


Documenti, contratti, fatture, report finanziari, manuali tecnici, pratiche amministrative e archivi aziendali continuano a rappresentare una delle principali fonti informative per le organizzazioni. L’affermazione delle piattaforme Retrieval-Augmented Generation, dei motori di ricerca semantici e degli agenti AI ha trasformato questi contenuti in una risorsa strategica: la qualità delle risposte generate dai modelli dipende sempre più dalla capacità di acquisire, strutturare e recuperare correttamente le informazioni contenute nei documenti.
In questo segmento si inserisce Mistral OCR 4, nuova generazione della tecnologia di document understanding sviluppata da Mistral AI, la società francese fondata nel 2023 da ex ricercatori provenienti da Google DeepMind e Meta. Nel giro di pochi anni Mistral è diventata uno dei principali protagonisti europei nel settore dell’intelligenza artificiale, costruendo un’offerta che comprende foundation model, strumenti di ricerca enterprise, componenti per agenti AI e soluzioni destinate alle organizzazioni che richiedono maggiore controllo sull’infrastruttura e sui dati.
La disponibilità di opzioni self-hosted e l’attenzione ai temi della sovranità digitale hanno contribuito a caratterizzare la proposta dell’azienda in un mercato dominato da fornitori statunitensi. OCR 4 aggiunge alla piattaforma Mistral funzionalità dedicate all’ingestione e alla strutturazione dei contenuti documentali.
Oltre il riconoscimento dei caratteri
Per molti anni le tecnologie OCR sono state utilizzate principalmente per convertire documenti cartacei o PDF in testo digitale. Nei contesti attuali questo approccio mostra limiti evidenti. Un sistema di ricerca semantica, una piattaforma RAG o un agente AI non devono soltanto leggere il contenuto di un documento, ma anche comprenderne la struttura.
OCR 4 restituisce una rappresentazione strutturata del documento invece di limitarsi alla trascrizione del testo. Ogni elemento identificato viene associato a una bounding box che ne definisce la posizione precisa all’interno della pagina. Il modello classifica inoltre le diverse componenti del documento, distinguendo titoli, paragrafi, tabelle, equazioni, firme e altri elementi strutturali.
A queste informazioni si aggiungono punteggi di affidabilità generati sia a livello di pagina sia a livello di singola parola. Il risultato combina contenuto, posizione, classificazione semantica e livello di confidenza in un unico insieme di metadati utilizzabile dalle applicazioni a valle.
Le organizzazioni possono così sapere non soltanto quali informazioni sono presenti in un documento, ma anche dove si trovano, quale funzione svolgono e con quale grado di affidabilità sono state riconosciute.
Bounding box, classificazione semantica e confidence score
Le bounding box rappresentano una delle novità più rilevanti introdotte da OCR 4. Le coordinate spaziali associate agli elementi riconosciuti consentono di collegare risultati e citazioni alla posizione esatta all’interno del documento originale.
Questa caratteristica facilita la costruzione di sistemi di ricerca che mantengono il collegamento con le fonti e semplifica le attività di verifica e validazione nei workflow documentali. In ambiti regolamentati può inoltre supportare processi di auditing, redazione di dati sensibili e controlli di conformità.
La classificazione semantica aggiunge un ulteriore livello di struttura. Titoli, paragrafi, tabelle, formule matematiche e firme possono essere trattati in modo differente durante le fasi di indicizzazione, retrieval ed elaborazione automatica.
I punteggi di confidenza consentono invece di integrare meccanismi di supervisione umana. Le organizzazioni possono definire soglie operative che determinano quando un’informazione viene accettata automaticamente e quando richiede una verifica manuale, concentrando l’intervento degli operatori sui casi più incerti.
Un componente per retrieval e workflow agentici
L’utilità di OCR 4 emerge soprattutto nei processi che richiedono recupero e utilizzo delle informazioni contenute nei documenti.
Nei sistemi Retrieval-Augmented Generation, la qualità delle risposte dipende dalla capacità di individuare e recuperare il contesto corretto. La trasformazione dei documenti in semplici blocchi di testo comporta spesso la perdita di elementi strutturali importanti. OCR 4 conserva invece la gerarchia informativa del documento e permette di costruire unità informative semanticamente coerenti per le attività di retrieval.
Lo stesso approccio può essere applicato a knowledge base aziendali, archivi documentali e piattaforme di ricerca enterprise. Titoli, sezioni e tabelle mantengono la propria identità durante l’indicizzazione, migliorando la precisione del recupero delle informazioni.
Negli ambienti agentici, le informazioni strutturate possono essere utilizzate per attività come compilazione di moduli, elaborazione di fatture, verifica documentale, controlli di conformità e gestione di procedure amministrative. Mistral definisce questi elementi structural primitives for agents, componenti che consentono agli agenti di interagire con il contenuto documentale in modo operativo.
Il ruolo nel Search Toolkit di Mistral
OCR 4 svolge il ruolo di componente di ingestione documentale nel nuovo Mistral Search Toolkit, framework open source presentato dall’azienda durante l’AI Now Summit.
Il toolkit comprende componenti dedicati a ingestione documentale, retrieval, valutazione e costruzione di sistemi di ricerca enterprise. All’interno di questa architettura OCR 4 trasforma documenti eterogenei in dati strutturati pronti per l’indicizzazione e il recupero delle informazioni.
Bounding box, classificazioni semantiche e punteggi di affidabilità accompagnano il contenuto nelle successive fasi della pipeline, mantenendo il collegamento con le fonti originali e facilitando la generazione di risposte supportate da riferimenti verificabili.
Multilinguismo e lingue low-resource
OCR 4 supporta 170 lingue distribuite in 10 gruppi linguistici. La copertura comprende sia le principali lingue utilizzate nelle attività internazionali sia numerosi idiomi che tradizionalmente rappresentano una sfida per i sistemi OCR.
Secondo i dati forniti da Mistral, il modello ottiene le migliori prestazioni in tutti gli otto gruppi linguistici analizzati nella valutazione interna Crawl Multilingual Evaluation: inglese, Europa occidentale, Europa orientale, Medio Oriente, cinese, Asia orientale, Asia sud-orientale e lingue specialistiche.
Le differenze più marcate rispetto ai concorrenti emergono nelle cosiddette lingue low-resource. Tra quelle citate dall’azienda figurano hindi, giapponese, georgiano, bengalese, armeno, ebraico, greco, gujarati, tamil, malayalam, kannada e telugu.
Benchmark sotto esame: perché Mistral contesta le metriche
Per valutare OCR 4, Mistral ha effettuato confronti con modelli OCR AI-native, servizi documentali enterprise, modelli multimodali generalisti e con la precedente generazione OCR 3.
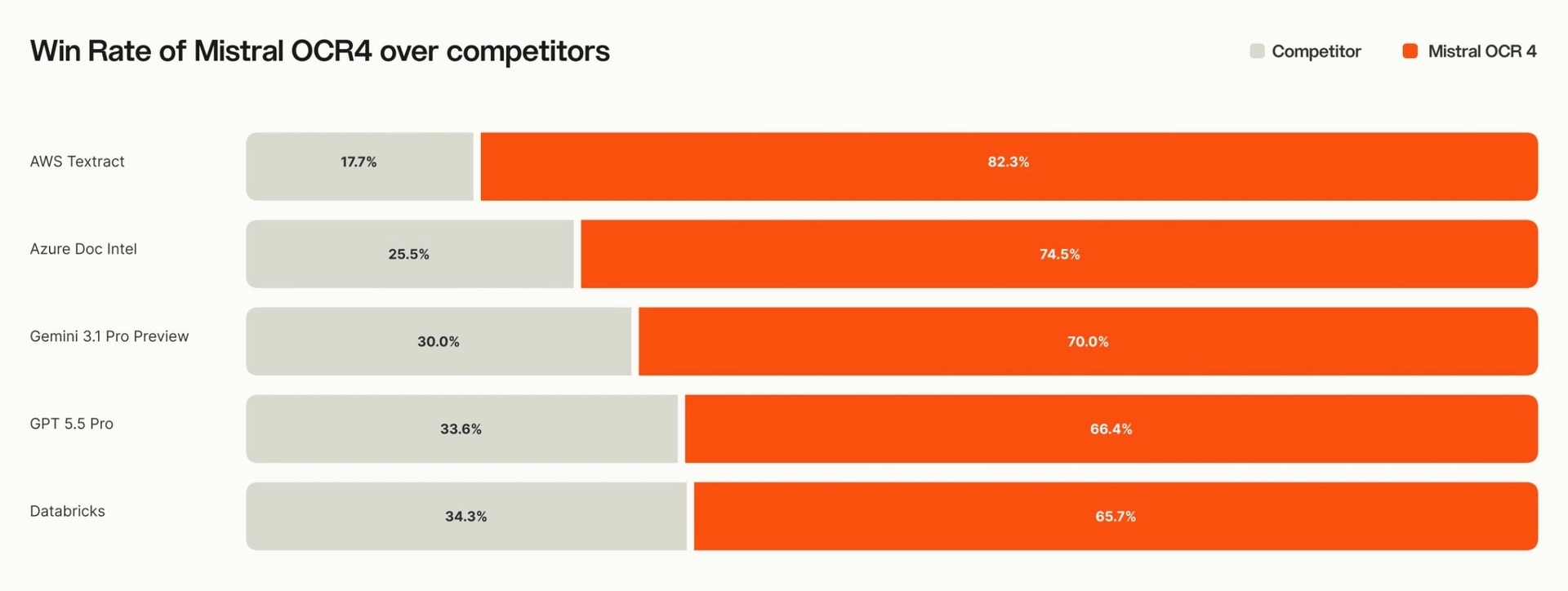
Sul benchmark pubblico OlmOCRBench il sistema ha ottenuto un punteggio di 85,20, mentre su OmniDocBench ha raggiunto 93,07. Nella valutazione interna Crawl Multilingual Evaluation il punteggio dichiarato è pari a 0,98.
L’azienda ha inoltre realizzato una valutazione basata sul giudizio umano utilizzando oltre 600 documenti in più di dodici lingue provenienti da casi d’uso reali. Annotatori indipendenti hanno confrontato in modalità cieca gli output di OCR 4 con quelli dei sistemi concorrenti. Secondo Mistral, il nuovo modello è stato preferito nel 72% dei casi.
Una parte significativa della documentazione tecnica pubblicata dall’azienda è dedicata alle limitazioni dei benchmark attualmente disponibili. Tra i problemi segnalati figurano annotazioni errate nei dataset di riferimento, errori tipografici presenti nei ground truth, formule matematiche espresse con sintassi LaTeX differenti ma equivalenti dal punto di vista del rendering, difficoltà nella valutazione di espressioni segmentate e problemi legati all’ordine di lettura nei documenti multi-colonna.
Mistral segnala inoltre casi in cui la gestione di intestazioni e piè di pagina produce penalizzazioni artificiali nei punteggi. Secondo l’azienda, molte delle discrepanze rilevate dai benchmark non derivano da errori del modello ma dalle modalità con cui gli output vengono confrontati con i dati di riferimento. Il fenomeno risulta particolarmente evidente nei documenti scientifici, matematici e multi-colonna. Per questa ragione Mistral considera i benchmark indicatori direzionali e non misure definitive delle prestazioni in produzione.
I primi impieghi in finanza, proprietà intellettuale e ricerca documentale
Tra i primi utilizzatori figura Rogo, società specializzata in strumenti AI per il settore finanziario. Aidan Donohue, AI Engineer dell’azienda, afferma che OCR 4 ha raggiunto un’accuratezza equivalente a quella dei principali parser documentali agentici utilizzati nell’analisi di documentazione finanziaria ricca di grafici e figure, con costi inferiori di circa otto volte e una latenza ridotta di diciassette volte.
Anche Anaqua, attiva nella gestione della proprietà intellettuale, evidenzia benefici sul fronte delle prestazioni. Secondo Ivan Mihailov, AI Engineer dell’azienda, OCR 4 risulta circa quattro volte più rapido per pagina rispetto al provider utilizzato in precedenza.
I primi casi d’uso riguardano la trasformazione di fatture in dati strutturati, la digitalizzazione di archivi aziendali, l’estrazione di contenuti da documentazione tecnica e scientifica e l’alimentazione di piattaforme di ricerca enterprise.
Oltre l’OCR: la differenza tra OCR 4 e Document AI
OCR 4 e Document AI utilizzano lo stesso motore di riconoscimento documentale ma rispondono a esigenze differenti.
OCR 4 costituisce il livello di base della piattaforma e restituisce testo estratto, coordinate spaziali, classificazione semantica e punteggi di affidabilità. Document AI aggiunge funzionalità per generare output conformi a schemi JSON definiti dall’utente, annotare le immagini presenti nei documenti e applicare istruzioni personalizzate ai contenuti estratti.
Gli utenti possono fornire schemi dati specifici, definire modalità di classificazione o richiedere elaborazioni orientate a particolari processi aziendali. Per queste attività interviene il modello mistral-small-2603, che riorganizza il risultato dell’OCR secondo i requisiti applicativi definiti.
Nelle implementazioni orientate all’ingestione documentale può essere sufficiente utilizzare direttamente OCR 4. Quando i dati devono essere consegnati già strutturati secondo schemi applicativi specifici, Document AI aggiunge un ulteriore livello di elaborazione.
Un OCR che può restare nel data center aziendale
OCR 4 può essere distribuito direttamente nell’infrastruttura del cliente attraverso un singolo container. La modalità self-hosted consente di elaborare documenti senza trasferire dati verso servizi esterni.
Per molte organizzazioni europee entrano in gioco requisiti di conformità normativa, residenza dei dati, sovranità digitale e protezione delle informazioni sensibili. La possibilità di mantenere l’elaborazione documentale all’interno del proprio ambiente rappresenta uno degli elementi distintivi della proposta Mistral rispetto alle soluzioni disponibili esclusivamente come servizi cloud.
Il tema assume particolare rilevanza in Europa, dove governance del dato e autonomia tecnologica stanno acquisendo un peso crescente nelle strategie di adozione dell’intelligenza artificiale.
Disponibile tramite Studio, SageMaker e Foundry
Mistral OCR 4 e Document AI sono disponibili tramite Mistral Studio, Amazon SageMaker e Microsoft Foundry, mentre il supporto a Snowflake Parse Document è previsto successivamente.
Kimmi Grewal, Vice President AI Ecosystem Partnerships di Microsoft, ha definito la disponibilità di Document AI basato su OCR 4 all’interno di Foundry un passaggio significativo nella collaborazione tra le due aziende per integrare capacità avanzate di comprensione documentale nei workflow AI enterprise.
OCR 4 viene proposto a 4 dollari per 1.000 pagine tramite API standard. L’utilizzo della Batch API riduce il costo a 2 dollari per 1.000 pagine, mentre le funzionalità Document AI vengono offerte a 5 dollari per 1.000 pagine.
Mistral esclude espressamente l’utilizzo del modello per diagnosi mediche, consulenza legale, decisioni finanziarie ad alto rischio, applicazioni safety-critical e contenuti non documentali come audio e video.






{kind=link}