


Per oltre un decennio l’infrastruttura dell’intelligenza artificiale è stata dimensionata partendo dal carico computazionale dominante: addestrare modelli sempre più grandi ed eseguirne l’inferenza nel minor tempo possibile. La crescita delle GPU e degli acceleratori specializzati è stata la conseguenza diretta di questa impostazione.
L’AI agentica sposta però il problema su un piano diverso. Il modello linguistico non rappresenta più il centro dell’architettura, ma uno dei componenti di una pipeline che comprende orchestrazione, recupero del contesto, pianificazione, interrogazione di basi dati, chiamate a strumenti esterni, esecuzione di codice, verifiche e interazioni con applicazioni enterprise. In questo scenario l’unità di progettazione non è più il workload, ma il workflow.
È questa la riflessione sviluppata da AMD in un recente intervento dedicato all’evoluzione delle infrastrutture AI. Il punto di partenza è il ruolo delle CPU EPYC all’interno del portafoglio dell’azienda, ma l’analisi descrive un cambiamento ormai evidente nell’intero settore: il collo di bottiglia non coincide più con il modello, ma con la capacità dell’infrastruttura di sostenere un processo distribuito composto da fasi eterogenee.
Un agente assomiglia più a un’applicazione distribuita che a un chatbot
La differenza rispetto ai chatbot tradizionali è sostanziale. Nel caso di una conversazione con un LLM, il flusso di esecuzione è relativamente lineare: il modello riceve un prompt, produce una sequenza di token e restituisce una risposta. Un agente, invece, riceve un obiettivo e costruisce autonomamente il percorso necessario per raggiungerlo.
Per farlo interpreta l’intenzione dell’utente, pianifica le attività, recupera informazioni da database vettoriali o documentali, richiama API, interagisce con sistemi ERP e CRM, esegue codice in ambienti isolati, consulta altri modelli, verifica i risultati e decide se il processo possa considerarsi concluso oppure richieda ulteriori iterazioni.
L’inferenza non costituisce quindi più l’intera applicazione, ma uno dei servizi che partecipano all’esecuzione del workflow. Dal punto di vista architetturale, un sistema agentico assomiglia molto più a un’applicazione distribuita che a un semplice chatbot.
Workflow dinamici e carichi variabili
L’elemento che distingue maggiormente gli agenti dalle applicazioni AI tradizionali è la capacità di modificare il proprio comportamento durante l’esecuzione.
Un risultato incompleto può indurre l’agente a interrogare nuove sorgenti dati, utilizzare strumenti differenti, coinvolgere altri agenti specializzati o ripetere parte del workflow. Ogni decisione modifica la sequenza delle operazioni successive, rendendo il carico computazionale dinamico e difficilmente prevedibile.
Questo aspetto ha conseguenze dirette sul dimensionamento dell’infrastruttura. CPU, GPU, memoria, rete e sistemi di storage vengono utilizzati in momenti diversi e con intensità variabile, mentre il percorso di esecuzione cambia continuamente in funzione delle informazioni raccolte.
I benchmark tradizionali, basati sull’esecuzione ripetitiva dello stesso modello, descrivono quindi soltanto una parte del comportamento reale di un sistema agentico.
Dalla governance all’inferenza: una pipeline composta da workload differenti
Una tipica pipeline agentica attraversa componenti molto diversi tra loro. La richiesta viene inizialmente intercettata da un gateway che applica autenticazione, controllo degli accessi e policy di sicurezza. Un livello di orchestrazione decide quindi come suddividere il problema, quali modelli utilizzare e quali strumenti coinvolgere.
Seguono il recupero del contesto tramite sistemi RAG e database vettoriali, le interrogazioni ai repository documentali e alle applicazioni aziendali, l’inferenza sui modelli linguistici, l’esecuzione delle azioni richieste, la verifica dei risultati e l’eventuale avvio di un nuovo ciclo operativo.
Ogni fase presenta caratteristiche computazionali differenti. Alcune privilegiano la latenza, altre il parallelismo, altre ancora la banda memoria, l’I/O, la località dei dati o la velocità della rete. È proprio questa eterogeneità che rende sempre meno efficace una progettazione centrata esclusivamente sull’accelerazione dell’inferenza.
Latenza e throughput diventano obiettivi distinti
Uno dei concetti più importanti richiamati da AMD riguarda la distinzione tra latenza e throughput.
L’orchestrazione degli agenti richiede tempi di risposta estremamente contenuti: anche ritardi dell’ordine di poche decine di millisecondi possono propagarsi lungo il workflow, aumentando sensibilmente il tempo necessario per completare un’attività.
Quando invece migliaia di agenti operano contemporaneamente, il parametro decisivo diventa il throughput, cioè la capacità dell’infrastruttura di sostenere un elevato numero di richieste nello stesso intervallo di tempo.
Esistono infine scenari nei quali entrambe le caratteristiche sono indispensabili. Durante l’inferenza, ad esempio, il nodo CPU deve alimentare costantemente gli acceleratori con dati e istruzioni. Se il coordinamento non è sufficientemente efficiente, gli acceleratori trascorrono parte del tempo in attesa del lavoro successivo invece di elaborare token.
Il ruolo della CPU cambia profondamente
Questa evoluzione modifica anche il rapporto tra CPU e GPU.
Le GPU rimangono il componente di riferimento per l’addestramento e l’inferenza dei modelli linguistici di grandi dimensioni. Nelle architetture agentiche, però, la CPU assume un ruolo molto più centrale rispetto al passato.
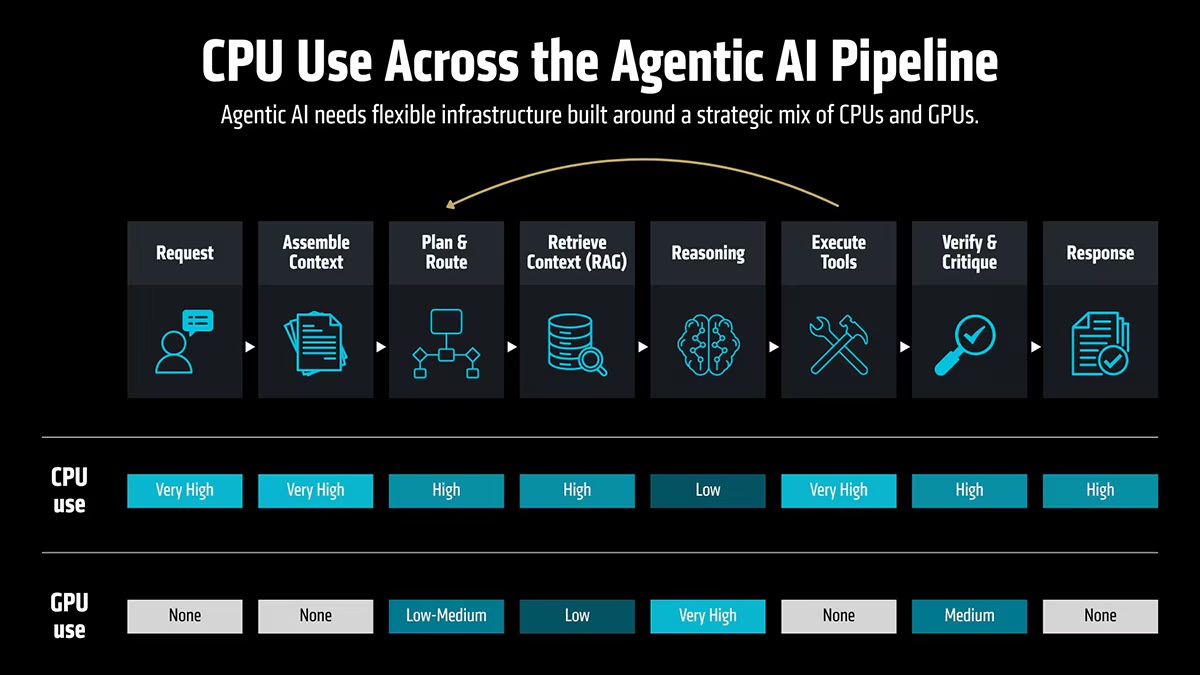
Non svolge più soltanto funzioni di supporto agli acceleratori. Gestisce il ciclo di vita degli agenti, orchestra il workflow, mantiene il contesto e la memoria di esecuzione, pianifica le chiamate ai modelli, coordina l’accesso agli strumenti esterni, organizza lo scambio di dati con database e servizi applicativi e alimenta costantemente i cluster GPU con dati e istruzioni.
L’efficienza complessiva della piattaforma dipende quindi meno dalle prestazioni del singolo componente e sempre più dalla capacità della CPU di coordinare risorse eterogenee lungo l’intero workflow.
Non esiste più una CPU universale
È proprio la distribuzione dei compiti lungo il workflow agentico a rendere sempre meno efficace l’idea di una configurazione hardware standard valida per qualsiasi scenario. L’orchestrazione di migliaia di agenti, l’esecuzione di codice Python in sandbox o le chiamate concorrenti a database e API privilegiano processori con un’elevata densità di core. Le applicazioni enterprise richiedono invece un equilibrio tra frequenza operativa, banda memoria e parallelismo, mentre durante l’inferenza il nodo host deve garantire prestazioni elevate per singolo core, un sottosistema I/O efficiente e connettività ad alta velocità.
AMD interpreta questa evoluzione come un cambiamento nel modo stesso di progettare le CPU server: non più un processore general purpose adatto a qualsiasi carico di lavoro, ma una famiglia di prodotti ottimizzati per profili computazionali differenti.
Per i workload di orchestrazione degli agenti, dell’esecuzione concorrente di codice in sandbox e delle chiamate a servizi esterni, il parametro determinante è la densità di core. Più agenti possono essere eseguiti simultaneamente, maggiore è il throughput complessivo del sistema. Per questo la quinta generazione di processori AMD EPYC arriva fino a 192 core e 384 thread, mentre la futura architettura Venice porterà il limite a 256 core e 512 thread.
Quando il carico si sposta sulle applicazioni enterprise – ERP, CRM, sistemi gestionali o piattaforme di business intelligence – diventano invece fondamentali numero di core e banda memoria, per sostenere un elevato volume di richieste eterogenee. In questo ambito AMD posiziona la famiglia EPYC 9005, disponibile con configurazioni da 8 a 192 core e una banda memoria fino a 640 GB/s. Secondo l’azienda, la futura generazione Venice aumenterà del 30% il numero massimo di core e thread e porterà la banda memoria a circa 2,5 volte quella dell’attuale piattaforma.
La fase di inferenza presenta esigenze ancora diverse. Sebbene l’elaborazione dei modelli linguistici venga normalmente affidata alle GPU, il nodo host basato su CPU rimane responsabile di alimentare gli acceleratori con dati e istruzioni. In questo contesto non è necessariamente il numero di core a fare la differenza: diventano cruciali prestazioni per singolo core, frequenze operative elevate, memoria, I/O e networking, così da ridurre i tempi di attesa degli acceleratori e massimizzare il numero di token elaborati. AMD porta come esempio il processore EPYC 9575F, dotato di 64 core e capace di raggiungere frequenze fino a 5 GHz, mentre la futura famiglia Venice estenderà ulteriormente l’offerta di modelli ad alta frequenza.
Più che promuovere un singolo processore, questa segmentazione evidenzia una tendenza che interessa l’intero mercato dei server. Le famiglie di CPU stanno evolvendo verso configurazioni sempre più specializzate, nelle quali densità di core, frequenza operativa, banda memoria e sottosistema I/O vengono combinati in modo diverso per adattarsi ai profili di carico delle applicazioni agentiche.
Un’evoluzione analoga è già avvenuta nel mercato degli acceleratori AI. NVIDIA, ad esempio, non si limita più a proporre GPU sempre più potenti, ma ha costruito una piattaforma nella quale ogni componente svolge un ruolo preciso: le GPU Blackwell B200 e GB200 Grace Blackwell sono destinate all’addestramento e all’inferenza dei modelli di frontiera; i sistemi GB300 NVL72 sono progettati per i carichi di AI agentica, reasoning e inferenza su larga scala, caratterizzati da un fabbisogno più elevato di memoria e capacità elaborativa; le CPU Grace alimentano gli acceleratori grazie alla memoria LPDDR5X ad alta banda e all’interconnessione NVLink-C2C; le DPU BlueField scaricano dalla CPU funzioni di networking, sicurezza e gestione dell’infrastruttura; gli switch Spectrum-X e NVLink Switch trasformano infine la rete in un componente attivo dell’architettura AI, riducendo la latenza delle comunicazioni tra migliaia di GPU.
Il messaggio di AMD segue la stessa logica, ma applicata al mondo delle CPU server. La competizione non riguarda più soltanto il numero di core o la frequenza di clock: riguarda la capacità di offrire un portafoglio di processori ottimizzati per ruoli differenti all’interno della pipeline AI, dalla gestione degli agenti all’esecuzione delle applicazioni enterprise, fino al supporto dei cluster GPU dedicati all’inferenza.
La località dei dati torna a essere un fattore strategico
Per molti anni il collo di bottiglia principale dell’AI è stato la potenza di calcolo. Con l’AI agentica torna invece centrale un tema storico dell’architettura dei sistemi distribuiti: la località dei dati.
Un agente può interrogare ripetutamente database vettoriali, repository documentali, sistemi ERP, servizi cloud e applicazioni SaaS. In questo contesto il tempo necessario per trasferire informazioni tra componenti diversi può incidere quanto la velocità del processore che esegue l’inferenza.

Ridurre gli spostamenti di dati, mantenere il contesto in memoria e limitare le latenze di rete diventa quindi un fattore determinante per il tempo complessivo di esecuzione. Non sorprende che AMD affianchi alle CPU EPYC e agli acceleratori Instinct anche la piattaforma di networking Pensando: nelle architetture agentiche la rete non rappresenta più un semplice mezzo di trasporto dei dati, ma parte integrante del workflow.
Gli agenti moltiplicano il carico sull’intera infrastruttura
L’impatto dell’AI agentica non riguarda soltanto i cluster dedicati all’inferenza.
Quando pochi utenti utilizzano un chatbot, il traffico generato verso i sistemi aziendali rimane relativamente contenuto. Lo scenario cambia radicalmente quando centinaia o migliaia di dipendenti iniziano a distribuire agenti autonomi che interrogano continuamente database, ERP, CRM, repository documentali, piattaforme di identity management e servizi AI.
Ogni agente diventa un nuovo consumatore di risorse infrastrutturali. Crescono il numero di interrogazioni ai database, le chiamate API, il traffico di rete, le operazioni di storage e il carico sui middleware, spesso in misura superiore all’aumento delle sole richieste di inferenza.
Per i responsabili IT significa che la pianificazione dovrà riguardare l’intero ecosistema applicativo e non soltanto la capacità dei cluster GPU.
I framework agentici stanno già progettando l’infrastruttura del futuro
Questa evoluzione non emerge soltanto dall’analisi di AMD. È già incorporata nei principali framework utilizzati per sviluppare sistemi di AI agentica, ciascuno con un approccio diverso all’orchestrazione dei workflow.
LangGraph, sviluppato nell’ecosistema LangChain, descrive l’esecuzione attraverso grafi di stati persistenti. Gli agenti possono sospendere un’elaborazione, conservarne il contesto, ritornare su decisioni precedenti e riprendere il workflow senza ricominciare dall’inizio. È uno dei framework che meglio rappresentano il passaggio da una pipeline lineare a un’esecuzione dinamica.
Microsoft Semantic Kernel affronta il problema da una prospettiva enterprise. Il modello linguistico viene inserito all’interno di un’infrastruttura composta da plugin, workflow, memoria persistente e funzioni native, che consentono di orchestrare applicazioni e servizi aziendali già esistenti anziché limitarsi alla generazione di testo.
AutoGen, nato nei laboratori Microsoft Research, porta invece il paradigma multi-agent al centro dell’architettura. Più agenti specializzati collaborano nello stesso processo: uno pianifica il lavoro, un altro produce codice, un terzo lo verifica e un quarto valida il risultato finale. L’infrastruttura deve quindi sostenere un numero molto maggiore di comunicazioni tra modelli, servizi e strumenti.
CrewAI applica la stessa filosofia ai processi organizzativi, assegnando agli agenti ruoli distinti – analista, sviluppatore, revisore, responsabile della conformità – che cooperano come farebbe un team di persone per raggiungere un obiettivo comune.
Nonostante differenze significative nell’implementazione, tutti questi framework introducono concetti assenti nei chatbot tradizionali: gestione dello stato, memoria persistente, orchestrazione, collaborazione tra agenti, pianificazione delle attività e utilizzo nativo di strumenti esterni. L’LLM diventa così uno dei componenti di un sistema più ampio, anziché coincidere con l’intera applicazione.
Lo stesso paradigma emerge ormai anche nelle piattaforme cloud. Amazon Bedrock, Azure AI Foundry, Copilot Studio, Vertex AI Agent Engine e l’Agent Development Kit di Google non sono semplici ambienti per eseguire modelli linguistici, ma piattaforme di orchestrazione nelle quali memoria, basi di conoscenza, strumenti esterni, osservabilità, governance e modelli AI vengono gestiti come parti di un unico workflow distribuito.
Il passaggio dal workload al workflow non riguarda quindi soltanto l’infrastruttura hardware descritta da AMD: è già incorporato negli strumenti con cui oggi vengono progettati, sviluppati e distribuiti gli agenti AI.
Dal workload al workflow
Per oltre dieci anni progettare un’infrastruttura AI ha significato soprattutto scegliere l’acceleratore più adatto ai modelli da eseguire. L’AI agentica cambia radicalmente questa prospettiva.
La domanda non è più quante CPU o GPU installare, ma come distribuire il carico tra orchestrazione, inferenza, memoria, networking, sicurezza, storage e applicazioni enterprise affinché ogni fase del workflow utilizzi la risorsa più adatta.
È questo il passaggio dal workload al workflow evidenziato da AMD. La competizione tra i fornitori di infrastrutture AI non si giocherà soltanto sulla potenza dei modelli o degli acceleratori, ma sulla capacità di orchestrare sistemi sempre più complessi, distribuendo in modo efficiente il lavoro tra CPU, GPU, rete, memoria e storage. Una trasformazione che è già visibile nei framework software, nelle piattaforme cloud e nelle nuove generazioni di CPU e acceleratori AI. Più che la corsa al modello più potente, sarà probabilmente questa evoluzione architetturale a determinare la prossima fase dell’AI enterprise.






{kind=link}