


Alibaba ha annunciato il rilascio ufficiale di Qwen3.5-397B-A17B, primo modello della nuova generazione Qwen 3.5. Si tratta di un foundation model multimodale progettato per integrare testo, immagini e video in un unico processo di ragionamento, con un posizionamento che punta esplicitamente su efficienza architetturale, capacità agentiche e scalabilità industriale.
In continuità con le versioni precedenti della famiglia Qwen, anche Qwen 3.5 viene distribuito in modalità open-weight, con i pesi addestrati pubblicamente disponibili. L’approccio non rappresenta una novità per l’ecosistema Qwen, ma assume un significato diverso alla luce della scala raggiunta: portare l’open-weight nella fascia dei modelli frontier significa rendere scaricabile e personalizzabile un sistema che compete, per dimensioni e ambizioni, con modelli proprietari molto più chiusi.
I pesi sono i parametri numerici che il modello ha appreso durante il training e che determinano come trasforma un input in un output. La loro disponibilità consente deployment locale, audit tecnico e fine-tuning su dati proprietari. In un contesto europeo attento alla sovranità digitale, la possibilità di esecuzione sotto pieno controllo infrastrutturale è un elemento non secondario.
Architettura ibrida: grande scala, attivazione selettiva
Qwen3.5-397B-A17B conta 397 miliardi di parametri complessivi, ma ne attiva soltanto 17 miliardi per ogni inferenza. Questo è possibile grazie alla combinazione di linear attention e mixture-of-experts (MoE) sparse.
Nel transformer tradizionale, il meccanismo di attenzione confronta ogni token con tutti gli altri, con un costo che cresce quadraticamente con la lunghezza del contesto. La linear attention riduce questa complessità a crescita lineare, rendendo sostenibile l’elaborazione di contesti molto estesi senza moltiplicare in modo esponenziale memoria e calcolo.
La mixture-of-experts introduce invece un’architettura modulare in cui il modello è composto da diversi “esperti” specializzati. Un meccanismo di selezione attiva solo quelli necessari per uno specifico input. Il risultato è un sistema che può raggiungere dimensioni complessive molto elevate, ma con un costo effettivo per richiesta paragonabile a quello di modelli molto più piccoli.
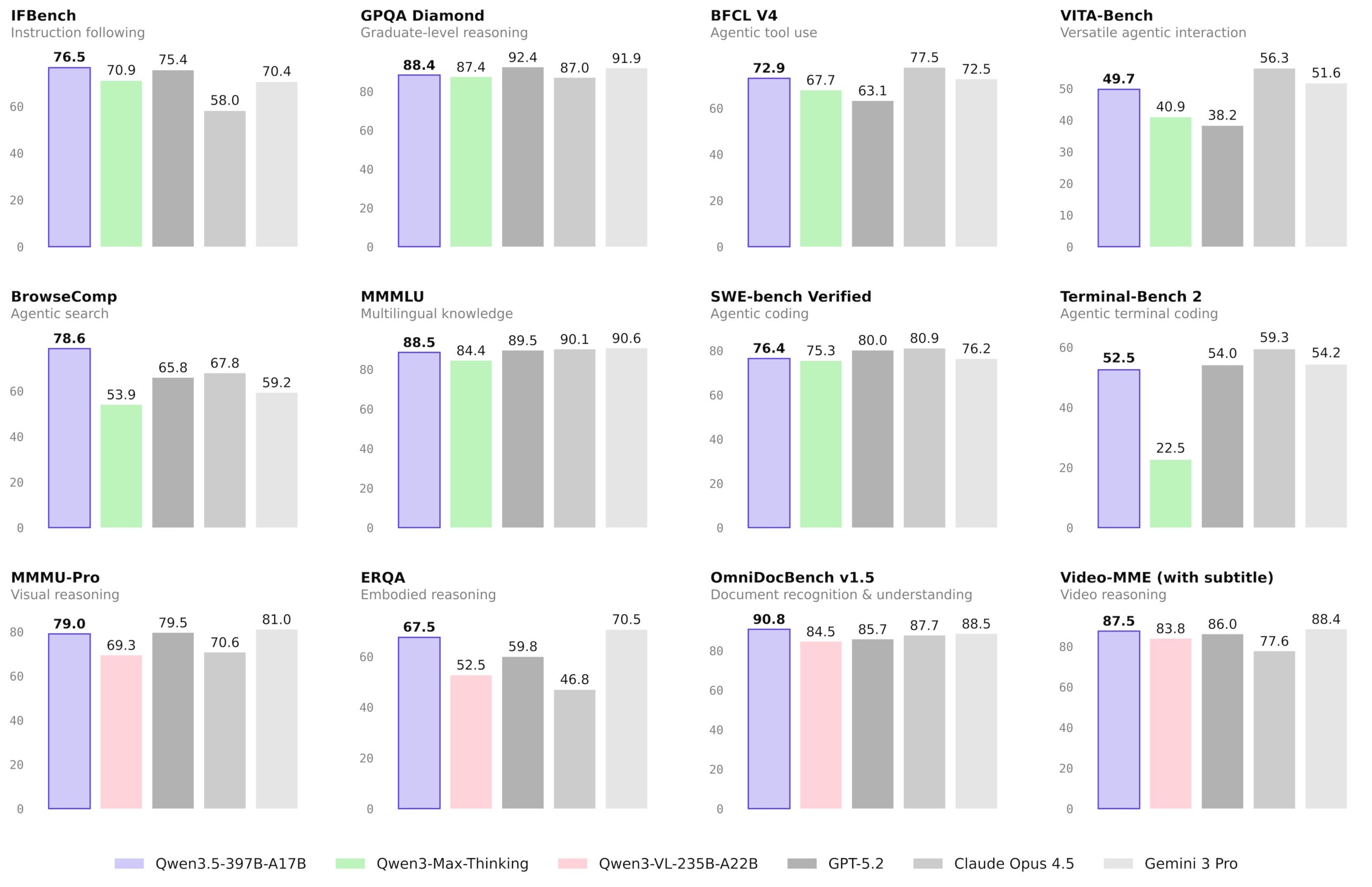
Alibaba sottolinea che Qwen3.5-397B-A17B raggiunge prestazioni comparabili a Qwen3-Max-Base da oltre 1 trilione di parametri. Il messaggio industriale è chiaro: l’efficienza architetturale diventa alternativa allo scaling “a forza bruta”, con benefici diretti su consumo GPU, costi energetici e sostenibilità economica del training e dell’inferenza.
In un contesto globale segnato da vincoli sull’accesso a GPU avanzate e da costi energetici crescenti, questa scelta tecnica assume anche una dimensione strategica.
Multi-token prediction e riduzione della latenza
Tra le innovazioni dichiarate figura la multi-token prediction, che consente di generare più token in un singolo passo computazionale. Nei modelli tradizionali la generazione è strettamente sequenziale: ogni token dipende dal precedente. Prevedere più token per ciclo permette di ridurre il numero di passaggi necessari e quindi la latenza complessiva.
Quando Alibaba indica throughput fino a 8,6× e 19× superiori rispetto a Qwen3-Max in contesti lunghi, si riferisce alla capacità combinata di architettura MoE, linear attention e multi-token prediction di aumentare l’efficienza di inferenza senza sacrificare qualità.
Infrastruttura eterogenea e pipeline FP8
Il training multimodale richiede un’architettura capace di trattare in modo differenziato testo e immagini. Alibaba descrive un’infrastruttura eterogenea che separa la parallelizzazione tra componente vision e componente language: le parti del modello che elaborano immagini vengono distribuite e ottimizzate in modo diverso rispetto a quelle linguistiche.
L’attivazione sparsa degli esperti consente di sovrapporre calcoli tra componenti, migliorando l’utilizzo dell’hardware. La pipeline FP8 utilizza rappresentazioni numeriche a 8 bit per parte delle operazioni. Riducendo la precisione rispetto ai formati tradizionali (FP16 o BF16), diminuisce la memoria utilizzata e il consumo di banda tra GPU, aumentando velocità ed efficienza energetica. Nei layer più sensibili viene mantenuta una precisione superiore per evitare instabilità numeriche. Il risultato dichiarato è un throughput vicino a quello di modelli puramente testuali anche in presenza di dati multimodali, segnale di maturità ingegneristica.
Reinforcement learning e apprendimento per scenari complessi
Il salto generazionale rispetto alla serie Qwen3 viene attribuito a un’estesa fase di reinforcement learning. Questa tecnica mette il modello in ambienti simulati dove deve prendere decisioni e riceve segnali di ricompensa o penalità in base all’esito.
Il framework adottato è asincrono e disaggregato: i processi di addestramento non devono avanzare tutti allo stesso ritmo e training e inference vengono gestiti su componenti infrastrutturali separati. Questo consente di sfruttare meglio le risorse hardware disponibili.
Lo speculative decoding anticipa più possibili continuazioni del testo per ridurre la latenza; il rollout router replay riutilizza percorsi già esplorati durante l’addestramento; il multi-turn rollout locking stabilizza l’apprendimento nelle interazioni articolate su più passaggi.
L’accelerazione dichiarata tra 3× e 5× riguarda l’intero ciclo di training e ottimizzazione. Il valore è nella capacità di simulare milioni di scenari agentici complessi, preparando il modello a gestire sequenze di azioni, pianificazione multi-step e workflow articolati.
Multimodalità nativa, contesto esteso e copertura linguistica
La versione hosted Qwen3.5-Plus offre una finestra di contesto di 1 milione di token. Una finestra di questa dimensione consente di elaborare documentazione tecnica estesa, grandi codebase o contenuti video lunghi in un’unica sessione.
Il supporto linguistico passa da 119 a 201 lingue e dialetti, con vocabolario ampliato a 250mila token. L’estensione del vocabolario migliora l’efficienza di rappresentazione linguistica, riducendo il numero di token necessari per esprimere contenuti in lingue meno diffuse.
Governance, bias e quadro europeo
L’adozione di un modello di questa scala non è soltanto una scelta tecnologica o di performance, ma una decisione che investe direttamente la governance del dato e la gestione del rischio informativo. In modalità hosted, i flussi di input e output transitano su infrastrutture del provider, con implicazioni legate alla localizzazione geografica, alla gestione dei log e alle policy di sicurezza applicate. In modalità open-weight, invece, l’organizzazione può eseguire il modello su infrastrutture proprie o su cloud sotto giurisdizione europea, mantenendo un controllo diretto sull’ambiente operativo e sulle misure di protezione adottate.
Rimane tuttavia un livello più profondo da considerare: l’origine dei dataset utilizzati nel pretraining e le scelte di allineamento effettuate durante le fasi di reinforcement learning. Ogni foundation model incorpora inevitabilmente bias derivanti dai dati di addestramento, dai criteri di filtraggio e dalle policy di moderazione applicate. Nel caso di modelli sviluppati in contesti geopolitici differenti, sensibilità culturali, priorità regolatorie e linee guida sui contenuti possono riflettersi nelle risposte generate. Non si tratta di una peculiarità di Qwen, ma di una caratteristica strutturale di qualsiasi modello di questa categoria.
Per un utilizzo aziendale, soprattutto in settori regolamentati, questo implica la necessità di testare il comportamento del modello su casi d’uso reali, verificare eventuali distorsioni linguistiche o interpretative e integrare meccanismi di controllo applicativo che intercettino risposte problematiche prima della messa in produzione. La disponibilità open-weight facilita questo processo perché consente analisi più approfondite e personalizzazioni mirate, ma non sostituisce una governance strutturata.
Con l’AI Act europeo, i foundation model e i sistemi classificati come ad alto rischio saranno soggetti a obblighi di documentazione tecnica, gestione del rischio e monitoraggio continuo. In questo contesto, la sovranità digitale non si limita alla scelta dell’infrastruttura su cui eseguire il modello, ma comprende la capacità di comprendere il ciclo di vita del sistema, le logiche di training e i meccanismi di allineamento. La questione non è tanto l’origine geografica del modello quanto la possibilità di inserirlo in un perimetro di controllo conforme alle normative europee e alle policy interne di compliance.
Con Qwen 3.5, Alibaba propone un modello che punta su scala ed efficienza mantenendo l’approccio open-weight. La sfida per le imprese non è solo valutarne le prestazioni, ma comprenderne le implicazioni in termini di controllo, responsabilità e gestione del rischio in un contesto regolatorio sempre più strutturato.
Come utilizzare Qwen 3.5
Qwen 3.5 può essere utilizzato tramite Qwen Chat, con tre modalità operative: Auto, che abilita thinking adattivo e uso di strumenti; Thinking, focalizzata su ragionamento profondo; Fast, orientata alla rapidità di risposta.
In ambito enterprise, il modello può essere integrato via API attraverso Alibaba Cloud Model Studio, con attivazione di reasoning avanzato e strumenti di ricerca. In alternativa, la versione open-weight consente deployment locale, mantenendo pieno controllo su dati e infrastruttura, opzione particolarmente rilevante per settori regolamentati.






{kind=link}