


Google Cloud inaugura l’era dell’inferenza con Ironwood, la settima generazione di TPU, e con le nuove CPU Axion basate su Arm. Due architetture co-progettate per AI Hypercomputer che uniscono accelerazione, efficienza e scalabilità, portando l’intelligenza artificiale a livello planetario.
Google Cloud apre un nuovo capitolo nella storia del calcolo su larga scala con il lancio di tre prodotti costruiti su silicio proprietario, progettati per affrontare l’esplosione della domanda di potenza computazionale nell’era dell’inferenza e dei flussi di lavoro agentici. In un contesto in cui i modelli più avanzati – da Gemini a Veo, da Imagen a Claude – vengono addestrati e gestiti su Tensor Processing Unit (TPU), l’attenzione delle imprese si sposta sempre più dalla fase di training verso quella dell’interazione continua, dinamica e produttiva con i modelli.
Questa nuova fase, definita dall’evoluzione dei modelli di frontiera, dalla crescita esponenziale della domanda di calcolo e dall’affermarsi dei workload agentici che richiedono coordinamento stretto tra compute general-purpose e accelerazione ML, apre la strada a un’architettura completamente co-ottimizzata tra hardware e software. È su questa base che Google introduce Ironwood, la settima generazione di TPU, e due nuove istanze Axion basate su Arm: N4A e C4A metal, entrambe sviluppate per offrire efficienza, prestazioni e scalabilità superiori in ogni scenario di AI moderno.
Ironwood: la TPU più potente ed efficiente mai costruita da Google

Ironwood è progettata per i carichi di lavoro più impegnativi: dall’addestramento su larga scala dei modelli generativi all’inferenza ad altissimo volume e bassa latenza. Rispetto alla generazione precedente, TPU v6e (Trillium), offre oltre quattro volte le prestazioni per chip in training e inference, e un incremento massimo di potenza di dieci volte rispetto a TPU v5p.
Frutto di un decennio di co-progettazione tra ricerca sui modelli, sviluppo software e architettura hardware, Ironwood rappresenta l’apice della filosofia di Google: costruire processori in grado di garantire breakthrough di performance possibili solo grazie a un’integrazione profonda tra livelli. Lo stesso approccio che, dieci anni fa, portò alla creazione della prima TPU e, otto anni dopo, alla nascita dell’architettura Transformer — la base di tutta l’AI moderna.
Ironwood eredita anche i progressi della tecnologia Titanium e delle soluzioni di raffreddamento a liquido implementate su scala di Gigawatt, con una disponibilità media del 99,999% dal 2020. Ogni scheda Ironwood integra tre TPU collegate in un unico dominio di liquid cooling, mentre le nuove Cooling Distribution Units di terza generazione assicurano un raffreddamento uniforme e sostenibile nei superpod più estesi.
La via più rapida dal training all’inferenza planetaria
Le prime reazioni da parte dei partner confermano l’impatto dell’architettura. Anthropic, sviluppatore dei modelli Claude, ha annunciato che potrà accedere fino a un milione di TPU Ironwood, con un incremento significativo dell’efficienza e una riduzione dei costi di inferenza. “Ironwood ci aiuterà a scalare in modo efficiente mantenendo la velocità e l’affidabilità che i nostri clienti si aspettano”, afferma James Bradbury, Head of Compute di Anthropic.
Anche Lightricks, società che sviluppa soluzioni creative basate su AI generativa, ha riscontrato un salto qualitativo. “Il nostro obiettivo è definire il futuro della creatività aperta, e questo richiede infrastrutture AI prive di attriti e con costi ottimizzati. I primi test di Ironwood mostrano risultati entusiasmanti: crediamo che ci permetterà di ottenere generazioni di immagini e video ancora più precise e fedeli”, dichiara Yoav HaCohen, Research Director di Lightricks.
Per Essential AI, che lavora su modelli open frontier, Ironwood è sinonimo di semplicità e potenza. “La piattaforma è stata incredibilmente semplice da adottare, consentendo ai nostri ingegneri di sfruttarne subito le capacità e concentrarsi sull’innovazione”, spiega Philip Monk, Infrastructure Lead dell’azienda.
Scalabilità estrema e affidabilità continua
Ironwood è parte integrante di AI Hypercomputer, il sistema iper-integrato di Google Cloud che combina compute, networking, storage e software per massimizzare efficienza e prestazioni a livello di sistema. Secondo un recente studio IDC, i clienti AI Hypercomputer hanno registrato un ROI triennale medio del 353%, una riduzione del 28% dei costi IT e un miglioramento del 55% dell’efficienza dei team.
Le TPU Ironwood permettono di collegare fino a 9.216 chip in un unico superpod grazie a una rete Inter-Chip Interconnect da 9,6 Tb/s, con 1,77 petabyte di memoria HBM condivisa. Questa architettura consente un’elaborazione continua senza colli di bottiglia, ideale per i modelli più estesi e complessi.
A livello infrastrutturale, la rete Optical Circuit Switching funge da tessuto riconfigurabile dinamico che instrada automaticamente il traffico in caso di guasti, mantenendo i servizi attivi senza interruzioni. Quando serve ancora più potenza, i superpod Ironwood si uniscono in cluster composti da centinaia di migliaia di TPU, connessi dal backbone Jupiter, la rete dati-center-wide di Google.

Co-design hardware e software per un’AI più efficiente
Sopra questa base hardware opera uno strato software co-progettato per sfruttare appieno la potenza di elaborazione e memoria di Ironwood lungo tutto il ciclo di vita dell’AI.
Tra le novità, Cluster Director in Google Kubernetes Engine introduce manutenzione intelligente, consapevolezza topologica e scheduling resiliente per ottimizzare le flotte TPU. Inoltre, gli aggiornamenti a MaxText, framework open source per LLM ad alte prestazioni, semplificano l’implementazione di tecniche avanzate di training come Supervised Fine-Tuning (SFT) e Generative Reinforcement Policy Optimization (GRPO).
Sul fronte inferenza, l’integrazione di vLLM e GKE Inference Gateway consente di alternare GPU e TPU con minime modifiche di configurazione e di ridurre la latenza time-to-first-token fino al 96%, abbattendo i costi di serving del 30%. Questo ecosistema software-hardware co-progettato è ciò che permette a AI Hypercomputer di garantire prestazioni elevate e affidabilità in tutti i carichi di lavoro AI più esigenti.
Axion: la CPU Arm che ridefinisce il compute general-purpose

Parallelamente all’evoluzione delle TPU, Google amplia il proprio ecosistema con Axion, la famiglia di CPU basata su Arm Neoverse, pensata per combinare prestazioni, costi e sostenibilità nelle operazioni quotidiane e nei workload complementari all’AI.
Con l’introduzione di N4A, ora in anteprima, e C4A metal, prossimamente disponibile, la linea Axion copre un ampio spettro di casi d’uso. N4A rappresenta la VM della serie N più economica e flessibile mai realizzata da Google, ideale per microservizi, container, database open source, batch, analytics e ambienti di sviluppo. Offre fino a 64 vCPU, 512 GB di memoria DDR5 e 50 Gbps di networking.
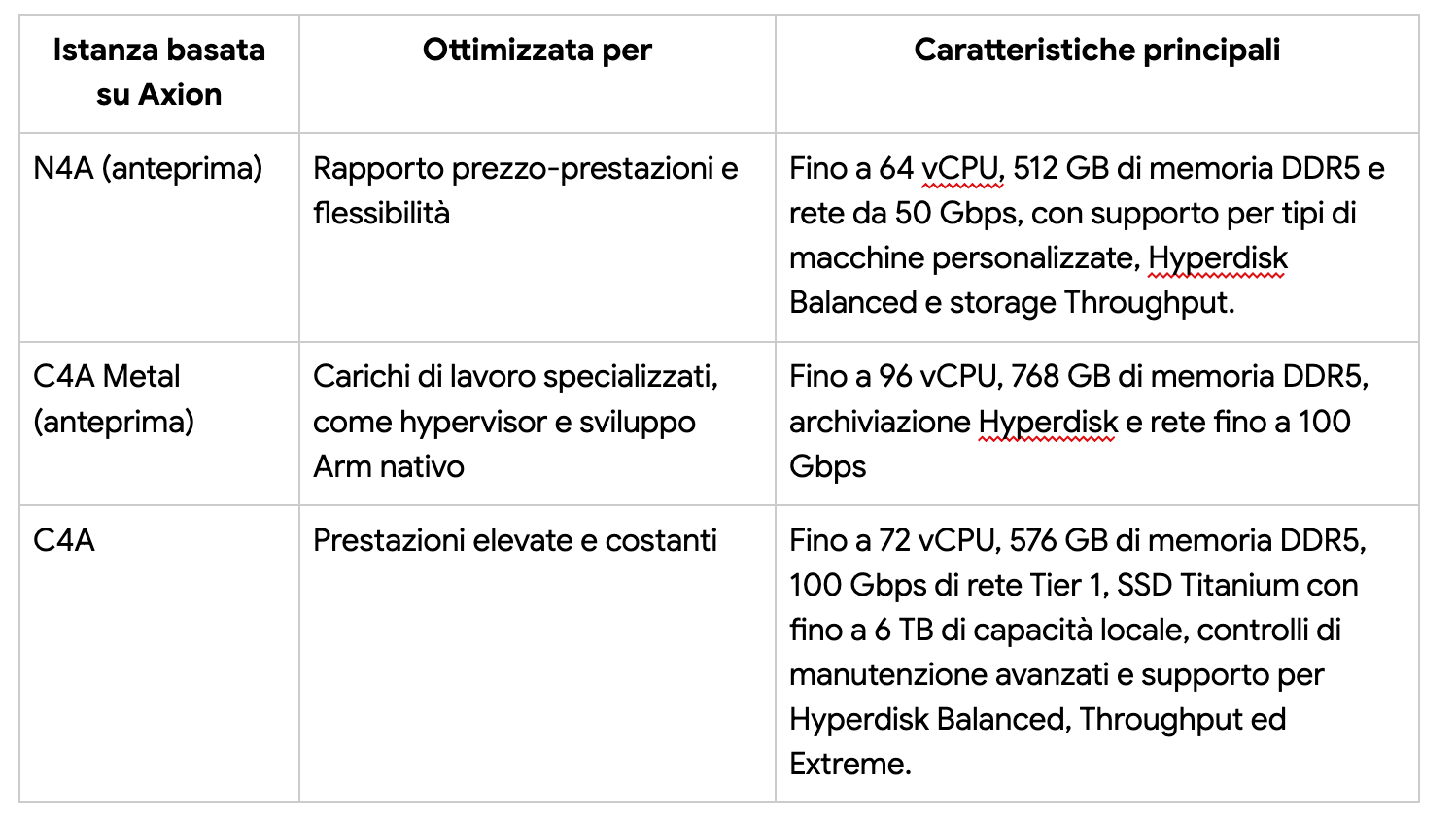
C4A metal, la prima istanza bare-metal Arm di Google, fornisce server fisici dedicati per workload specializzati come sviluppo Android, sistemi automotive, software con licenze vincolate o simulazioni complesse, con configurazioni fino a 96 vCPU, 768 GB di memoria DDR5 e 100 Gbps di rete. La serie C4A standard, già consolidata, mantiene invece le massime prestazioni costanti grazie a connessioni di rete Tier 1 e storage Titanium SSD fino a 6 TB.
L’efficienza di Axion lo rende anche un alleato naturale nei flussi di lavoro AI moderni. Mentre Ironwood gestisce il calcolo pesante di addestramento e inferenza, Axion fornisce la spina dorsale operativa per data preparation, ingestion e hosting di applicazioni intelligenti.
Efficienza comprovata e impatto reale
Le prime implementazioni confermano l’efficacia della nuova generazione Axion. Vimeo, che da tempo utilizza le Custom Machine Types di Google per la gestione della propria piattaforma di transcoding video, ha registrato un miglioramento del 30% nelle prestazioni con le nuove istanze N4A rispetto alle VM x86 equivalenti. “Abbiamo individuato un chiaro percorso per migliorare l’economia operativa e scalare i servizi in modo più redditizio, senza modificare il nostro modello di gestione”, ha commentato Joe Peled, Senior Director of Hosting & Delivery Operations di Vimeo.
Con Ironwood e Axion, Google Cloud consolida così una visione che unisce accelerazione specializzata e compute general-purpose, integrando hardware, rete e software in un unico paradigma scalabile. È la prosecuzione naturale di una strategia che, dalla prima TPU alla piattaforma Hypercomputer, ha trasformato il calcolo in un motore planetario per l’intelligenza artificiale.






{kind=link}