


Per anni il messaggio dominante nel mondo dell’intelligenza artificiale è stato semplice: per ottenere modelli più potenti servivano infrastrutture sempre più grandi. Oggi il settore sta iniziando a seguire una direzione diversa. Aziende e sviluppatori cercano infatti sistemi capaci di eseguire localmente funzionalità avanzate di ragionamento, comprensione multimodale e automazione, riducendo costi, latenza e dipendenza dal cloud. La possibilità di portare l’AI direttamente sui dispositivi sta così diventando uno dei principali terreni di competizione tra i grandi fornitori di modelli. L’ultima mossa in questa direzione arriva da Google DeepMind con Gemma 4 12B, un modello open source che punta a rendere disponibili capacità multimodali avanzate su laptop e workstation equipaggiati con 16 GB di memoria.
La questione è particolarmente rilevante per le organizzazioni che gestiscono proprietà intellettuale, documentazione riservata, dati finanziari, informazioni sanitarie o altri contenuti soggetti a stringenti requisiti di sicurezza e conformità normativa. In questi contesti la possibilità di elaborare testo, immagini e audio senza trasferire continuamente le informazioni verso infrastrutture esterne rappresenta un vantaggio sempre più importante. È in questo scenario che si inserisce Gemma 4 12B, il nuovo modello open source annunciato da Google DeepMind e progettato per portare capacità multimodali avanzate direttamente sui dispositivi degli utenti.
Gemma 4 12B porta gli agenti AI sui laptop
Gemma 4 12B si colloca all’interno della famiglia Gemma tra il più compatto Gemma E4B, orientato agli scenari edge, e il più potente Gemma 26B basato su architettura Mixture of Experts (MoE). Più che una semplice evoluzione della gamma, il nuovo modello nasce per occupare uno spazio preciso all’interno del portafoglio Google, offrendo capacità di ragionamento e multimodalità vicine a quelle dei modelli di fascia superiore pur mantenendo requisiti compatibili con l’esecuzione su hardware consumer.
L’annuncio arriva mentre l’ecosistema Gemma continua a crescere rapidamente. Secondo Google, i modelli della famiglia hanno superato quota 150 milioni di download, trovando applicazione in progetti che spaziano dalla robotica assistiva ai sistemi di sicurezza informatica per le imprese. Con Gemma 4 12B l’azienda punta a colmare il divario esistente tra i modelli più leggeri destinati all’edge computing e quelli più potenti orientati a scenari che richiedono maggiori risorse computazionali.
Uno degli aspetti più significativi riguarda il rapporto tra prestazioni e consumo di memoria. I benchmark pubblicati da Google mostrano come Gemma 4 12B riesca ad avvicinarsi in molti casi ai risultati ottenuti da Gemma 4 26B, pur richiedendo meno della metà della memoria complessiva. Nei test GPQA Diamond dedicati al ragionamento scientifico il modello raggiunge un punteggio di 78,8 contro 83,8 della versione 26B, mentre in MMLU Pro ottiene 77,2 rispetto a 81,7. Anche nei benchmark multimodali i risultati sono particolarmente vicini: 94,9 contro 93,3 in DocVQA, 88,4 contro 90,5 in InfoVQA e 69,1 contro 72,5 in MMMU Pro. Prestazioni analoghe emergono inoltre in LiveCodeBench, dedicato alla generazione e comprensione del codice, e nel benchmark MRCR v2.8 per la gestione di contesti molto estesi.
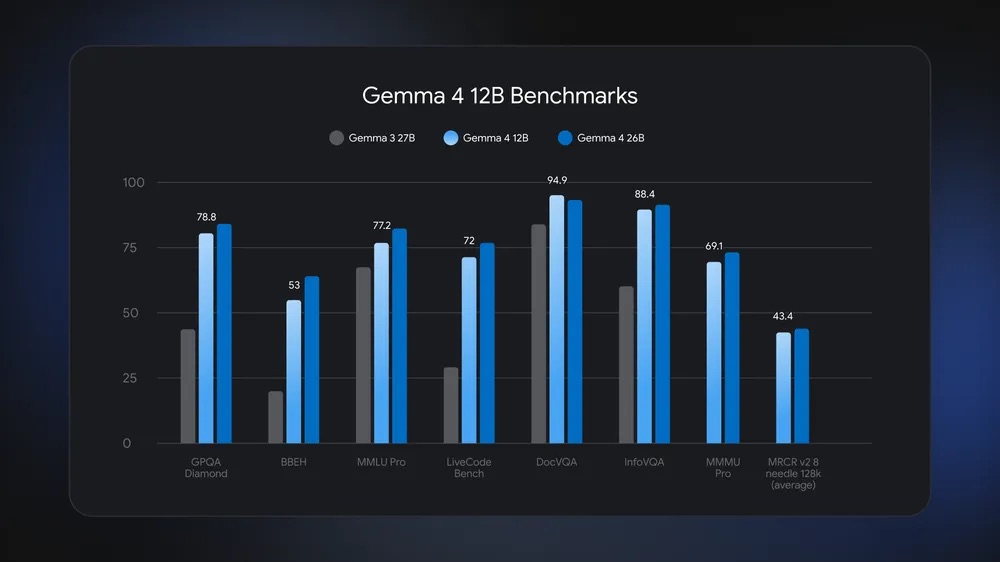
Il confronto con la precedente generazione evidenzia inoltre un salto significativo. In diversi benchmark Gemma 4 12B supera nettamente Gemma 3 27B, in particolare nelle attività di coding, nel ragionamento multimodale e nella comprensione documentale. Questo suggerisce che i miglioramenti architetturali introdotti da Google abbiano consentito di aumentare l’efficienza complessiva del modello, riducendo al tempo stesso i requisiti hardware necessari per l’esecuzione locale.
La soglia dei 16 GB di RAM o memoria unificata assume un valore particolarmente importante perché coincide con la configurazione ormai diffusa nella maggior parte dei notebook professionali di fascia medio-alta. Ciò consente a sviluppatori, ricercatori e team IT di sperimentare applicazioni multimodali avanzate senza dover necessariamente ricorrere a infrastrutture specializzate o a servizi cloud a consumo.
Secondo Google, la combinazione tra prestazioni vicine a quelle di Gemma 26B, supporto multimodale nativo e requisiti hardware relativamente contenuti consente di eseguire localmente agenti AI di livello comparabile allo stato dell’arte attuale. L’obiettivo non è semplicemente portare un modello linguistico sul laptop dell’utente, ma rendere possibile l’esecuzione di workflow agentici complessi direttamente sul dispositivo, riducendo la dipendenza da infrastrutture cloud dedicate.
Google descrive inoltre Gemma 4 12B come un modello progettato specificamente per supportare applicazioni di agentic AI, nelle quali il sistema combina comprensione multimodale, ragionamento e capacità operative all’interno di workflow autonomi. L’obiettivo è consentire la realizzazione di agenti capaci di elaborare informazioni provenienti da testo, immagini e audio direttamente sul dispositivo dell’utente, riducendo la necessità di ricorrere continuamente a servizi cloud esterni.
Addio agli encoder: testo, immagini e audio in un unico modello
L’elemento tecnologicamente più interessante di Gemma 4 12B è probabilmente la sua natura di modello multimodale unificato. Google presenta infatti il nuovo arrivato come il primo modello di fascia intermedia della famiglia Gemma progettato per elaborare testo, immagini e audio attraverso un’unica architettura, senza fare affidamento sui tradizionali encoder multimodali dedicati. Si tratta di un approccio che punta contemporaneamente a ridurre il consumo di memoria, semplificare la pipeline di elaborazione e diminuire la latenza, rendendo possibile l’esecuzione di funzionalità multimodali avanzate direttamente su hardware consumer.
La maggior parte dei modelli multimodali oggi disponibili si basa infatti su una struttura composta da diversi componenti specializzati: un encoder visivo interpreta le immagini, un encoder audio elabora il parlato e i suoni, mentre il modello linguistico si occupa della comprensione e della generazione del testo. Sebbene efficace, questa impostazione introduce complessità aggiuntiva, aumenta il consumo di memoria e può incidere sulla latenza complessiva del sistema.
Google ha scelto una strada diversa adottando un’architettura definita encoder-free, nella quale l’elaborazione multimodale viene affidata direttamente al backbone del modello linguistico. Nel caso delle immagini, il tradizionale encoder visivo è stato sostituito da un modulo estremamente leggero composto da una singola moltiplicazione matriciale, embedding posizionali e operazioni di normalizzazione. Sarà quindi il transformer principale a occuparsi dell’interpretazione delle informazioni visive.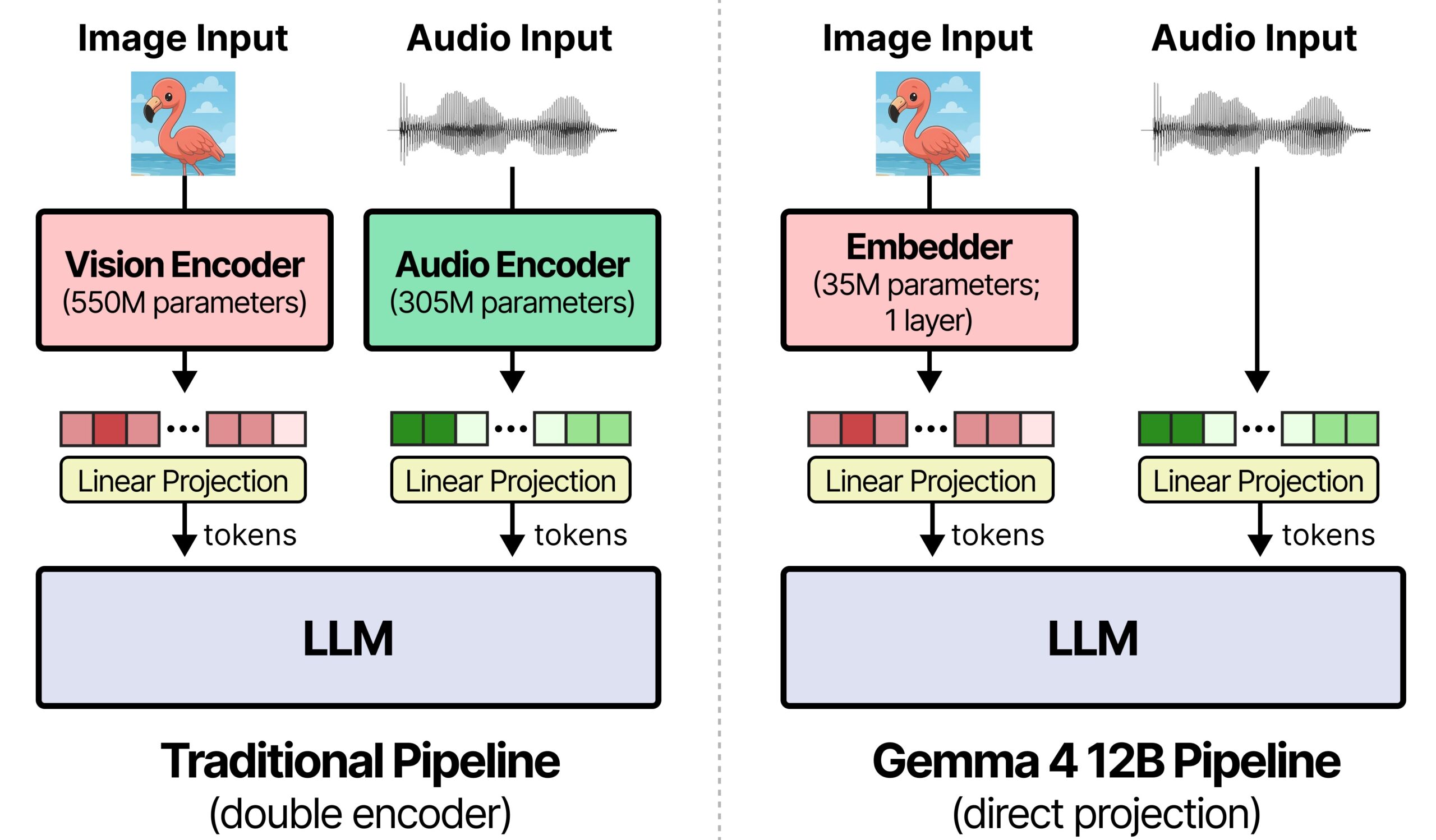
L’approccio è ancora più radicale sul fronte audio. Google ha eliminato completamente l’encoder dedicato e proietta direttamente il segnale sonoro grezzo nello stesso spazio vettoriale utilizzato dai token testuali. In questo modo testo, immagini e audio convergono all’interno di un’unica architettura, riducendo l’occupazione di memoria, semplificando la pipeline di elaborazione e diminuendo la latenza introdotta dai tradizionali passaggi tra componenti specializzati. Per un modello progettato per funzionare su laptop e dispositivi edge, la riduzione dei tempi di elaborazione rappresenta un vantaggio importante tanto quanto il contenimento dei requisiti hardware.
L’audio entra direttamente nel modello
Gemma 4 12B rappresenta inoltre il primo modello di fascia intermedia della famiglia Gemma a integrare il supporto nativo per input audio, una caratteristica che Google considera uno degli elementi distintivi della nuova release. La novità non si limita ad aggiungere una nuova modalità di interazione, ma consente anche di semplificare in modo significativo lo sviluppo delle applicazioni.
Nelle architetture tradizionali, infatti, la gestione della voce richiede spesso l’utilizzo di sistemi speech-to-text separati che convertono l’audio in testo prima di passarlo al modello linguistico. L’integrazione diretta dell’audio riduce invece il numero di componenti necessari, diminuisce la latenza e semplifica l’intera architettura software.
La dimostrazione realizzata attraverso l’applicazione Google AI Edge Eloquent mostra in modo concreto le conseguenze di questo approccio. Gemma 4 12B è infatti in grado di trascrivere, formattare e tradurre contenuti vocali operando interamente offline sul dispositivo locale, utilizzando un unico modello multimodale. Per le aziende questo approccio può risultare particolarmente interessante nei contesti in cui i dati vocali non possono essere trasferiti all’esterno dell’organizzazione o devono essere elaborati in ambienti con connettività limitata.
Ragionamento avanzato e agenti AI eseguiti in locale
Oltre agli aspetti legati alla multimodalità, Google evidenzia le capacità di ragionamento multi-step del modello, che si avvicinerebbero a quelle offerte da Gemma 26B pur mantenendo requisiti hardware significativamente inferiori. L’obiettivo è consentire la realizzazione di workflow agentici complessi, nei quali il modello possa combinare comprensione del linguaggio naturale, analisi di contenuti visivi e sonori, pianificazione di attività e automazione di processi articolati.
La possibilità di eseguire queste funzionalità direttamente sul dispositivo dell’utente apre la strada a una nuova generazione di agenti AI locali, capaci di operare senza dipendere costantemente da servizi cloud esterni. È una direzione che sta acquisendo crescente importanza sia nel mondo enterprise sia nelle applicazioni professionali individuali, dove il controllo sui dati e la prevedibilità dei costi stanno diventando fattori sempre più determinanti nella scelta delle piattaforme AI.
A supportare questa strategia contribuisce anche la presenza dei cosiddetti Multi-Token Prediction Drafters, una tecnologia progettata per ridurre la latenza nella generazione delle risposte. Nei transformer tradizionali ogni token viene prodotto in modo strettamente sequenziale; il meccanismo di Multi-Token Prediction consente invece di anticipare simultaneamente più token, riducendo il numero complessivo di passaggi necessari per generare un output e migliorando così la velocità percepita dall’utente. Gemma 4 12B viene distribuito con i relativi MTP Drafters già disponibili, consentendo agli sviluppatori di sfruttare immediatamente le tecniche di generazione accelerata senza ulteriori interventi di configurazione.
Dalla sperimentazione al deployment in produzione
L’annuncio di Gemma 4 12B non riguarda soltanto il rilascio di un nuovo modello, ma anche la disponibilità di un ecosistema già pronto per lo sviluppo e la distribuzione delle applicazioni. Google punta infatti a ridurre al minimo le barriere all’ingresso per sviluppatori e aziende interessati a sperimentare l’inferenza multimodale locale.
Per le attività di test e prototipazione il modello può essere eseguito con pochi passaggi attraverso strumenti già ampiamente utilizzati dalla comunità AI, tra cui LM Studio, Ollama, Google AI Edge Gallery App, Google AI Edge Eloquent e LiteRT-LM CLI. Gli sviluppatori possono quindi verificare rapidamente le capacità del modello direttamente sul proprio sistema senza dover predisporre infrastrutture dedicate.
Google rende inoltre disponibili i checkpoint preaddestrati e instruction-tuned attraverso piattaforme come Hugging Face e Kaggle, accompagnando il rilascio con documentazione tecnica dettagliata, una guida per sviluppatori e notebook introduttivi pensati per accelerare l’adozione del modello.
Particolare attenzione è stata dedicata anche all’integrazione con gli strumenti già diffusi nell’ecosistema open source. Gemma 4 12B può essere utilizzato con Hugging Face Transformers, llama.cpp, MLX, SGLang e vLLM, mentre per le attività di personalizzazione e fine tuning Google segnala il supporto a Unsloth, piattaforma orientata all’ottimizzazione dell’addestramento con un utilizzo efficiente delle risorse hardware.
La strategia di Google punta esplicitamente a rendere il modello accessibile al più ampio numero possibile di sviluppatori e organizzazioni, indipendentemente dall’infrastruttura utilizzata. Il supporto ai principali framework open source, agli ambienti di inferenza locale e agli strumenti di deployment cloud riflette la volontà di favorire l’adozione di Gemma 4 12B in contesti molto diversi, dalla sperimentazione individuale fino alle implementazioni enterprise.
L’azienda punta inoltre a facilitare l’adozione del modello da parte della comunità di sviluppatori attraverso un ecosistema di strumenti e risorse già consolidato. Oltre alla distribuzione con licenza Apache 2.0, Gemma 4 12B viene accompagnato da documentazione tecnica dedicata che approfondisce i dettagli dell’architettura multimodale e le modalità di integrazione nelle applicazioni.
Per favorire lo sviluppo di applicazioni agentiche, Google ha inoltre annunciato il nuovo Gemma Skills Repository, un archivio ufficiale di skill e componenti riutilizzabili progettati specificamente per sfruttare le più recenti funzionalità della famiglia Gemma. L’obiettivo è accelerare la costruzione di agenti AI capaci di integrare strumenti, workflow e funzionalità avanzate senza dover sviluppare ogni componente da zero.
La strategia non si limita tuttavia all’esecuzione locale. Per i progetti che richiedono maggiore scalabilità o distribuzioni enterprise, Gemma 4 12B può essere implementato anche attraverso l’infrastruttura cloud di Google utilizzando Gemini Enterprise Agent Platform Model Garden, Cloud Run e Google Kubernetes Engine (GKE), consentendo alle organizzazioni di adottare architetture ibride nelle quali sviluppo e sperimentazione avvengono localmente mentre il deployment in produzione viene gestito attraverso servizi cloud.
La sfida dei modelli aperti si sposta sull’edge
Come il resto della famiglia Gemma, anche il nuovo modello viene distribuito con licenza Apache 2.0, una scelta che ne favorisce l’adozione in contesti commerciali e industriali. La disponibilità di un modello multimodale relativamente compatto, aperto e progettato per funzionare su hardware consumer evidenzia una strategia più ampia perseguita da Google. Se da una parte Gemini continua a rappresentare la piattaforma di punta per il cloud AI, dall’altra Gemma sta assumendo un ruolo sempre più importante nel segmento dei modelli aperti destinati all’esecuzione locale.
Si tratta di un mercato in forte fermento, nel quale Google si trova a competere con iniziative come Llama di Meta, Qwen di Alibaba, Mistral e Phi di Microsoft, tutte accomunate dall’obiettivo di rendere disponibili capacità di intelligenza artificiale avanzata senza richiedere necessariamente l’accesso a infrastrutture cloud proprietarie. In questo contesto Gemma 4 12B rappresenta qualcosa di più di un semplice aggiornamento della famiglia Gemma: è un ulteriore passo verso una generazione di sistemi AI progettati per funzionare direttamente sui dispositivi degli utenti, trasformando laptop e workstation in piattaforme autonome per l’esecuzione di agenti intelligenti multimodali. Più che aumentare le dimensioni dei modelli, l’obiettivo sembra essere quello di portare capacità multimodali avanzate su hardware di uso quotidiano, rendendo accessibili funzionalità che fino a poco tempo fa richiedevano workstation specializzate o infrastrutture cloud dedicate.






{kind=link}