

Un salto nel calcolo parallelo per capire meglio le architetture del chip che viene visto dal sistema operativo come un doppio processore
dicembre 2002 Il calcolo parallelo, chiamato TLP dalle
iniziali di Thread Level Parallelism, è un sistema che permette di aumentare
in modo consistente le prestazioni senza ricorrere a stravolgimenti dell’architettura
del processore.
Gli attuali sistemi operativi e i software sono costituiti da istruzioni
indipendenti (thread) eseguibili in parallelo. I thread possono provenire
da una sola applicazione, da due applicazioni in esecuzione contemporaneamente
oppure dalle varie routine di controllo del sistema operativo che girano in background.
Questa particolarità è alla base dei sistemi multiprocessore:
sistemi con due o più processori che eseguono in parallelo diversi thread
aumentando di conseguenza le prestazioni complessive del sistema. Tuttavia si
tratta di sistemi costosi e nonostante le configurazioni multiprocessore esistano
da anni, il loro utilizzo è limitato ai server e in quei settori dove
si ha necessità di un’elevata potenza di elaborazione.
Diverse tecniche sono state sviluppate per approfittare dei vantaggi
apportati dal calcolo parallelo, una di queste è di fare eseguire
alla CPU thread multipli, generati da diverse applicazioni, passando in sequenza
dall’uno all’altro. Nel Time-slice multithreading
il processore assegna al thread una determinata e fissa porzione di tempo, trascorsa
la quale la CPU passa al thread successivo. Nello Switch-on-event multithreading
il passaggio al thread successivo avviene quando la CPU nota un tempo eccessivo
nell’esecuzione del thread, per esempio quando un dato necessario per
l’esecuzione non si trova nella cache L1 e il processore la deve recuperare
dalla lenta memoria di sistema. Entrambi i metodi hanno comunque un’efficacia
limitata perché risentono degli inconvenienti che si verificano spesso
nell’esecuzione delle istruzioni. Una predizione di salto a un’altra
istruzione errata, il dover attendere un risultato che arriva dall’esecuzione
di un altro thread, sono alcune delle condizioni che vanificano il guadagno
del calcolo parallelo.
Il multithread simultaneo, la tecnica su cui è basata
l’Hyper-Threading di Intel, segue un altro approccio. Consente di eseguire
in contemporanea due thread in un singolo processore senza dover saltare da
uno all’altro come nelle due precedenti tecniche descritte. L’Hyper-Threading
fa credere al sistema operativo e ai software che vi siano due processori mentre
in realtà fisicamente è uno solo. I due processori, denominati
processori logici, condividono diverse parti del chip: il motore d’esecuzione
delle istruzioni, le due cache L1 e L2 , l’interfaccia del bus di sistema
e il firmware, come si vede nella figura sotto.
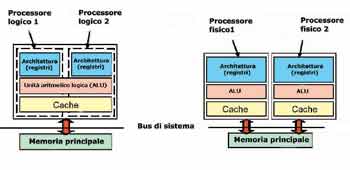
Le parti del chip replicate
per creare i due processori logici sono i vari registri di utilizzo generale,
i registri di controllo e di stato del PC e i registri dell’APIC (Advanced
Programmable Interrupt Control). L’avere due processori attivi minimizza
la perdita di prestazioni in caso di stallo di uno dei due. Inoltre l’architettura
di sistema controlla e cerca sempre di mandare in esecuzione per primi i thread
che hanno tutte le dipendenze soddisfatte e risorse di esecuzione disponibili.
L’Hyper-Threading necessita tuttavia di una certa cooperazione
da parte del sistema operativo per ottimizzare al meglio lo sfruttamento
delle risorse. Per esempio si potrebbe avere una condizione in cui un processore
si trova ad eseguire sempre lo stesso thread (loop) perché ha bisogno
dei dati risultato di un altro thread.
Il comando PAUSE interrompe il loop lasciando libero il processore
per l’esecuzione di altri thread, quando il risultato è disponibile
riprende l’esecuzione del thread interrotto. Il comando HALT
invece disabilita uno dei due processori logici.
Esistono due diversi modi di funzionamento, single-task nelle due modalità
ST0 e ST1, e multi-task, entrambi attivati dal comando HALT. Se un thread impegna
solo il processore logico “0”, il comando HALT disattiva “1”,
viceversa se ad essere impegnato è solo “1”.
Le risorse condivise sono riconfigurate e assegnate tutte al processore logico
attivo. Il ritorno al modo multi-task è eseguito inviando un ulteriore
comando HALT che riattiva il processore non utilizzato riassegna le risorse
equamente. Con questo metodo non si penalizzano le prestazioni quando in esecuzione
vi è un solo singolo thread, in quanto il sistema operativo esegue sempre
delle operazioni di verifica a vuoto sul processore inutilizzato. L’implementazione
della tecnologia Hyper-Threading comporta un aumento della dimensione del chip
del 5 per cento.





