

Ciao a tutti, sono Vincenzo Lomonaco, ricercatore e docente all’Università di Pisa.
Nella puntata di oggi parliamo di una delle tecnologie più importanti che ha segnato una rivoluzione fondamentale nel mondo dell’intelligenza artificiale moderna e per la nascita dei Large Language Models.
Parliamo di Transformers, tuttora alla base dei modelli allo stato dell’arte di AI, come Llama, ChatGPT, Gemini, tutti! Scopriamolo insieme in questa puntata di Le Voci dell’AI.
I Transformers sono un’architettura di modelli di apprendimento automatico che prende il nome dalla capacità di trasformare in modo efficace e dinamico soprattutto le rappresentazioni degli input attraverso meccanismi di attenzione, vedremo meglio in questa puntata di cosa si tratta, che consentono al modello di AI di focalizzarsi selettivamente sulle parti più rilevanti dei dati in ingresso durante l’elaborazione.
La denominazione deriva appunto dall’idea di trasformare queste sequenze di simboli in rappresentazioni di dimensioni diverse, modulando il flusso informativo tramite pesi adattivi, parametri piuttosto che ricorrendo a passaggi sequenziali piuttosto rigidi.
Introdotti per la prima volta nel 2017 da Ashish Vaswani e collaboratori presso Google, i Transformers hanno rappresentato un punto di svolta rispetto alle reti neurali tradizionali ricorrenti e convoluzionali.
Il loro design è stato concepito squisitamente per gestire in parallelo una sequenza di dati, per esempio una frase composta da parole, sfruttando pienamente le potenzialità di calcolo delle GPU e superando le limitazioni legate alla lunghezza delle sequenze e al problema del gradiente evanescente nella back propagation, quindi durante il processo di addestramento.
Nel giro di pochissimi anni la loro applicazione nell’ambito principalmente dell’elaborazione del linguaggio naturale, ha prodotto risultati straordinari, dai modelli BERT e GPT alle architetture encoder-decoder utilizzate nelle traduzioni automatiche e nella generazione di testo.
Gli approcci basati su Transformers hanno stabilito nuovi standard di riferimento in termini di performance, consentendo livelli di comprensione e generazione linguistica fino a quel momento inimmaginabili.
Il loro impatto si è poi esteso rapidamente, ben oltre il mondo dell’elaborazione del linguaggio naturale, grazie alla flessibilità ed efficienza del meccanismo di attenzione.
È stato quindi possibile adattarne il paradigma di funzionamento a dati visivi, audio e multidimensionali, dando origine a modelli come i Vision Transformers nel mondo della visione artificiale e a varie sperimentazioni nella bioinformatica, nell’analisi delle time series e nei compiti di data mining, più in generale.
La rivoluzione portata dai Transformers risiede non solo nella capacità di modellare relazioni a lungo raggio di dipendenze tra le parole o tra i dati, ma anche nella possibilità di scalare i parametri di un modello in modo massiccio, ottenendo performance sempre crescenti con l’aumentare delle dimensioni, dei modelli e dei dati a disposizione.
Questo approccio ha inaugurato un’era in cui l’intelligenza artificiale può apprendere da miliardi di esempi e adattarsi a contesti eterogenei, offrendo soluzioni avanzate in traduzione, sintesi, riconoscimento, predizione e, più in generale, persino creatività automatica, come abbiamo visto più recentemente.
Inoltre, la natura modulare e composizionale dei Transformers ne ha facilitato la personalizzazione tramite tecniche di transfer learning e fine tuning, permettendo di riadattarli a compiti più specifici anche con quantità ridotte di dati aggiuntivi, mentre la loro scalabilità orizzontale li rende facilmente distribuibili su infrastrutture cloud e parallele di grandissime dimensioni.
In sostanza, l’applicabilità trasversale dei Transformers li rende oggi uno strumento fondamentale per sviluppare sistemi intelligenti capaci di operare efficacemente con testo, immagini, suoni e dati strutturati e multimodali, aprendo nuovi orizzonti in ambiti scientifici, industriali, creativi, ben oltre la originaria applicazione nel solo mondo del natural language processing, dove comunque oggi rappresentano lo stato dell’arte consolidato e indiscusso.
![]()
In questa immagine vediamo un esempio di architettura Transformer. La struttura è divisa in due parti principali: l’encoder, la colonna a sinistra e il decoder a destra.
L’encoder riceve l’input, ad esempio una frase in lingua italiana, una domanda e lo elabora per capirne il significato e il contesto.
Questo modulo del Transformer utilizza meccanismi chiamati di Multi-Head Attention per pesare l’importanza delle diverse parole nella frase e capire come meglio si relazionano tra loro, capirne il significato. Quindi l’informazione elaborata dall’encoder viene poi passata al decoder.
Il decoder prende questa informazione e genera parola per parola l’output desiderato, ad esempio la traduzione della frase in input oppure la risposta al quesito in input.
Anche il decoder usa meccanismi di attention sia per concentrarsi sulle parti più rilevanti dell’input originale fornito dall’encoder, sia per considerare le parole che ha già generato fino a un certo momento in questa generazione sequenziale, parola per parola.
Entrambe le parti utilizzano anche reti feedforward, cioè reti neurali ordinarie all’interno dei loro sotto moduli, per processare ulteriormente, fondere le informazioni nel tempo e utilizzare anche tecniche come quella del position encoding per tenere conto dell’ordine delle parole, un aspetto cruciale del linguaggio.
L’intero processo mira a trasformare una sequenza di input in una sequenza di output in modo efficace.
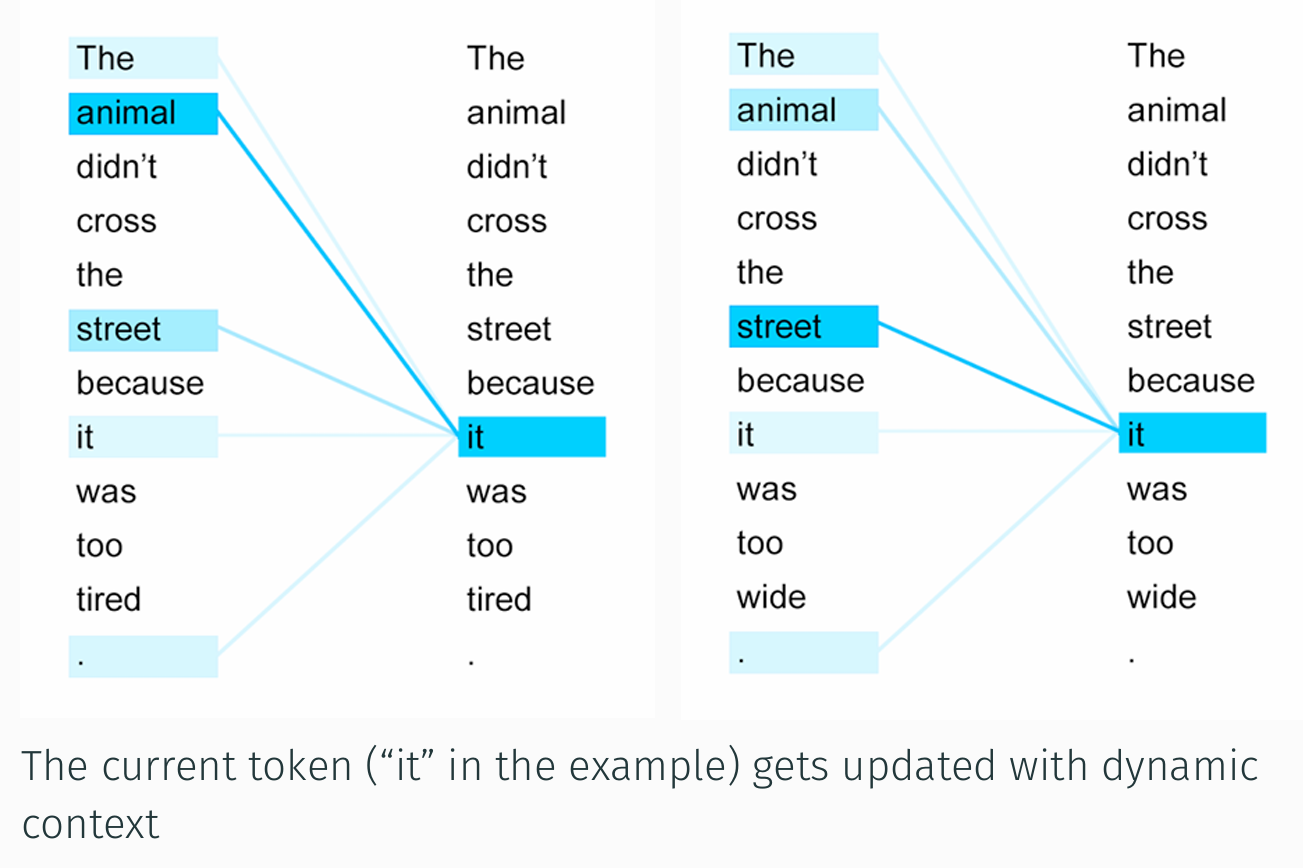
In questa immagine, invece, vediamo un esempio chiarificatore di come il meccanismo di attention nei Transformers permetta al modello di aggiornare dinamicamente la rappresentazione di un token una parola, it, nel nostro caso, in base al contesto circostante.
Sul pannello di sinistra l’attenzione del token corrente it si distribuisce, come vedete, su diverse parole chiave della frase di partenza: animal, street e persino il punto finale ricevono particolare attenzione, con animal che gioca il ruolo più rilevante; infatti è la parola alla quale IT si riferisce.
L’esatto bilanciamento emerge visivamente dai tratti più marcati, indicativi di un peso di attenzione maggiore.
Sul pannello di destra, invece, vediamo che modificando un singolo termine, tired viene sostituito da wide, l’ultima parola in questa frase, viene ricalibrata completamente l’attenzione della parola it: stavolta è street che assume il peso principale nel determinare il significato di Iit, come ci aspetteremmo, mentre gli altri token perdono di importanza.
Questo esempio evidenzia la flessibilità dell’architettura Transformers nel guardare all’intera sequenza in parallelo e selezionare per ciascun token le informazioni più utili a comprenderne il significato.
In sostanza, l’immagine illustra con chiarezza come l’attenzione agisca da filtro adattivo, consentendo a ogni parola di trasformare la propria rappresentazione in funzione dell’intero contesto e non di un semplice ordine sequenziale.
Bene, in questa puntata abbiamo discusso dell’importantissimo ruolo dei Transformers, un’architettura modulare basata su reti neurali profonde – deep learning, che ha drammaticamente rivoluzionato il mondo dell’AI degli ultimi anni, proponendo una soluzione molto efficiente, efficace e scalabile e direi piuttosto agnostica rispetto al tipo di dati di addestramento.
Per molte puntate forse abbiamo glissato su questa importante e fondamentale tecnologia che sta in realtà alla base di tutte le soluzioni più importanti di AI generativa moderna.
È la soluzione definitiva? Esistono soluzioni tecnologiche migliori? Nessuno lo sa per certo, ma la storia insegna che ogni tecnologia ha il suo tempo, anche se la fine dei Transformers sembra ancora lontana.
Ciao! Alla prossima puntata di Le Voci dell’AI.






{kind=link}