


Dopo quasi tre settimane di sospensione, Claude Fable 5 torna disponibile a livello globale da oggi, 1° luglio. La decisione segue la revoca delle restrizioni all’esportazione imposte dal governo degli Stati Uniti il 12 giugno, che avevano costretto Anthropic a interrompere l’accesso sia a Fable 5 sia a Claude Mythos 5, non disponendo di un sistema in grado di verificare in tempo reale la nazionalità degli utenti.
La riattivazione interessa Claude.ai, Claude Platform, Claude Code e Claude Cowork, mentre il ripristino sulle piattaforme cloud di AWS, Google Cloud e Microsoft Foundry avverrà progressivamente. Più limitata rimane invece la disponibilità di Mythos 5, che, dopo l’autorizzazione concessa dal governo statunitense il 26 giugno, è stato nuovamente abilitato soltanto per un gruppo ristretto di organizzazioni americane già coinvolte nel programma Project Glasswing, dedicato alla cybersecurity difensiva.
Oltre al ripristino dell’accesso ai modelli, Anthropic presenta una serie di iniziative che vanno oltre la gestione del singolo episodio. L’azienda propone un framework condiviso per classificare la gravità dei jailbreak, descrive nel dettaglio la propria architettura di sicurezza e definisce un programma di collaborazione strutturata con il governo statunitense per la valutazione dei futuri modelli di frontiera. Nel loro insieme, queste misure delineano un approccio destinato a incidere più in generale sulla sicurezza e sulla governance dei sistemi di intelligenza artificiale più avanzati.
Perché Fable 5 era stato bloccato
La sospensione dei due modelli era stata disposta dopo che il governo statunitense era venuto a conoscenza di un rapporto realizzato da ricercatori di Amazon, nel quale veniva descritta una tecnica capace di aggirare alcune protezioni di Fable 5. Attraverso particolari sequenze di prompt, il modello riusciva a identificare diverse vulnerabilità software e, in un caso, a generare codice dimostrativo che ne illustrava il possibile sfruttamento.
Secondo Anthropic, le verifiche condotte nelle settimane successive hanno però modificato il quadro iniziale. L’azienda sostiene che il comportamento osservato non mettesse in evidenza capacità offensive esclusive di Fable 5 né, soprattutto, quelle di Mythos 5. Anthropic ricorda inoltre che Fable 5 e Mythos 5 condividono lo stesso modello di base e si differenziano principalmente per il diverso livello di protezioni applicato: Mythos 5 è riservato ai partner del programma Project Glasswing per attività di cybersecurity difensiva ed è stato distribuito con un numero inferiore di guardrail rispetto a Fable 5.
I test interni avrebbero inoltre mostrato che altri modelli ampiamente disponibili, tra cui Claude Opus 4.8, GPT-5.5 e Kimi K2.7, erano in grado di individuare le stesse vulnerabilità e di produrre dimostrazioni analoghe dello sfruttamento del caso analizzato. Per Anthropic, quindi, il problema non riguardava capacità offensive esclusive del modello, ma il comportamento dei meccanismi di sicurezza incaricati di distinguere le richieste legittime da quelle potenzialmente pericolose.
Questa conclusione ha portato l’azienda a intervenire non sul modello in sé, ma sui sistemi che ne controllano l’utilizzo. Anthropic ha addestrato una versione aggiornata del proprio classificatore di sicurezza che, secondo quanto dichiarato, blocca oltre il 99% dei tentativi di riprodurre la tecnica descritta nel rapporto di Amazon. Quando una richiesta viene bloccata dal classificatore, l’utente viene informato e la richiesta viene automaticamente inoltrata a Claude Opus 4.8, che applica un diverso profilo di sicurezza.
I classifier diventano il centro della strategia di sicurezza
La risposta di Anthropic al caso Fable 5 non si limita a correggere il comportamento segnalato da Amazon. L’azienda descrive un’architettura di sicurezza costruita secondo un principio di defense in depth, nella quale più livelli di protezione intervengono in momenti diversi dell’interazione con il modello.
Una parte di questi controlli deriva dall’addestramento del modello, progettato per rifiutare le richieste chiaramente dannose. Un’altra opera invece durante l’utilizzo del servizio attraverso classifier dedicati, cioè sistemi automatici di dimensioni ridotte che analizzano in tempo reale sia le richieste degli utenti sia gli output generati dal modello. Quando un contenuto viene classificato come potenzialmente pericoloso, il sistema impedisce al modello di rispondere oppure blocca la risposta prima che venga restituita all’utente.
Questo meccanismo assume un’importanza particolare nella cybersecurity, dove la distinzione tra uso legittimo e uso offensivo è spesso sfumata. Una richiesta di individuazione di vulnerabilità, per esempio, può rientrare in un’attività di audit, ricerca o difesa, ma può anche rappresentare una fase preliminare di un attacco. Per questo Anthropic afferma di non voler bloccare tutte le attività di cyberdefense a basso rischio, ma soltanto quelle che potrebbero produrre effetti potenzialmente dannosi.
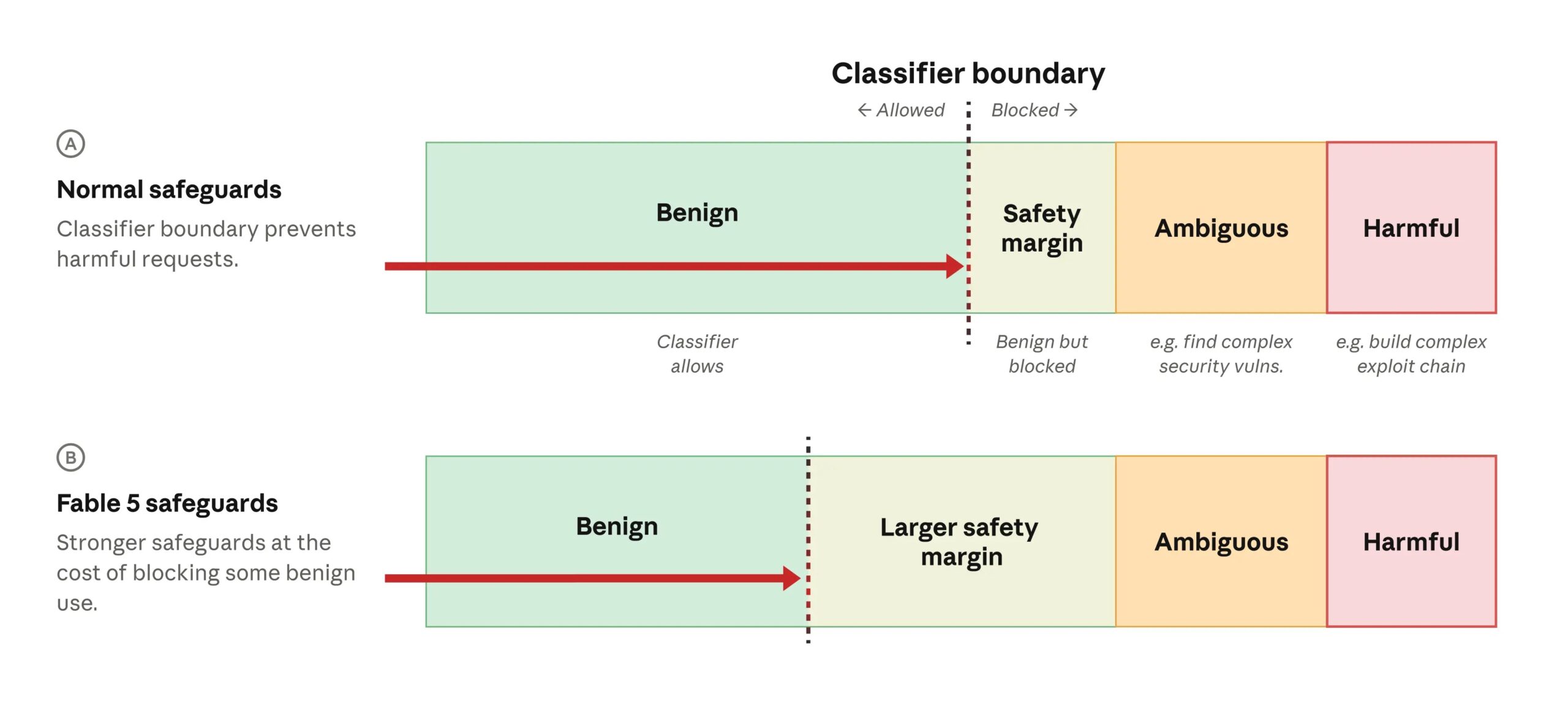
Il punto tecnico più significativo riguarda il safety margin. I classifier di Fable 5 sono configurati per bloccare non solo le richieste chiaramente offensive, ma anche una parte di quelle probabilmente legittime quando ricadono in un’area di rischio. In altre parole, una richiesta deve apparire chiaramente sicura per superare il filtro; se rimane in una zona ambigua, viene bloccata.
Rispetto ai modelli precedenti, Anthropic ha ampliato questo margine più che in qualsiasi altro rilascio. La conseguenza è un aumento dei falsi positivi: attività ordinarie di programmazione, debugging o analisi del codice possono essere respinte anche quando non hanno finalità malevole. L’azienda riconosce esplicitamente questo compromesso e afferma di averlo scelto deliberatamente: preferisce bloccare alcune richieste innocue piuttosto che restringere il safety margin e aumentare la probabilità che un jailbreak riesca a ottenere comportamenti realmente pericolosi.
La versione aggiornata del classificatore introdotta dopo il rapporto di Amazon rafforza ulteriormente questo approccio. Secondo Anthropic, la tecnica segnalata viene ora bloccata in oltre il 99% dei casi. Nella quota residua il modello può ancora produrre informazioni, ma non sufficientemente dettagliate da risultare utili a un attaccante. L’azienda aggiunge inoltre che i ricercatori del Center for AI Standards and Innovation (CAISI) del Dipartimento del Commercio statunitense hanno testato sia le protezioni precedenti sia quelle aggiornate, giudicandole particolarmente robuste.
Il rafforzamento dei classifier introduce però anche un inevitabile compromesso operativo. Più il margine di sicurezza viene ampliato, maggiore è il numero di richieste legittime intercettate per errore. Anthropic afferma che continuerà a perfezionare questi sistemi per ridurre i falsi positivi e distinguere meglio tra uso lecito, uso ambiguo e tentativi reali di abuso. Il bilanciamento tra sicurezza e usabilità diventa così uno degli elementi centrali nella distribuzione dei modelli di frontiera.
Dal bypass al jailbreak: perché non tutti gli aggiramenti hanno la stessa gravità
Anthropic propone di valutare i jailbreak non in base alla loro semplice esistenza, ma in funzione delle capacità che riescono effettivamente a sbloccare. Tecniche diverse possono produrre livelli di gravità molto differenti e richiedono quindi risposte proporzionate.
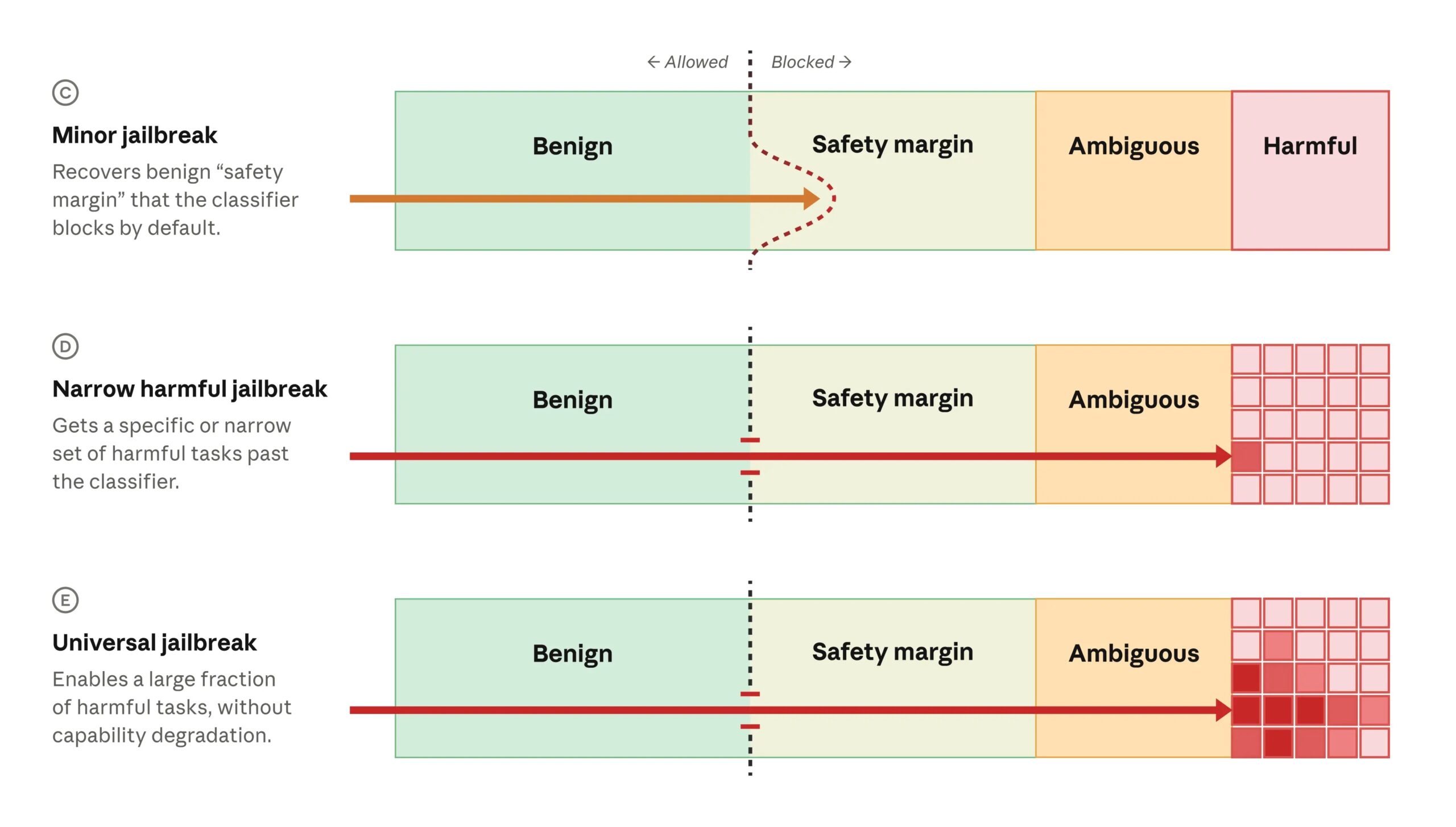
La prima categoria è quella dei minor jailbreak. In questi casi il prompt riesce ad aggirare il classifier, ma il comportamento ottenuto resta all’interno del margine di sicurezza. Il modello può quindi produrre contenuti che il sistema avrebbe preferito bloccare per prudenza, senza però dare accesso a capacità realmente pericolose. Anthropic riconduce a questa categoria i jailbreak di Fable 5 segnalati finora.
La seconda categoria è quella dei narrow harmful jailbreak. Qui l’aggiramento supera il margine di sicurezza e consente di ottenere uno specifico comportamento dannoso. La gravità aumenta, ma resta limitata dalla portata circoscritta della tecnica: il jailbreak funziona per un determinato obiettivo, una specifica procedura o una singola famiglia di attività, senza aprire l’intero spettro delle capacità offensive del modello.
La categoria più critica è quella degli universal jailbreaks, nei quali una tecnica permette di sbloccare un’intera classe di comportamenti dannosi. Sono gli scenari più preoccupanti perché riducono drasticamente il costo di accesso alle capacità vietate e possono essere riutilizzati in un ampio numero di contesti. Anthropic afferma che, al momento della pubblicazione del documento, non sono stati individuati universal jailbreaks per Fable 5, pur riconoscendo che nessun modello può essere considerato completamente immune da questo tipo di attacchi. L’azienda richiama a questo proposito un’analogia con il software tradizionale: così come nessun programma può essere reso definitivamente privo di vulnerabilità, anche un modello linguistico non può essere reso completamente impermeabile ai jailbreak.
Questa classificazione sposta il baricentro della discussione. La domanda non è più soltanto se un jailbreak esista, ma quali capacità riesca effettivamente a sbloccare, quanto sia generalizzabile e con quale facilità possa essere trasformato in uno strumento operativo. Il cambiamento è rilevante perché distingue tra comportamenti marginali, tecniche con impatto limitato e vulnerabilità che potrebbero avere conseguenze concrete per la sicurezza informatica.
Anthropic utilizza questa stessa chiave di lettura anche per rileggere il caso Amazon. Secondo l’azienda, la tecnica individuata dai ricercatori aveva oltrepassato una parte del safety margin, ma non aveva dato accesso alle capacità avanzate di Mythos 5 né a funzionalità offensive esclusive di Fable 5. Da qui la valutazione dell’azienda secondo cui il problema era reale e richiedeva un aggiornamento dei sistemi di protezione, senza però giustificare la classificazione del modello come dotato di capacità offensive non mitigate.
Anthropic propone uno standard comune per classificare i jailbreak
Per Anthropic, l’episodio di Fable 5 ha evidenziato anche un problema più generale. Oggi non esiste un linguaggio condiviso che permetta di stabilire quanto sia realmente grave un jailbreak.
Nel settore della cybersecurity la scoperta di una vulnerabilità non viene valutata soltanto in base alla sua esistenza. Da anni strumenti come il Common Vulnerability Scoring System (CVSS) consentono di attribuire un punteggio che tiene conto di fattori quali l’impatto, la facilità di sfruttamento e la complessità dell’attacco, permettendo a produttori, ricercatori e organizzazioni di stabilire le priorità di intervento.
Secondo Anthropic, un sistema analogo manca nel mondo dell’intelligenza artificiale. Ogni nuovo jailbreak viene discusso come un caso isolato, senza criteri oggettivi che consentano di confrontarne la gravità o di stabilire quando richieda una risposta immediata. La conseguenza è un’elevata incertezza sia per gli sviluppatori, chiamati a decidere quanto rapidamente intervenire, sia per i governi, che devono valutare se una determinata tecnica giustifichi misure eccezionali come la limitazione dell’accesso a un modello.
Per questo motivo Anthropic annuncia di aver avviato, insieme ad Amazon, Microsoft, Google e agli altri partner del programma Project Glasswing, la definizione di un framework condiviso per classificare la gravità dei jailbreak. L’obiettivo è costruire uno standard aperto che possa essere adottato dall’intero settore, fornendo un riferimento comune per sviluppatori, ricercatori e istituzioni.
Quattro criteri per misurare il rischio
La proposta di Anthropic si basa su quattro dimensioni, pensate per descrivere sia le capacità effettivamente ottenute attraverso un jailbreak sia la probabilità che possano tradursi in un rischio concreto.
Il primo criterio è il capability gain, cioè il vantaggio operativo realmente ottenuto rispetto agli strumenti già disponibili. Se un jailbreak consente soltanto di raggiungere risultati che altri modelli pubblici o strumenti di sicurezza permettono già di ottenere, la sua gravità risulta limitata. Se invece sblocca capacità che accelerano significativamente anche il lavoro di esperti di alto livello, la valutazione di gravità aumenta.
Il secondo criterio è la breadth of capability gain, ovvero l’ampiezza delle funzionalità sbloccate. Un jailbreak utilizzabile soltanto per uno specifico scenario presenta un profilo di rischio molto diverso rispetto a una tecnica che permette di aggirare le protezioni in numerosi contesti e per differenti tipologie di attacco.
Il terzo criterio riguarda la ease of weaponization, cioè la facilità con cui il jailbreak può essere trasformato in uno strumento operativo. Una tecnica che richiede numerosi tentativi, competenze specialistiche e una lunga attività di prompt engineering presenta un rischio inferiore rispetto a un bypass ottenibile con un’unica richiesta e immediatamente riutilizzabile.
Il quarto criterio è la discoverability, cioè quanto sia semplice reperire o ricostruire la tecnica. Un jailbreak noto solo a pochi ricercatori specializzati presenta implicazioni diverse rispetto a un metodo già pubblicato online, facilmente replicabile e rapidamente diffondibile.
Anthropic propone di utilizzare la combinazione di questi quattro fattori per determinare la risposta più appropriata. Nei casi più gravi, ad esempio quando un jailbreak venga utilizzato o possa essere rapidamente impiegato per compromettere infrastrutture critiche o sistemi finanziari, l’azienda afferma che avvierebbe immediatamente misure di mitigazione preliminari ancora prima della distribuzione di una soluzione definitiva. A supporto di questo processo verrà inoltre costituito un team dedicato al monitoraggio continuo dei principali canali attraverso i quali ricercatori e aziende segnalano nuovi jailbreak.
Contestualmente, Anthropic ha annunciato anche un nuovo programma su HackerOne, attraverso il quale i ricercatori di sicurezza potranno segnalare potenziali jailbreak in ambito cybersecurity individuati in Fable 5. L’obiettivo è integrare la ricerca indipendente nel processo di individuazione e correzione delle vulnerabilità, affiancando il framework di classificazione proposto dall’azienda.
Anthropic riconosce che qualsiasi sistema di classificazione resterà inevitabilmente imperfetto. Ritiene però che la disponibilità di un linguaggio comune rappresenti un passo fondamentale per consentire a sviluppatori, ricercatori e autorità pubbliche di discutere gli stessi fenomeni utilizzando criteri condivisi anziché valutazioni soggettive.
Dalla sicurezza dei modelli alla governance dell’AI
La proposta va oltre la definizione di un nuovo schema di valutazione tecnica. Se adottato dall’intero settore, un framework di questo tipo potrebbe svolgere per i modelli di intelligenza artificiale un ruolo analogo a quello del Common Vulnerability Scoring System (CVSS) nella gestione delle vulnerabilità software, offrendo una metrica comune sulla quale costruire procedure di risposta, priorità di intervento e, in prospettiva, futuri riferimenti regolatori.
Il processo delineato da Anthropic integra valutazione tecnica, ricerca indipendente, programmi di segnalazione delle vulnerabilità, aggiornamento continuo dei sistemi di protezione e collaborazione con le istituzioni nella gestione della sicurezza dei modelli di frontiera.
Una collaborazione permanente con il governo statunitense
La definizione di uno standard comune per i jailbreak si inserisce in un quadro più ampio di collaborazione con il governo degli Stati Uniti.
Anthropic afferma di aver lavorato nelle dieci settimane precedenti alla pubblicazione del documento con diverse agenzie federali durante la definizione dell’Executive Order del 2 giugno dedicato alla promozione dell’innovazione e della sicurezza nell’intelligenza artificiale avanzata.
Tra gli interlocutori citati figurano l’Office of the National Cyber Director, l’Office of Science and Technology Policy, il Dipartimento del Tesoro, il Dipartimento del Commercio, incluso il Center for AI Standards and Innovation (CAISI), oltre ad altre agenzie impegnate nella sicurezza nazionale.
L’azienda definisce una serie di impegni destinati a entrare stabilmente nel processo di sviluppo dei futuri modelli di frontiera. I partner governativi designati potranno accedere in anticipo ai modelli e ai relativi guardrail per effettuare valutazioni indipendenti prima del rilascio pubblico, lavorando insieme ai tecnici Anthropic durante le attività di test.
Anthropic prevede inoltre di notificare rapidamente alle autorità l’individuazione di jailbreak significativi o nuovi schemi di abuso, condividendo anche le mitigazioni sviluppate affinché possano essere verificate in modo indipendente. L’azienda parteciperà inoltre al cybersecurity vulnerability clearinghouse previsto dall’Executive Order.
La collaborazione comprenderà anche attività di ricerca congiunta, la messa a disposizione di risorse computazionali per le valutazioni di sicurezza e la condivisione delle competenze maturate nel red teaming. Infine, Anthropic si impegna a collaborare con istituzioni e altri sviluppatori per definire uno standard volontario comune di sicurezza e valutazione applicabile ai modelli di frontiera.
Oltre Fable 5: verso regole condivise per i modelli di frontiera
Anthropic sostiene che la collaborazione con il governo statunitense e il framework sviluppato insieme ai partner di Project Glasswing possano costituire la base di regole sistematiche per l’intero settore. L’azienda aggiunge che tali regole dovrebbero essere recepite in una normativa solida e applicate in modo uniforme a tutti gli sviluppatori di modelli di frontiera.
La sicurezza entra così nell’intero ciclo di sviluppo e rilascio dei modelli: valutazioni preventive, classificazione dei jailbreak, verifica indipendente delle mitigazioni, aggiornamento continuo dei sistemi di protezione, programmi di segnalazione attraverso HackerOne e collaborazione strutturata con le autorità pubbliche.
Colpisce però che questo modello di governance sia costruito interamente attorno agli Stati Uniti. Gli interlocutori sono il governo federale, le agenzie statunitensi, i partner industriali del programma Glasswing e i principali hyperscaler americani. Pur presentando il framework come una possibile base per l’intero settore, il documento non affronta il ruolo dell’Europa, di altri Stati o di organismi internazionali nella definizione di questi standard. Se questo approccio dovesse affermarsi, il rischio è che le regole tecniche e operative dei modelli di frontiera diventino standard de facto elaborati negli Stati Uniti e successivamente adottati dal resto del mondo, ponendo all’Europa il problema non solo della dipendenza dai modelli, ma anche da procedure di sicurezza e criteri di valutazione definiti altrove.






{kind=link}