


L’intelligenza artificiale è ormai entrata stabilmente nell’agenda strategica delle grandi imprese europee, ma la rapidità con cui il mercato sta incorporando modelli generativi, analytics avanzati e automazione intelligente nei processi operativi si scontra con una realtà molto meno lineare: infrastrutture dati frammentate, governance incompleta, qualità informativa disomogenea e architetture costruite nel tempo per stratificazioni successive. È in questo squilibrio tra ambizione e maturità tecnologica che Cloudera individua oggi uno dei principali fattori di rischio per la trasformazione AI delle aziende, come emerge da The Data Readiness Index 2026, una ricerca condotta su circa trecento grandi organizzazioni europee, di cui cinquantacinque italiane, commentata da Yari Franzini, Group Vice President Southern Europe, e Fabio Pascali, Regional Vice President Italy, Greece & Cyprus, durante un incontro con la stampa di settore.
La fotografia restituita dallo studio è quella di un mercato in piena accelerazione, ma ancora privo di molte delle fondamenta necessarie per sostenere un percorso di industrializzazione reale. Governance del dato, integrazione delle fonti informative, qualità dei dataset, controllo dei costi, sicurezza, compliance normativa e capacità di costruire una visione organizzativa coerente evolvono infatti con una velocità nettamente inferiore rispetto all’adozione degli strumenti di intelligenza artificiale.
Pascali definisce questo scenario un vero e proprio “paradosso”. Da una parte il management delle aziende europee attribuisce all’AI un valore strategico ormai indiscusso: oltre il 90% delle organizzazioni coinvolte nella ricerca considera prioritario investire in intelligenza artificiale, sviluppare nuovi casi d’uso e utilizzare modelli generativi e analytics avanzati per accelerare l’innovazione e aumentare la competitività. Dall’altra, proprio le componenti che dovrebbero sostenere questa trasformazione – qualità del dato, integrazione, governance e processi organizzativi – restano largamente incomplete.

“C’è una percezione molto elevata dell’importanza dell’AI, ma il problema è il «come». Tutto quello che sta in mezzo tra l’idea e la realizzazione – governance, controllo del dato, qualità del dato, organizzazione e processi – è ancora fortemente carente”, sintetizza Pascali.
Italia in ritardo rispetto a Francia e Germania
Il confronto europeo evidenzia un divario particolarmente marcato per il mercato italiano. Anche i Paesi più maturi non possono essere considerati in una condizione ideale, ma Francia e Germania mostrano livelli di preparazione più avanzati: la governance completa dei dati riguarda circa il 30% delle aziende francesi e si avvicina al 40% in Germania, mentre l’Italia resta più indietro.

“Stiamo parlando di poco meno di un terzo del mercato europeo realmente maturo dal punto di vista della governance”. Il dato assume un peso ancora maggiore se letto alla luce dell’AI Act europeo, perché molte organizzazioni stanno accelerando sugli use case di intelligenza artificiale senza avere ancora costruito i meccanismi necessari per garantire conformità normativa, tracciabilità, controllo del ciclo di vita del dato e capacità di audit.
Il ritardo italiano non riguarda soltanto la compliance. Indica una debolezza più strutturale nella capacità di trasformare i dati in un’infrastruttura aziendale condivisa, governata e riutilizzabile. L’entusiasmo per l’AI è elevato, ma la distanza tra intenzione strategica e capacità esecutiva resta ampia. La contraddizione emerge con particolare evidenza osservando altri indicatori della ricerca. Se il 91% delle aziende italiane ritiene che il top management comprenda l’importanza delle infrastrutture necessarie per scalare l’intelligenza artificiale e il 56% dichiara di disporre di una strategia dati chiaramente collegata agli obiettivi di business, soltanto il 2% afferma di operare in un ambiente completamente governato. Ancora più significativo è il fatto che il 91% degli intervistati dichiari di avere un elevato livello di fiducia nei propri dati, una percezione che appare difficilmente conciliabile con le criticità evidenziate sul fronte dell’integrazione, dell’accessibilità e della governance.
I silos come eredità della crescita “best of breed”
Una delle cause principali di questa situazione è il modo in cui le aziende hanno costruito nel tempo il proprio ecosistema IT. Molte organizzazioni sono cresciute adottando piattaforme differenti, servizi SaaS distribuiti, cloud multipli e strumenti verticali specializzati, spesso secondo una logica “best of breed” che ha privilegiato l’efficacia puntuale delle singole soluzioni rispetto alla coerenza complessiva dell’architettura dati.
“Siamo cresciuti in un’ottica best of breed e abbiamo aggiunto nel tempo silos software, silos di dati e anche fenomeni di shadow AI. Il risultato è che continuiamo a ragionare per compartimenti separati”, afferma Franzini.
Il problema non è soltanto la presenza di tecnologie diverse. È il costo di integrazione che queste architetture generano quando l’azienda prova a costruire una visione unificata del dato. Molti servizi cloud e molti strumenti AI sono stati introdotti in modo tattico, spesso direttamente dalle linee di business, senza una strategia complessiva di governance. La dinamica ricorda la prima grande espansione del cloud computing: l’adozione rapida ha preceduto la costruzione di regole, processi e architetture capaci di renderla sostenibile.
Le conseguenze di questa frammentazione sono chiaramente percepite dalle aziende italiane. Il 27% degli intervistati identifica nella limitata visibilità sul patrimonio informativo una delle principali barriere all’utilizzo efficace dei dati, mentre il 18% indica esplicitamente i silos come un ostacolo alla collaborazione e ai processi decisionali. Non sorprende quindi che il 71% delle organizzazioni dichiari che iniziative operative e progetti aziendali vengano almeno occasionalmente rallentati da problemi prestazionali dell’infrastruttura dati, segnale di come la complessità architetturale stia producendo effetti concreti anche sull’esecuzione delle attività quotidiane.
Oggi le organizzazioni si trovano con dati distribuiti tra hyperscaler diversi, applicazioni SaaS, ambienti on premise, sistemi legacy e nuove piattaforme AI che raramente dialogano tra loro in modo coerente. L’intelligenza artificiale, costruita sopra questo paesaggio frammentato, rischia quindi di amplificare problemi già esistenti anziché risolverli.
Solo il 16% delle aziende italiane dichiara dati completamente integrati
La dimensione del problema emerge con chiarezza dai numeri della ricerca. In Italia soltanto il 16% delle aziende dichiara di avere una completa integrazione dei dati aziendali. La percentuale è bassa, ma potrebbe persino restituire un’immagine ottimistica, perché molte organizzazioni non hanno ancora piena consapevolezza della complessità reale dei propri ambienti informativi e avere una completa integrazione è estremamente difficile quando si hanno decine o centinaia di sorgenti differenti.
Le criticità non riguardano soltanto l’integrazione tecnica. Solo il 26% delle aziende italiane afferma di avere accesso immediato ai dati in qualunque formato, mentre appena il 18% dichiara di aver implementato pienamente modelli self-service basati su data product condivisi. Il dato resta quindi spesso disponibile solo a porzioni dell’organizzazione, oppure accessibile attraverso processi lenti, manuali e dipendenti da singoli team.
Il quadro evidenzia inoltre una distanza significativa tra visibilità e accessibilità. Circa il 40% delle organizzazioni sostiene di avere piena visibilità sul patrimonio informativo aziendale, ma soltanto il 26% afferma di poter accedere in qualsiasi momento al 100% dei dati necessari indipendentemente dal formato o dalla collocazione. Sapere dove si trovano le informazioni non coincide necessariamente con la capacità di utilizzarle in modo efficace e continuativo.
Questa frammentazione spiega perché molti progetti AI continuino a produrre risultati limitati. L’intelligenza artificiale, soprattutto quella generativa, ha bisogno di accedere rapidamente a grandi quantità di informazioni affidabili, aggiornate e coerenti. Se il patrimonio informativo rimane distribuito in silos non interoperabili, i modelli finiscono inevitabilmente per lavorare su viste parziali del business.
Come osserva Pascali, “dato è potere” continua a essere una convinzione diffusa in molte organizzazioni, con la conseguenza che la condivisione delle informazioni tra funzioni e linee di business rimane spesso problematica.
Dal proof of concept alla produzione: il rischio del “POCificio”
La proliferazione di sperimentazioni AI non coincide ancora con una reale capacità di industrializzazione. Franzini richiama l’espressione usata da un cliente, POCificio, per descrivere aziende impegnate a produrre continuamente proof of concept senza riuscire a trasformarli in sistemi produttivi integrati nei processi, governati e sostenibili nel tempo.

Molti progetti partono rapidamente, sfruttando modelli disponibili nei cloud pubblici o servizi AI già pronti all’uso. L’apparente semplicità iniziale, però, nasconde problemi che emergono nel momento in cui occorre scalare. “Molti clienti sviluppano PoC ma non considerano tutti gli aspetti non funzionali necessari per industrializzarli: governance, compliance, sicurezza, controllo dei costi e scalabilità”, sottolinea Franzini.
Il primo ostacolo al ritorno sull’investimento continua a essere il dato. La ricerca consente di individuare con maggiore precisione le cause che impediscono ai progetti AI di generare il valore atteso. Il 24% delle aziende italiane attribuisce risultati inferiori alle aspettative a problemi di qualità del dato, mentre un ulteriore 16% indica nella debole integrazione dei modelli all’interno dei workflow operativi uno dei principali fattori di insuccesso. L’ostacolo principale, in altre parole, non sembra essere la capacità dell’algoritmo di elaborare informazioni, ma la qualità, la disponibilità e l’integrazione delle informazioni che gli vengono fornite.
Il secondo ostacolo è rappresentato dai silos. Se l’AI lavora solo su una porzione limitata del patrimonio informativo aziendale, i modelli sviluppano inevitabilmente una conoscenza parziale del business. “Molte organizzazioni costruiscono modelli separati per HR, produzione o finance, ma in questo modo non ottengono economie di scala e non massimizzano il ritorno dell’investimento”, osserva Pascali.
Sicurezza e compliance: il rischio di esportare dati sensibili
La sicurezza del dato utilizzato per training, fine tuning e inferenza rappresenta un ulteriore punto di frizione. Molte organizzazioni affrontano l’intelligenza artificiale nel modo più semplice e immediato, utilizzando servizi cloud esterni già pronti all’uso. È una scelta comprensibile nella fase di sperimentazione, ma diventa più problematica quando in gioco entrano dati sensibili, informazioni regolamentate o processi mission critical.
“Molte aziende fanno fine tuning esportando dati sensibili e utilizzano informazioni critiche in input ai modelli”, osserva Pascali. Il problema non riguarda soltanto la sicurezza tecnica, ma la capacità di sapere dove si trova il dato, chi lo utilizza, quali trasformazioni subisce, con quali policy viene protetto e come può essere dimostrata la conformità rispetto a normative interne, settoriali o europee.
La governance, in questa prospettiva, non è un elemento di rallentamento ma una condizione abilitante. “La governance non deve essere un freno a mano tirato, ma una frenata assistita che permetta di innovare rapidamente mantenendo il controllo”, osserva Franzini. Il punto è incorporarla nell’architettura fin dall’inizio, evitando di aggiungerla a posteriori quando il progetto è già cresciuto in modo disordinato.
Il nodo economico dell’AI generativa
La sostenibilità economica sta diventando uno dei temi più delicati nella fase di maturazione dell’AI generativa. Molte aziende hanno iniziato utilizzando modelli cloud basati su consumo a token, una formula efficace per avviare rapidamente sperimentazioni e prototipi, ma meno prevedibile quando il numero di utenti, interrogazioni e workload cresce in modo significativo.
“Quando si scala, i costi esplodono”. In alcune organizzazioni l’utilizzo dell’AI viene già regolato attraverso budget rigidi di token assegnati ai dipendenti o ai team, con il rischio di trasformare una tecnologia pensata per aumentare produttività e capacità decisionale in una risorsa contingentata. In altri casi emergono dinamiche ancora più paradossali, con l’adozione dell’AI usata come leva per giustificare riduzioni di personale non tanto perché la tecnologia abbia realmente sostituito il lavoro umano, quanto per compensare l’aumento dei costi generati dalle piattaforme generative.
Questo scenario spinge verso architetture ibride e private AI. L’idea è utilizzare il cloud pubblico nelle fasi iniziali, sfruttandone rapidità e flessibilità, per poi riportare i workload più strategici all’interno del data center aziendale o di ambienti privati controllati. In questo passaggio cambia anche il modello economico: invece di pagare a consumo per token o inferenze, l’azienda ragiona su infrastrutture GPU dedicate, principalmente Nvidia, con costi più lineari e prevedibili.
Sovereign cloud, repatriation e private AI
Il tema della sovranità digitale sta assumendo un peso crescente nelle strategie europee. Francia e Germania stanno accelerando verso modelli sovereign cloud, mentre l’Italia appare ancora più prudente e meno strutturata. Nel mercato francese esiste già un ecosistema di provider sovereign più maturo, anche per effetto di un orientamento politico e industriale più deciso; nel contesto italiano, invece, il fenomeno procede con maggiore lentezza.
La questione geopolitica rende il tema ancora più sensibile. Le aziende iniziano a chiedersi quanto sia semplice uscire da determinate piattaforme cloud, migrare dati e workload verso ambienti alternativi o gestire un rialzo improvviso dei costi. “I clienti stanno riflettendo molto sul tema della exit strategy”.
Più le aziende salgono nella pila tecnologica degli hyperscaler, più aumenta il rischio di lock-in. La risposta proposta da Cloudera passa da tecnologie aperte come Apache Iceberg e da un’architettura capace di garantire portabilità del dato tra cloud pubblici, ambienti privati e infrastrutture on premise. “Iceberg è un po’ l’esperanto del mondo dei dati”, dice Pascali, spiegando come l’obiettivo sia ridurre la dipendenza dai singoli ambienti e mantenere libertà di movimento tra architetture differenti.
La strategia “Data Anywhere” e “AI Anywhere” nasce da questa impostazione: dati, modelli e workload devono poter essere eseguiti dove l’azienda ritiene più opportuno, senza rinunciare a governance, sicurezza, compliance e controllo dei costi.
Pubblica amministrazione, sanità e finance guidano la domanda di private AI
I settori più sensibili alla private AI sono oggi pubblica amministrazione, healthcare e finance. La pubblica amministrazione centrale italiana viene indicata come uno dei mercati a più alta crescita per Cloudera, anche perché molte organizzazioni pubbliche partono da una forte tradizione on premise e da una sensibilità già elevata rispetto alla sovranità del dato.
Molti enti hanno iniziato con sperimentazioni in cloud, spesso anonimizzando i dati, ma stanno progressivamente comprendendo che l’adozione su larga scala dell’AI richiede un controllo molto più stretto delle informazioni. “Quando si fa inferenza si devono inevitabilmente utilizzare dati sensibili. E allora diventa fondamentale avere una gestione sicura e controllata”, osserva Pascali.
Una dinamica analoga emerge nella sanità privata e pubblica, dove l’utilizzo di agenti, chatbot o sistemi di supporto decisionale implica il trattamento di informazioni personali e cliniche. Nel finance, invece, molte istituzioni hanno già lavorato sulla governance del dato, ma il tema del costo delle piattaforme AI diventa sempre più rilevante a causa dei volumi elevati di transazioni, documenti, interazioni e processi da automatizzare.
Il caso Accenture: AI generativa privata per la gestione dei ricorsi
La strategia private AI assume concretezza nei progetti sviluppati con l’ecosistema dei partner. Il GenAI Studio realizzato con Accenture presso Palazzo Marignoli, a Roma, rappresenta uno degli esempi più avanzati di questa impostazione, perché mostra come un modello generativo possa essere importato, addestrato e utilizzato all’interno di un perimetro controllato.
Uno dei casi d’uso riguarda la gestione dei ricorsi amministrativi. Cloudera e Accenture hanno utilizzato un modello open source disponibile su Hugging Face, eseguendo fine tuning su normative e regolamenti specifici. Il sistema supporta gli operatori nella costruzione dei ricorsi, accelerando il processo e migliorando la completezza delle informazioni utilizzate. “L’obiettivo non è sostituire l’umano, ma supportarlo”.
Il valore del caso d’uso non sta soltanto nell’applicazione specifica, ma nel modello architetturale sottostante: un sistema generativo può lavorare su dati sensibili senza uscire dal perimetro di sicurezza dell’organizzazione, mantenendo controllo su input, output, policy, modelli e processi di validazione.
Gli agenti AI amplificano problemi non ancora risolti
L’AI agentica rappresenta una delle evoluzioni più discusse del mercato, ma il salto dagli assistenti generativi agli agenti autonomi rischia di amplificare problemi che molte aziende non hanno ancora risolto. Se un singolo modello richiede governance, sicurezza, controllo dei costi e tracciabilità del dato, un ecosistema composto da più agenti interconnessi rende questi requisiti ancora più stringenti.
“I problemi rimangono gli stessi, anzi vengono amplificati”. Più agenti interagiscono tra loro, più aumenta la complessità nella gestione degli accessi, delle autorizzazioni, delle fonti informative, dei costi di inferenza e della responsabilità sulle decisioni prodotte. Parlare di agenti senza avere prima costruito fondamenta dati solide significa quindi spostare in avanti la complessità, non eliminarla.
Data lineage e data catalog come prerequisiti dell’AI affidabile
Data lineage e data catalog stanno assumendo un ruolo sempre più centrale nella costruzione di sistemi AI affidabili. Il tema non riguarda più la consapevolezza dell’importanza di questi strumenti, ormai largamente acquisita, quanto la loro diffusione all’interno delle organizzazioni. A livello europeo il 91% delle aziende dichiara di utilizzare cataloghi dati e strumenti di lineage sia sul piano tecnico sia su quello business, ma quasi la metà limita ancora queste pratiche a specifici team, dipartimenti o casi d’uso. La difficoltà non consiste quindi nell’introdurre gli strumenti, bensì nel trasformarli in una disciplina realmente estesa all’intera organizzazione.
Il data lineage permette di ricostruire l’intero percorso del dato: dalla sorgente originaria fino alle dashboard finali di analytics, passando attraverso trasformazioni, piattaforme intermedie, applicazioni e sistemi di reporting. Significa sapere da dove proviene un’informazione, quali modifiche ha subito, quali sistemi ha attraversato e in quale contesto viene utilizzata.
Senza questa capacità di tracciabilità diventa difficile costruire sistemi AI realmente affidabili. “Il dato deve essere tracciabile. Devo sapere da dove arriva e che percorso ha fatto”. La fiducia nell’output di un modello dipende anche dalla possibilità di verificare l’affidabilità, la provenienza e il ciclo di vita delle informazioni utilizzate.
Dall’acquisizione di Octopai alla governance cross-platform
L’acquisizione di Octopai, oggi evoluta nella piattaforma Cloudera Data Lineage, rafforza il posizionamento dell’azienda sulla governance cross-platform. Uno dei limiti degli strumenti tradizionali è infatti la loro efficacia all’interno di singoli ecosistemi tecnologici: molte piattaforme riescono a monitorare il lineage nel proprio ambiente, ma perdono visibilità quando il dato attraversa sistemi differenti.
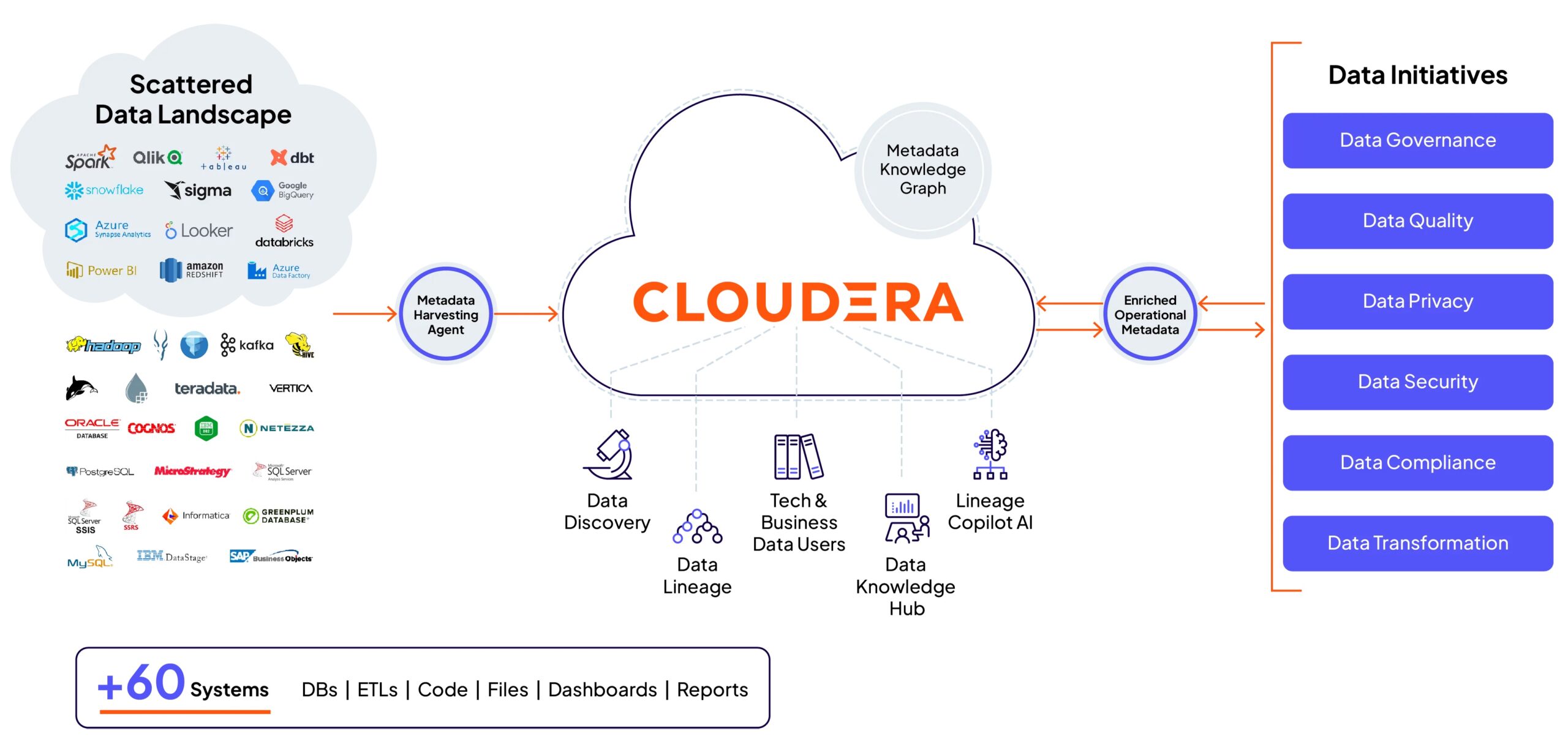
Cloudera punta invece a raccogliere metadati da oltre sessanta piattaforme, tra cui Snowflake, Databricks, Oracle, SAP, Tableau, Power BI e Qlik, con l’obiettivo di costruire una vista end-to-end automatizzata dell’intero ciclo di vita del dato. In ambienti enterprise complessi, dove convivono centinaia o migliaia di sistemi, la ricostruzione manuale dei flussi informativi non è più sostenibile.
La governance diventa quindi un problema di automazione, interoperabilità e copertura architetturale. Non basta sapere cosa accade dentro una singola piattaforma: occorre seguire il dato lungo tutto il percorso che compie nell’organizzazione.
Il limite principale è manageriale prima che tecnologico
La discussione sulle competenze AI tende spesso a concentrarsi sui profili tecnici, ma Franzini sposta il baricentro sul piano manageriale. “Le competenze tecniche possono anche mancare, ma quello che manca davvero è la visione”.
Molte grandi aziende italiane vivono in una condizione di riorganizzazione continua, con obiettivi di breve termine che cambiano rapidamente e finiscono per generare nuovi silos, nuove piattaforme isolate e nuove iniziative tattiche. L’AI, invece, richiede una strategia di lungo periodo costruita attorno alla gestione unificata del dato, alla responsabilità organizzativa e alla capacità di collegare esigenze di business, architettura IT e compliance.
Il nodo culturale è quindi parte integrante del problema tecnologico. Senza un modello decisionale capace di superare la frammentazione tra linee di business, IT, data office e compliance, anche le piattaforme più avanzate rischiano di rimanere confinate a singoli progetti.
Il ruolo strategico dei system integrator
In questo scenario cresce il ruolo dei system integrator, considerati essenziali per trasformare gli use case in progetti concreti. Sono spesso i partner a intercettare le esigenze delle linee di business, tradurle in architetture applicative e accompagnare il cliente nella scelta delle tecnologie più adatte.
Cloudera collabora con grandi integratori globali e italiani come Accenture, DXC, Engineering, Capgemini, Reply, Lutech, AgileLab e Almaviva, oltre a vendor verticali e realtà specializzate in specifici settori applicativi. L’ecosistema si sta inoltre ampliando verso provider sovereign cloud e startup AI, in una logica di collaborazione sempre più articolata.
Le competenze certificate diventano un elemento competitivo. Molte gare pubbliche e molti progetti enterprise richiedono ormai capacità avanzate sulle piattaforme dati e AI; per questo Cloudera sta investendo in percorsi di training, certificazione e validazione delle applicazioni sviluppate dai partner sulla propria piattaforma. L’obiettivo è evitare che le soluzioni verticali producano nuovi silos e favorire invece un modello in cui applicazioni e servizi si appoggiano a un layer dati condiviso.
Apertura architetturale contro lock-in
Il posizionamento competitivo di Cloudera ruota attorno a un’idea precisa: l’azienda ritiene di aver anticipato il mercato puntando molto presto su architetture aperte, ibride e indipendenti dagli hyperscaler. “Probabilmente siamo arrivati troppo presto, ma oggi questo ci dà un vantaggio competitivo”.
La progressiva maturazione del mercato AI sta rendendo più evidente il limite degli approcci troppo chiusi o fortemente dipendenti da singoli provider cloud. La strategia di Cloudera punta invece a consentire alle aziende di eseguire dati e AI “ovunque”: cloud pubblici, private cloud, ambienti on premise o infrastrutture ibride, mantenendo continuità di governance e portabilità architetturale.
Questa impostazione spiega l’insistenza su Data Anywhere e AI Anywhere, formule che non indicano soltanto una scelta di marketing, ma una precisa visione infrastrutturale: il dato e il modello non devono essere prigionieri del luogo in cui sono nati, ma devono poter seguire le esigenze di sicurezza, costo, sovranità e performance dell’organizzazione.
Crescita record in Italia
Nonostante le complessità del mercato, Cloudera rivendica una fase di forte crescita anche in Italia. Pascali parla di un anno record per clienti, recurring revenue e sviluppo del business, con una dinamica particolarmente positiva nei settori pubblica amministrazione, healthcare, finance e manifatturiero.
Il segnale più rilevante non è soltanto commerciale. Indica che il mercato sta iniziando a considerare l’intelligenza artificiale non più come una semplice sperimentazione tecnologica, ma come un percorso infrastrutturale che richiede piattaforme dati industriali, governance automatizzata, sicurezza, controllo economico e capacità di operare in ambienti ibridi.
La ricerca evidenzia tuttavia una contraddizione che attraversa gran parte delle organizzazioni intervistate. A livello globale l’85% delle aziende ritiene che l’infrastruttura dati attuale sia in grado di sostenere le priorità strategiche dei prossimi due o tre anni. Allo stesso tempo, il 79% ammette di non riuscire ad accedere a tutti i dati necessari attraverso ambienti differenti e meno di un’organizzazione su cinque dichiara di avere un patrimonio informativo completamente governato.
È proprio questa distanza tra fiducia dichiarata e maturità operativa a rappresentare uno degli aspetti più significativi emersi dall’indagine. La vera sfida non è creare l’ennesimo proof of concept, ma costruire un’infrastruttura dati governata, interoperabile e sostenibile. È su questo terreno, più che sulla semplice disponibilità di modelli generativi, che si giocherà la prossima fase della competizione AI europea.






{kind=link}