


Ridurre il costo dell’inferenza sta diventando uno degli obiettivi principali dei fornitori di infrastrutture AI. Con la diffusione di agenti, copiloti e applicazioni generative, il problema non è più soltanto addestrare modelli sempre più potenti, ma eseguirli milioni di volte al giorno mantenendo sostenibili costi, prestazioni e governance. È in questa direzione che si muove Lenovo con l’espansione della piattaforma Hybrid AI Advantage, arricchita con nuove soluzioni dedicate all’inferenza e all’AI agentica.
La centralità dell’inferenza emerge anche dalle priorità di investimento delle imprese. Nel Lenovo CIO Playbook 2026, realizzato con il contributo di IDC, il 94% delle organizzazioni dichiara di prevedere un aumento degli investimenti in intelligenza artificiale nel prossimo anno, segno del passaggio dalla fase di sperimentazione alla ricerca di risultati di business misurabili.

Le nuove piattaforme sono progettate per eseguire i modelli dove i dati vengono prodotti e utilizzati, distribuendo i carichi di lavoro tra PC AI, workstation, server on-premise e cloud ibrido. Questo approccio prende forma nella Hybrid AI Factory di Lenovo, un modello architetturale che consente di portare l’inferenza vicino ai dati e ai processi di business. Secondo l’azienda, questa impostazione permette di migliorare prestazioni e latenza, mantenere il controllo su sicurezza e governance e ridurre il costo dell’inferenza, destinato a rappresentare una quota sempre più rilevante della spesa operativa legata all’intelligenza artificiale.
La principale novità è l’introduzione di nuove piattaforme sviluppate insieme a Intel, NVIDIA, Red Hat e Canonical, pensate per ottimizzare i carichi di inferenza e semplificare l’adozione dell’AI agentica. L’offerta comprende piattaforme per l’AI privata, strumenti per distribuire agenti AI e configurazioni dedicate ai diversi livelli di maturità delle organizzazioni.

“Le aziende stanno superando la fase della semplice sperimentazione per esigere risultati di business concreti e misurabili”, osserva Ashley Gorakhpurwalla, President of Infrastructure Solutions di Lenovo. “La nostra missione è migliorare drasticamente l’economia dei token, accelerare il time-to-value e garantire fiducia, sicurezza e governance”.
Piattaforme ottimizzate per l’inferenza
Tra le novità figura una versione della Lenovo Hybrid AI Platform progettata specificamente per l’inferenza basata su CPU. La piattaforma combina Red Hat AI Enterprise con i nuovi processori Intel Xeon 6, dotati di accelerazione AI integrata, ed è pensata per carichi di lavoro come Retrieval-Augmented Generation (RAG), assistenti per le risorse umane e customer service. Secondo Lenovo, questa configurazione è in grado di gestire circa il doppio delle richieste AI simultanee rispetto alle soluzioni precedenti, migliorando throughput, latenza e tempo di risposta iniziale del modello (time-to-first-token).
Accanto a questa soluzione debutta una nuova piattaforma disponibile in due configurazioni. La prima, sviluppata con Canonical, utilizza Ubuntu e Kubernetes per offrire un ambiente orientato allo sviluppo e alla distribuzione rapida di applicazioni AI private, copiloti e agenti, con particolare attenzione all’efficienza dei costi e alla sovranità dei dati. La seconda, basata su Red Hat Enterprise, è invece destinata alle organizzazioni che devono gestire ambienti di produzione, con strumenti per il ciclo di vita dei modelli, la scalabilità e la governance dei carichi di inferenza e dell’AI agentica.
Le due configurazioni rispondono a esigenze differenti. La soluzione Canonical privilegia rapidità di sviluppo ed efficienza dei costi, mentre quella basata su Red Hat Enterprise introduce strumenti per la gestione del ciclo di vita dei modelli e degli ambienti di produzione. In entrambi i casi, l’obiettivo è distribuire i modelli tra data center e cloud ibrido mantenendo il controllo su dati, sicurezza e governance.
Fino a otto volte meno per ogni token
Il tema economico è centrale nell’intero annuncio. Lenovo cita una ricerca IDC secondo cui il 92% delle organizzazioni che implementano soluzioni di AI agentica vede i costi finali superare le aspettative. Il tema si inserisce nella crescente attenzione verso la Token Economics, la disciplina che misura come il consumo dei token da parte dei modelli AI si traduca in costi operativi e risultati di business.
Per i carichi di lavoro più intensivi, Lenovo stima una riduzione del costo per token fino a otto volte rispetto a infrastrutture cloud IaaS tradizionali e fino a 18 volte per milione di token rispetto ai servizi MaaS (Model-as-a-Service). Si tratta di valori ottenuti combinando inferenza ottimizzata su CPU, infrastrutture scalabili e distribuzione dei modelli lungo l’intero ambiente ibrido, con l’obiettivo di rendere economicamente sostenibile l’esecuzione continuativa degli agenti AI nelle applicazioni aziendali.

La stessa lettura emerge dalle parole di Per Overgaard, Executive Director Infrastructure Solutions Group per Europa e Medio Oriente di Lenovo: “Le aziende hanno già dimostrato il valore dell’AI attraverso progetti pilota, ma portarla su scala richiede un approccio diverso in termini di costi, governance e controllo dei dati. Il focus si sta spostando dal massimizzare il numero di token al massimizzare i risultati”.
AI agentica: dagli assistenti agli agenti autonomi
Accanto alle piattaforme di inferenza, Lenovo amplia anche il portafoglio dedicato all’AI agentica, con l’obiettivo di semplificare la distribuzione di agenti AI all’interno delle infrastrutture aziendali. L’azienda introduce un modello di implementazione definito “one-click”, pensato per accelerare il passaggio dalla sperimentazione all’utilizzo operativo senza richiedere complesse attività di integrazione.
Le nuove funzionalità coprono diversi ambiti applicativi. Tra queste figura Knowledge Super Agent, un assistente in grado di interrogare e sintetizzare informazioni provenienti da sistemi aziendali differenti attraverso un’unica interfaccia, riducendo il tempo necessario per reperire documenti e dati distribuiti. Sul fronte delle operation IT, Lenovo sta inoltre sviluppando funzionalità basate su NVIDIA NemoClaw per automatizzare il rilevamento delle anomalie, supportare la diagnosi dei problemi e accelerarne la risoluzione, riducendo gli interventi manuali dei team IT.
L’azienda prevede inoltre di sviluppare insieme ai clienti nuovi agenti autonomi destinati a eseguire attività articolate su più passaggi, supportando processi decisionali e workflow complessi con un intervento umano limitato principalmente alla supervisione. Per favorire l’adozione di queste tecnologie vengono introdotti anche gli ambienti personali di AI Factory sulla workstation ThinkStation PGX, che offrono agli sviluppatori un ambiente preconfigurato per realizzare, testare e distribuire applicazioni agentiche utilizzando i blueprint di NVIDIA NemoClaw.
Dal proof of concept alla produzione
Secondo Lenovo, la ThinkStation PGX rappresenta il punto di partenza dell’intero percorso di sviluppo. Le applicazioni possono essere progettate e validate sulla workstation locale per poi essere trasferite senza modifiche sostanziali su sistemi ThinkStation PX o su infrastrutture enterprise di dimensioni maggiori. L’obiettivo è ridurre il tempo necessario per trasformare un proof of concept in un’applicazione destinata alla produzione, mantenendo la stessa architettura software lungo tutte le fasi del progetto.
Tra i primi casi d’uso illustrati compare il settore retail, dove Lenovo immagina chioschi intelligenti in grado di assistere i clienti nella ricerca dei prodotti, verificare la disponibilità a magazzino, suggerire promozioni e fornire informazioni personalizzate. Per gli operatori della distribuzione, questi sistemi dovrebbero alleggerire il carico di lavoro del personale e migliorare l’efficienza operativa del punto vendita.
Sicurezza e governance lungo l’intero ciclo di vita
La diffusione dell’AI agentica rende centrale anche il tema della governance. Lenovo afferma di adottare un approccio “Trust by Design”, che integra sicurezza, controllo e conformità nell’intera infrastruttura, mantenendo la supervisione umana lungo tutto il ciclo di vita delle applicazioni AI, dalla sperimentazione iniziale fino all’esecuzione autonoma degli agenti.
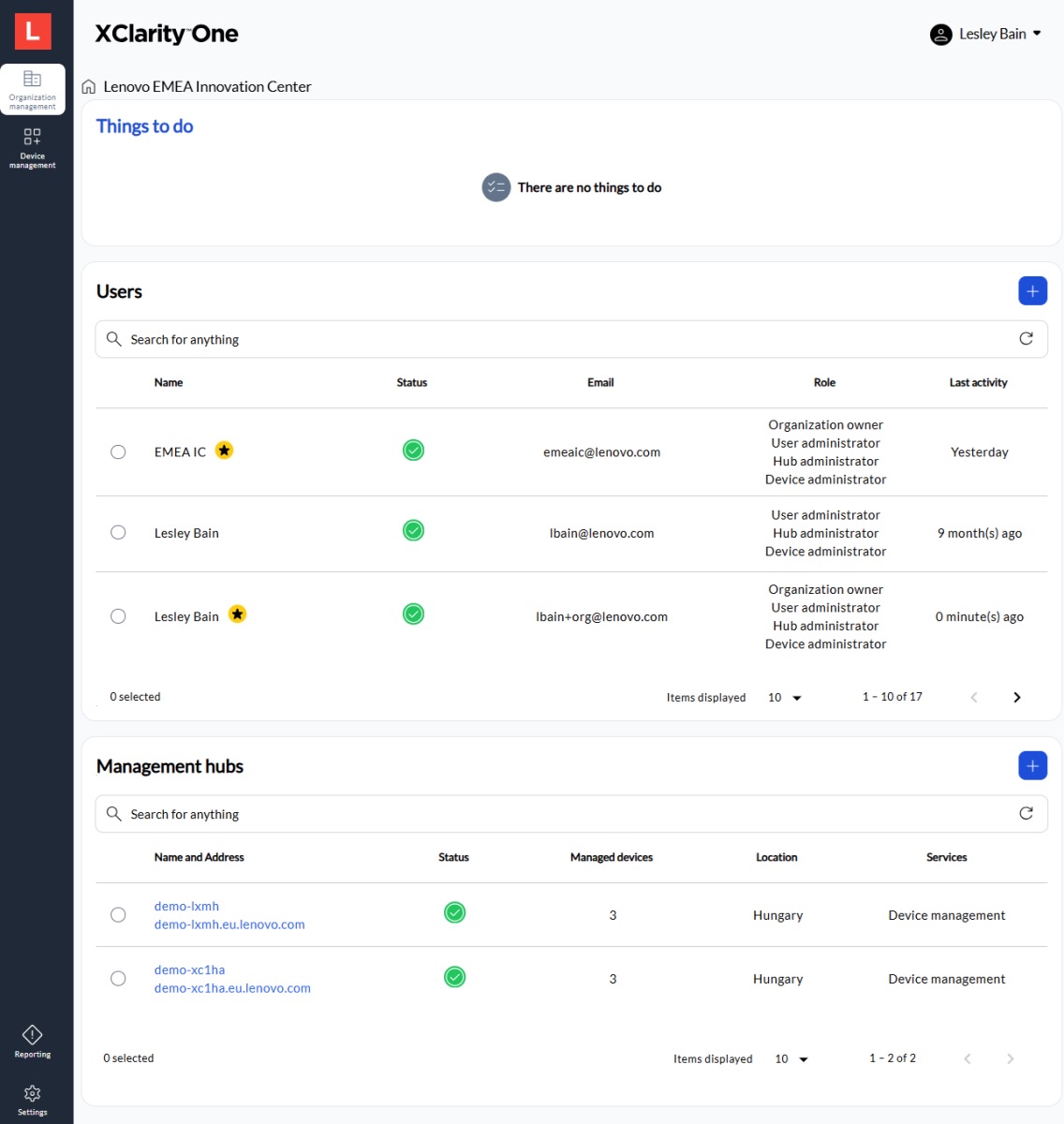
Tra le novità rientrano Nutanix Compute Only Cluster per la virtualizzazione basata su CPU, la piattaforma Lenovo XClarity One per la gestione unificata secondo un modello zero trust e una serie di protezioni hardware dedicate alla supply chain e alla root of trust. L’obiettivo dichiarato è offrire alle organizzazioni strumenti per scalare l’intelligenza artificiale mantenendo il controllo sui dati, sulla sicurezza e sui requisiti di conformità normativa.
Un’infrastruttura pensata per l’economia dell’inferenza
Con queste novità Lenovo rafforza la propria strategia di Hybrid AI, che punta a distribuire l’intelligenza artificiale lungo l’intero continuum infrastrutturale, dai dispositivi edge ai data center fino al cloud. Più che aumentare la potenza di calcolo disponibile, l’obiettivo è migliorare l’efficienza con cui i modelli vengono eseguiti durante l’attività quotidiana, una fase destinata ad assumere un peso crescente con la diffusione di agenti AI autonomi e applicazioni generative integrate nei processi aziendali.
La scelta riflette un’evoluzione ormai evidente nel mercato enterprise. Se la prima fase della corsa all’intelligenza artificiale era stata dominata dalla disponibilità di GPU e dall’addestramento dei modelli, oggi l’attenzione si concentra sempre più sull’inferenza: la capacità di eseguire milioni di richieste ogni giorno mantenendo sotto controllo costi, tempi di risposta, sicurezza e governance. In questo scenario, l’infrastruttura diventa un elemento competitivo tanto quanto il modello linguistico utilizzato, perché determina la sostenibilità economica dell’AI quando passa dalla sperimentazione all’operatività quotidiana.






{kind=link}