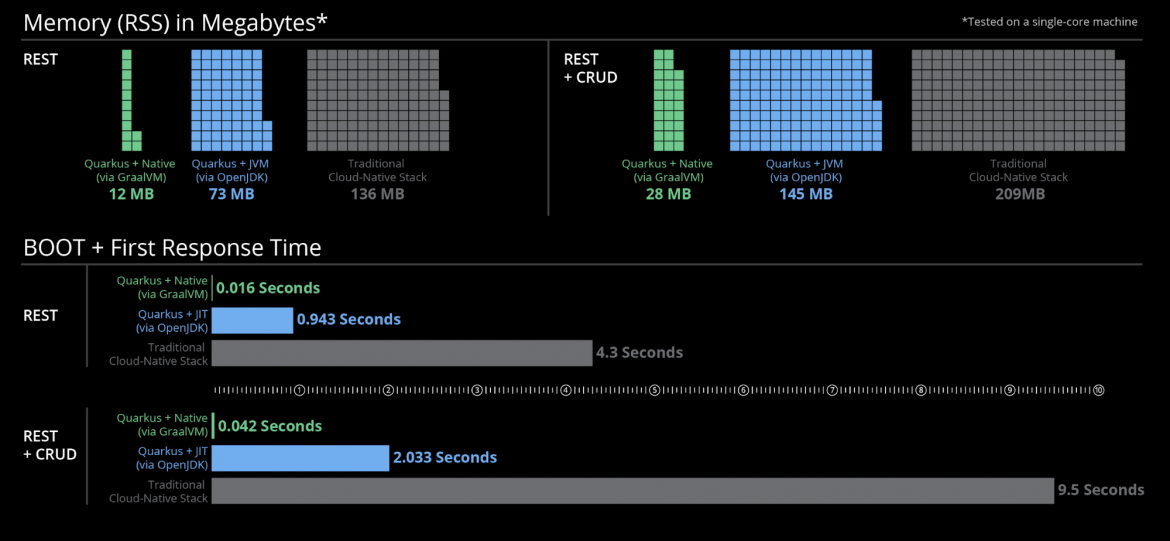
Il report IDC Quarkus Lab Validation offre un riepilogo dei risparmi sui costi e altri vantaggi chiave associati all’adozione di Quarkus, rispetto a un altro framework Java. Lo studio rileva che Quarkus può risparmiare fino al 64% di utilizzo della memoria cloud quando viene eseguito in modalità nativa.
Ottimizzare le applicazioni per minimizzare l’uso dell’infrastruttura diventa ancora più importante quando ci si approccia all’edge computing, ha evidenziato Red Hat.
Nel modello tradizionale di cloud computing, il cloud è un oceano di migliaia di server concentrati in poche location, che fornisce una capacità di calcolo quasi infinita per un’applicazione. Se l’utilizzo di una qualsiasi di queste posizioni centralizzate si avvicina alla sua capacità, è relativamente economico installare ulteriori server nel sito.
Il modello di edge computing capovolge il tradizionale modello del cloud computing. Piuttosto che migliaia di server in poche posizioni centrali, l’edge computing implica alcuni server in ciascuna delle migliaia di posizioni periferiche della rete. Se l’utilizzo di una di queste migliaia di siti periferici si avvicina alla capacità, visitare fisicamente il sito per aggiungere qualche altro server non è economico. Inoltre, lo spazio, l’energia e le restrizioni di raffreddamento in molte sedi periferiche, in particolare quelle delle telecomunicazioni, possono rendere impossibile l’aggiunta di capacità.
Fortunatamente, mette però in evidenza Red Hat, ci sono ulteriori tecnologie open source che stanno emergendo e che possono consentire un utilizzo dell’infrastruttura edge eccezionalmente ben ottimizzato.
Container contro virtual machine
Per un certo numero di anni la macchina virtuale (VM) è stata la tecnologia principale utilizzata per migliorare l’utilizzo dei server. La VM ha ottenuto questo risultato separando il server fisico in più server virtuali, permettendo così un utilizzo più efficiente di un singolo server fisico. Tuttavia, la VM è ora sfidata da una tecnologia che offre non solo un’ottimizzazione superiore del server, ma anche molti altri vantaggi: i container.
A differenza delle VM, le applicazioni nei container condividono il sistema operativo (OS) del server con altre applicazioni che sono ciascuna isolata nel proprio container. La condivisione del sistema operativo elimina l’overhead di utilizzo delle risorse della VM e fornisce un’esposizione più diretta dell’hardware del server sottostante all’applicazione.
Inoltre, un nuovo container può essere istanziato molto più rapidamente di una VM. La superiore efficienza di utilizzo dell’infrastruttura del container sta contribuendo alla sua rapida adozione. Le applicazioni di edge computing, per le quali l’efficienza è fondamentale, possono evitare le VM in favore dei container.
Serverless (Knative) ed edge computing
Un’altra innovazione significativa che consente un’efficiente ottimizzazione dell’infrastruttura cloud è la tecnologia serverless, come esemplificato dal progetto open source Knative. Ci sono ancora server nell’approccio serverless, ma un cloud provider o una piattaforma gestisce il lavoro di routine di approvvigionamento, manutenzione e scalabilità dell’infrastruttura server. Il metodo serverless permette agli sviluppatori di impacchettare semplicemente il loro codice in container per il deployment, senza dover gestire i server o preoccuparsi del capacity scaling.
Le applicazioni serverless sono di natura “event driven”, il che significa che seguono un modello molto semplice: si verifica un evento, che innesca un’applicazione da eseguire. Quando si esegue su Kubernetes, un evento innesca uno o più container associati da istanziare. L’applicazione che risiede nel container elabora quindi l’evento. Con serverless, Kubernetes scala il numero di container fino a zero una volta che l’applicazione attivata è inattiva per un tempo sufficiente.
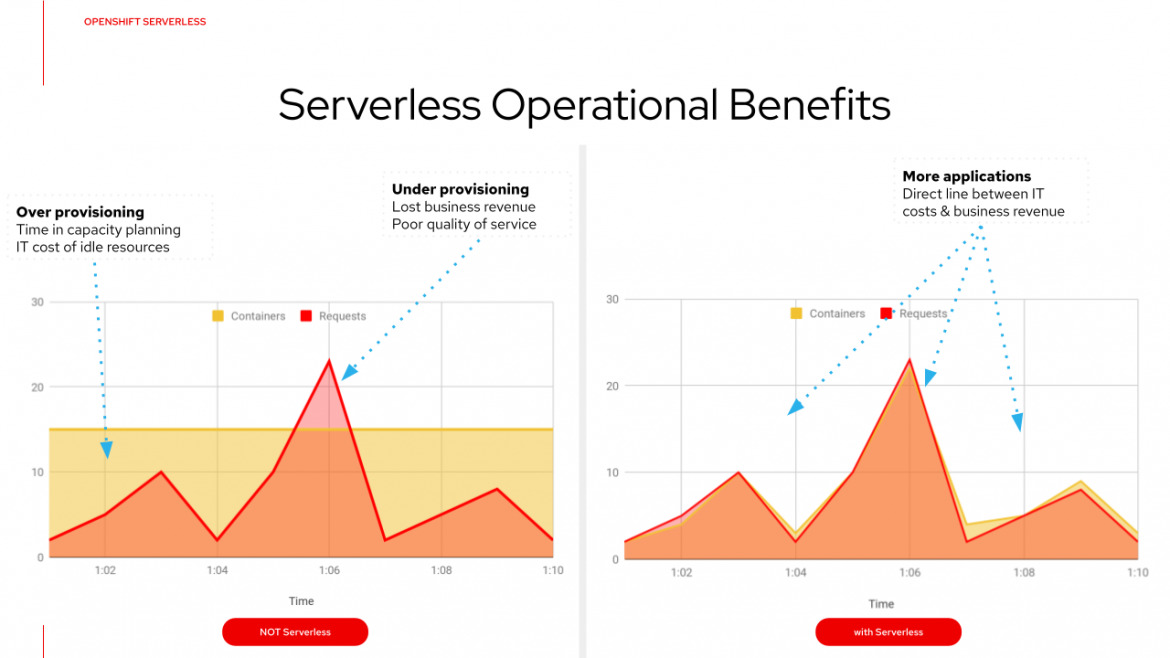
Dal punto di vista dell’utilizzo dell’infrastruttura, l’aspetto più importante del serverless è che permette ad un’applicazione di scalare fino a zero, utilizzando essenzialmente nessuna infrastruttura quando è inattiva.
Le applicazioni serverless sono distribuite in container che si lanciano quasi istantaneamente quando vengono chiamati, mentre le VM impiegano diversi minuti per essere lanciate, rendendole inadatte alle applicazioni serverless. Le offerte serverless dei fornitori di cloud pubblico sono di solito misurate on-demand attraverso un modello di esecuzione guidato dagli eventi. Di conseguenza, quando un’applicazione serverless è inattiva, non costa nulla.
Le applicazioni moderne sono sviluppate con ogni processo applicativo o microservizio distribuito in container, ognuno dei quali può essere scalato indipendentemente in alto o in basso secondo necessità. Questo scaling indipendente e a grana fine di un singolo processo applicativo porta anche all’ottimizzazione dell’utilizzo dell’infrastruttura e dei costi.
Il deployment serverless dei processi applicativi containerizzati permette ad ogni processo applicativo di consumare solo le minime risorse cloud richieste in qualsiasi momento, raggiungendo il massimo dell’efficienza.
Knative è un’implementazione open source del modello serverless. Knative permette alle applicazioni serverless di essere distribuite ed eseguite su qualsiasi piattaforma Kubernetes, compresa la Red Hat OpenShift Container Platform. Red Hat OpenShift Serverless è la distribuzione supportata da Red Hat di Knative su OpenShift. Fornisce una piattaforma serverless di livello enterprise che porta la portabilità e la coerenza attraverso ambienti ibridi e multi-cloud.
L’analisi di Red Hat si estende poi ad altre tecnologie che aiutano a ottimizzare l’infrastruttura di edge computing, tra cui Virtual Application Networks (Skupper).









{kind=link}