

{kind=link}
Ciao a tutti! Siamo arrivati all’episodio ventitré di Le Voci dell’AI.
Oggi parliamo di modelli di AI generativa open access e open source e del perché è critico che le aziende prestino attenzione e sperimentino con questi modelli.
La settimana scorsa, nell’episodio ventidue, ci siamo dedicati a capire se è vero o no che le risposte dei modelli offerti da OpenAI GPT 3.5 e 4 danno oggi risposte qualitativamente inferiori a confronto di qualche mese fa. Non siamo arrivati a una conclusione definitiva, ma abbiamo detto che il potenziale degrado della qualità è motivo sufficiente per considerare delle alternative.
Le alternative non sono solo i modelli di AI generativa offerti dai competitor di OpenAI, ma anche dei modelli di tipo open access e open source come LLama 2, sviluppato da Meta.
In realtà c’è un’altra ragione critica per prestare attenzione ai modelli open access e open source: la possibilità di fare il fine tuning di questi modelli con dati proprietari della nostra azienda, una cosa che OpenAI e concorrenti non offrono ancora come un servizio facile da usare e chiavi in mano.
Le aziende che visito nelle mie giornate di consulenza, di solito mi fanno questa serie di domande: che cosa è che non sappiamo ancora? Le nostre idee su come usare l’AI generativa per far avanzare il business hanno senso o sono semplicistiche o impossibili da realizzare o troppo facili da copiare o destinate a fallire? Come possiamo difenderci dai concorrenti che potrebbero usare l’AI generativa per ricreare il nostro business a una frazione del nostro costo? Come facciamo a ispirare tutta la nostra forza lavoro, così da abbracciare l’AI generativa e suggerire nuove idee? Qual è la cosa più fantascientifica che faresti con l’AI generativa al nostro posto? E una volta risposto a tutte queste domande, ci sono di solito una serie di domande successive.
Come partiamo? Sviluppiamo le competenze in casa o ci affidiamo a un outsourcer? E se sviluppiamo le competenze in casa, come strutturiamo il team di AI? Su quali tecnologie, tecniche e casi d’uso ci concentriamo prima? Quali sono le aree dove perderemmo solo tempo perché le cose cambiano troppo velocemente? Tra tutte le risposte che do a queste domande ce n’è una che conoscete già l’abbiamo discussa nell’episodio diciassette, quando ho detto che la capacità di fare il fine tuning dei modelli di AI che esistono oggi sul mercato dovrebbe essere considerata una competenza strategica, e assemblare un team in grado di fare quel fine tuning dovrebbe essere una priorità assoluta per qualunque business che voglia rimanere competitivo nell’era dell’intelligenza artificiale.
L’operazione di fine tuning è l’unico modo in cui un cosiddetto modello di fondazione come GPT 4 o LLama 2 che può assorbire i dati della nostra azienda e usarli nella generazione delle risposte agli utenti.
Il tuning è anche il meccanismo critico per ottenere performance eccezionali.
Come vedete in questo grafico rilasciato da OpenAI, qui l’azienda dimostra come l’accuratezza delle risposte di GPT 4 sia molto migliorata dopo che il modello è stato utilizzato con una tecnica di tuning chiamata Reinforced Learning from Human Feedback.
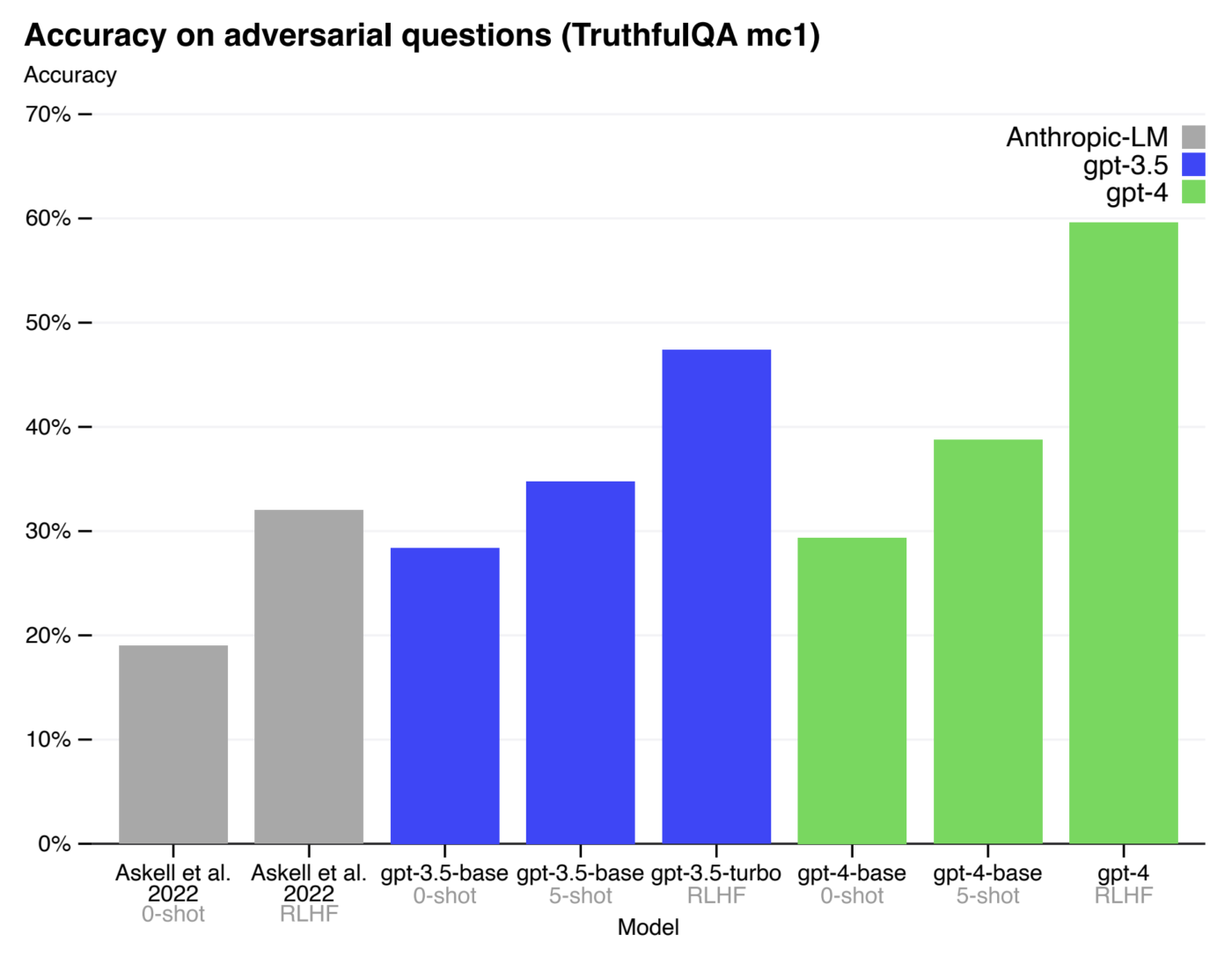
Per il momento non c’è ancora un modo automatizzato di fare il fine tuning dei modelli di OpenAI, Anthropic, Cohere e così via.
Queste aziende offrono questa possibilità più come un servizio di consulenza ad hoc per questo o quel cliente.
I modelli open source e open access, invece, hanno visto un’esplosione di tool e servizi che permettono il fine tuning in casa senza richiedere una conoscenza straordinaria della teoria alla base del machine learning, e quindi le aziende che non vogliono aspettare l’arrivo di una soluzione di fine tuning automatizzata o che non vogliono investire in una consulenza ad hoc con OpenAi e i concorrenti possono percorrere questa strada.
Non è una strada per tutti, ma è certamente la strada da percorrere per chi voglia acquisire un vantaggio competitivo rispetto ai concorrenti o per chi voglia garantirsi una qualità costante nelle risposte ricevute dal modello scelto o per chi non voglia dipendere esclusivamente da una azienda che offre un modello centralizzato per usare un servizio vitale come l’AI generativa.
La qualità delle risposte dei modelli open access e open source potrebbe non raggiungere mai la parità con i modelli commerciali di ultima generazione.
La ragione è che i fornitori tecnologici commerciali come OpenAI o Microsoft possono contare su un budget straordinario per acquisire enormi quantità di dati proprietari e migliorare la qualità dei propri modelli.
Detto questo, il tuning applicato a questi modelli open access e open source può portarvi molto lontano.
Per esempio, StabilityAI, la startup che sviluppa il famosissimo modello Stable Diffusion, ha rilasciato una versione di LLama chiamata inizialmente FreeWilly e ora rinominata Stable Beluga 2, che apparentemente è in grado di generare risposte della stessa qualità di GPT 3.5 Turbo in alcuni benchmark.
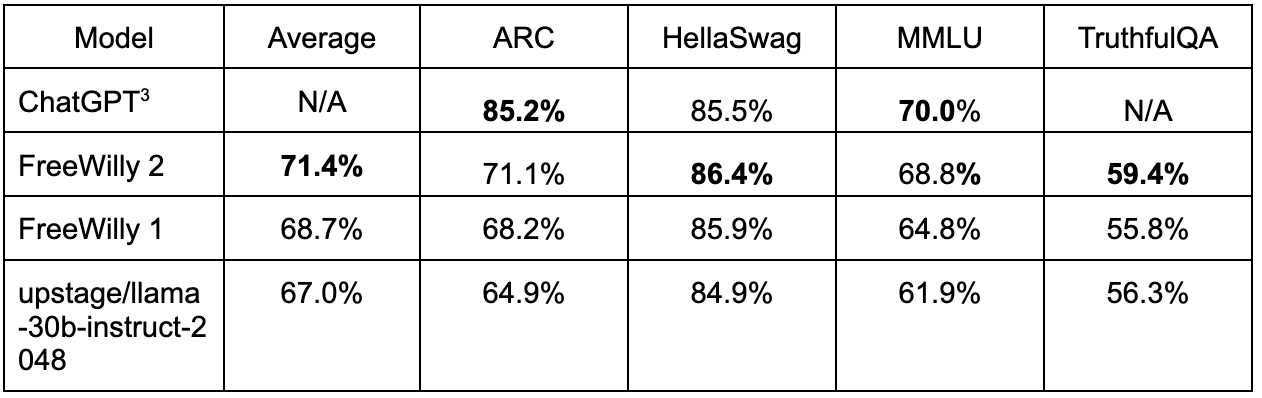
A questo punto ipotizziamo che un’azienda sia arrivata alla conclusione che valga la pena sviluppare le competenze per eseguire il tuning dei modelli open access e open source con l’idea di utilizzarli a scopo commerciale.
Qui c’è una sottigliezza che richiede grande attenzione: i modelli di AI generativa che vengono rilasciati dalla comunità, quelli che potete scaricare e utilizzare sui vostri computer sono sempre accompagnati da una licenza che chiarisce per quali casi d’uso questi modelli non possono essere utilizzati, se è possibile utilizzare questi modelli a scopo commerciale o quali tipi di aziende sono autorizzate a usare questi modelli.
Tutti i modelli di AI generativa rilasciati dalla comunità vengono impropriamente dichiarati open source e quindi le aziende assumono di poter utilizzare questi modelli con grande libertà fino al punto di costruire su questi modelli i propri prodotti senza alcuna restrizione, ma non è assolutamente il caso affinché un modello o un software in generale possa essere dichiarato open source.
La licenza d’uso deve rispettare una serie di condizioni che formano la definizione di open source.
La stragrande maggioranza dei modelli di AI generativa rilasciati dalla comunità non rispetta queste condizioni, permettendo l’uso per ricerca e sviluppo, ma non l’uso a scopo commerciale.
I modelli che sono impropriamente definiti open source devono essere più propriamente ridefiniti come open access. Open access significa che puoi giocare e sperimentare, ma non puoi usare il modello come motore per il tuo prodotto in maniera completamente libera.
Chi sviluppa questi modelli è perfettamente cosciente di usare il termine open source impropriamente, ma insiste nel farlo come Meta, perché oggi il termine open source è diventato uno strumento di marketing pensato per attirare giovani esperti di AI. Questi professionisti non sono anche esperti di licenze e in gran parte non hanno esperienza nell’uso di tecnologie in grandi aziende e quindi nessuna considerazione per le implicazioni legali del caso.
Alcuni modelli di AI generativa sono realmente open source e permettono un uso commerciale libero. Falcon, sviluppato dal Technology Innovation Institute degli Emirati Arabi Uniti, è l’esempio più performante. Altri modelli come LLama 2, che abbiamo citato più volte, non sono open source, ma permettono l’uso commerciale fintanto che la vostra azienda non raggiunge settecento milioni di utenti attivi al mese.
Qual è il punto? Il punto è che la scelta del modello di AI generativa è una scelta strategica.
Quando prendete questa decisione, considerate il caso d’uso. Quanto è performante il modello? Quanto è facile farne il tuning? E quali sono i termini della licenza che lo accompagna se non state solo facendo sperimentazione? Tutte queste dimensioni contano e considerarle da subito può fare la differenza tra un progetto che è successo e uno destinato a fallire ancora prima di cominciare.
Ci fermiamo qui per questa settimana. Come sempre, scrivetemi i vostri commenti, le domande e i suggerimenti per gli argomenti da trattare nei prossimi episodi.
Ciao!