


Portare l’intelligenza artificiale fuori dalla dimensione del “demo” e dentro i processi reali dell’impresa: è questo il senso della release Appian 25.4 della piattaforma low-code e di process automation, recentemente presentata. Dopo una fase di sperimentazione intensa della GenAI — spesso ridotta a chatbot e proof of concept isolati — il mercato sta misurando i limiti di approcci poco governati: costi difficili da prevedere, benefici complessi da misurare, integrazione debole con i sistemi operativi. Appian risponde con un’impostazione in cui l’IA non si aggiunge “a lato”, ma viene resa nativa del workflow.
La 25.4 punta a trasformare questa impostazione in capacità operative concrete. Agent Studio introduce agenti IA specializzati che lavorano come task di processo; Appian Composer accelera la modernizzazione applicativa trasformando requisiti e documentazione in prototipi low-code riusabili; il Data Fabric potenziato fornisce il contesto dati e documentale per rendere gli agenti efficaci e controllabili su scala enterprise. Silvia Speranza, Regional Vice President for Italy & Greece di Appian colloca l’aggiornamento in una traiettoria coerente con l’identità process-first della piattaforma: “Più che trasformazione parlerei di arricchimento di piattaforma”, perché Appian nasce per orchestrare processi mission-critical e oggi innesta l’IA dentro quello stesso impianto, estendendo la grammatica del processo e mantenendo al centro la triade dati-workflow-persone.
Perché Appian sceglie gli agenti: i limiti dei progetti GenAI scollegati dai workflow
Il punto di partenza è una diagnosi di mercato. Appian cita una ricerca MIT secondo cui i chatbot IA “standalone” falliscono nel 95% dei casi perché si confondono quando operano su dati provenienti da contesti eterogenei; di conseguenza risultano costosi e poco affidabili nei back-office. La società dichiara di aver reagito integrando agenti specializzati nei flussi operativi, dove possono produrre risultati consistenti su scala.
Speranza conferma la lettura sul campo e la rende ancora più netta: “La gran parte dei progetti di intelligenza artificiale falliva perché l’AI non può fare a meno di due elementi principali: i dati e i processi”. Il concetto tecnico è che il modello generativo, senza un riferimento strutturato ai dati aziendali e senza regole di processo che ne delimitino l’azione, diventa instabile: non sai quali fonti userà, non sai quanto costerà l’esecuzione e non riesci a certificare l’esito. L’approccio agentico nasce quindi come dispositivo di “messa a terra” della GenAI.
Da qui deriva anche la dinamica di adozione che Appian osserva: “Circa il 25-30% dei nostri clienti utilizza già l’IA nei processi” e la quota cresce perché le aziende stanno passando da un’adozione incontrollata a un’adozione governata e orientata all’efficacia. Il segnale è che la domanda non è più “dove posso mettere la GenAI?”, ma “in quale task di processo crea davvero valore?”.
Il triangolo persone-dati-processi: human-in-the-loop come requisito industriale
Nella visione Appian l’IA non sostituisce la decisione. Speranza usa un esempio quotidiano per fissare il principio di responsabilità: “L’AI può aiutarti a scrivere un post o una mail, ma la responsabilità resta tua; non puoi dire “me l’ha detto lei””. In azienda questo diventa ancora più stringente: la decisione resta in capo a chi governa il processo e l’agente IA fornisce proposte o automatizza porzioni di lavoro, senza introdurre un decisore opaco nel flusso.
Tecnicamente questo si traduce in un vincolo: l’agente viene progettato come task non deterministico ma controllato, cioè un componente che può generare output probabilistici però entro limiti espliciti di ruoli, permessi e obiettivi. L’adozione human-in-the-loop non è solo prudenza etica: è un modo per rendere il sistema verificabile, auditabile e compatibile con i requisiti di compliance tipici dei processi enterprise.
In Appian 25.4 l’agente è modellato come una risorsa di processo. È “non deterministico” perché può produrre output probabilistici, ma viene confinato dentro un task con ruoli, obiettivi e permessi espliciti. La configurazione del processo stabilisce che cosa può fare l’agente, su quali dati può operare e in quale punto del flusso deve intervenire. È questo vincolo che rende la GenAI scalabile: comportamento tracciabile, costi prevedibili e responsabilità umana invariata sul risultato.
Agent Studio: agenti IA come step del workflow, non come chatbot laterali
Agent Studio rappresenta il punto di innesto operativo dell’intelligenza artificiale nella piattaforma Appian. È l’ambiente che consente di implementare su larga scala agenti IA avanzati, progettati per ragionare sul contesto, gestire eccezioni e agire sui dati aziendali per automatizzare attività complesse. La sua caratteristica distintiva è l’eredità nativa del contesto di piattaforma: accesso ai dati, contesto di processo e meccanismi di controllo vengono trasferiti direttamente all’agente.
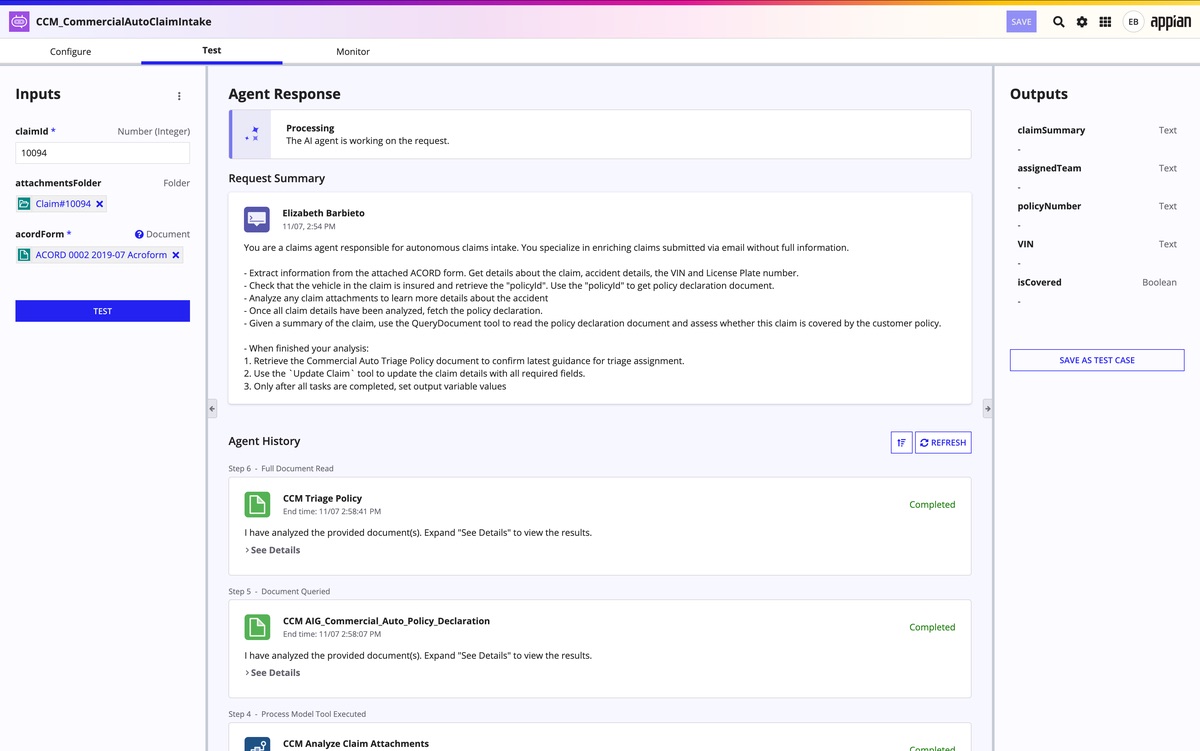
Non si tratta di un designer di chatbot, ma di uno strumento che rende industrializzabile l’approccio agentico. Gli agenti costruiti con Agent Studio diventano task del workflow, con input e output formalizzati nel processo. Con la release 25.4, dopo la preview ad Appian World 2025, questa capacità entra in general availability, segnando il passaggio dalla sperimentazione all’uso in produzione.
Dal punto di vista funzionale, gli agenti operano nel punto esatto del processo in cui vengono inseriti: possono interpretare il contesto, gestire eccezioni di flusso e intervenire sui dati aziendali senza lavorare “a lato” dell’operatività. La loro efficacia deriva dall’eredità delle tre proprietà native di Appian — accesso ai dati, contesto di processo e controlli di piattaforma — che li colloca all’interno della catena del valore del workflow.
Operativamente, il business definisce in linguaggio naturale gli obiettivi di alto livello; l’agente utilizza il Data Fabric e gli strumenti low-code per individuare il percorso più efficace, interpretare anche dati non strutturati e aggiornare le azioni in tempo reale. La governance resta quella del processo: l’agente è tracciabile come qualsiasi altro task, perché opera entro il perimetro definito dal workflow. È il punto su cui Speranza insiste quando chiarisce che l’agente non è “libero di fare quello che vuole”.
Il modello è quello di un collega digitale specializzato su un compito preciso, non di un assistente onnisciente. Questa specializzazione è la condizione che consente la scalabilità e, allo stesso tempo, la sostenibilità economica. “Se non la controlli, costa”, osserva Speranza. Inserire la GenAI in un task di processo significa fissare confini chiari di ricerca e di azione: l’agente non esplora indiscriminatamente basi di conoscenza o fonti esterne, ma lavora solo sulle informazioni pertinenti a quel passaggio del flusso. Il risultato è duplice: costi più prevedibili e output più affidabili.
Appian Composer: dalla specifica al prototipo funzionante, con riuso dei mattoncini
Il secondo pilastro è Appian Composer, che Appian presenta come un acceleratore di modernizzazione “dall’idea all’app in pochi minuti”. Più di 130 aziende lo hanno già utilizzato per creare oltre 1.300 applicazioni, segno di una domanda concreta di strumenti capaci di ridurre il time-to-value del low-code. Composer genera un piano interattivo dell’applicazione — storie utente, dati, processi e user experience — e lo traduce automaticamente in una prima versione pronta per il tuning.
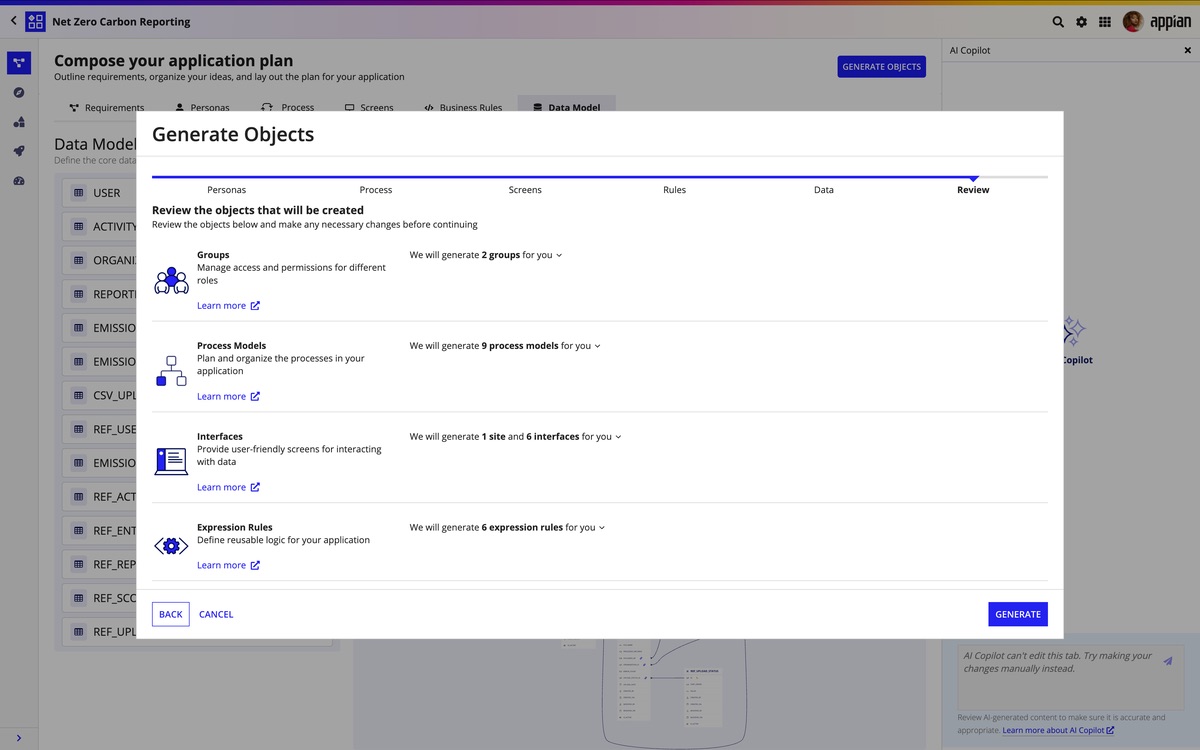
Speranza entra nel merito tecnico: “Il nostro Composer comincia a strutturare tutti gli elementi che caratterizzano i mattoncini della piattaforma: persone, regole di business, dati e processo”. Non si tratta quindi di semplice scaffolding dell’interfaccia, ma di generazione assistita della logica applicativa e del workflow. È questo che consente di andare oltre la velocizzazione del primo sprint di sviluppo, producendo building block riutilizzabili e un’accelerazione cumulativa nel tempo.
Composer lavora su due livelli: da un lato organizza in modo collaborativo requisiti e documentazione funzionale in un piano strutturato condiviso tra business, IT e IA; dall’altro trasforma quel piano in un’applicazione low-code funzionante con un solo click. Il valore distintivo, come sottolinea Speranza, è proprio nella strutturazione dei componenti core della piattaforma — ruoli, regole di business, dati e processi — che diventano blocchi riutilizzabili nei progetti successivi, riducendo tempi e rischio.
Dal punto di vista del ciclo di vita applicativo, Composer abilita una vera logica di prototipazione rapida. “Ti porta a un prototipo funzionante, non ancora da produzione, ma che implementa le caratteristiche richieste”, spiega Speranza. Questo approccio consente di validare rapidamente requisiti e flussi, correggere la direzione nelle fasi iniziali e affrontare l’industrializzazione con meno rework.
L’impatto è particolarmente evidente nei progetti di modernizzazione del legacy. Speranza cita un caso reale di reverse engineering durato “sei-sette mesi” per ricostruire applicazioni non più manutenibili; con Composer, osserva, “oggi sarebbe più semplice farne almeno il 50-60% in automatico”. L’obiettivo non è sostituire il lavoro umano, ma comprimere drasticamente le fasi più onerose di analisi, modellazione e ricostruzione dei processi, liberando risorse per l’ottimizzazione.
Data Fabric potenziato: scala, performance e documenti nel perimetro IA
L’agentic AI richiede dati disponibili, coerenti e governati. Con la release 25.4 Appian rafforza quindi il Data Fabric, progettato per sostenere workload agentici e processi ad alta frequenza. La piattaforma arriva a gestire fino a 50 milioni di righe, aumenta di cinque volte la velocità di scrittura e introduce la crittografia trasparente dei dati, requisiti fondamentali per garantire sicurezza, conformità e prestazioni su basi dati enterprise. Non si tratta di numeri di marketing, ma di condizioni necessarie per eseguire agenti IA senza degradare le performance operative.
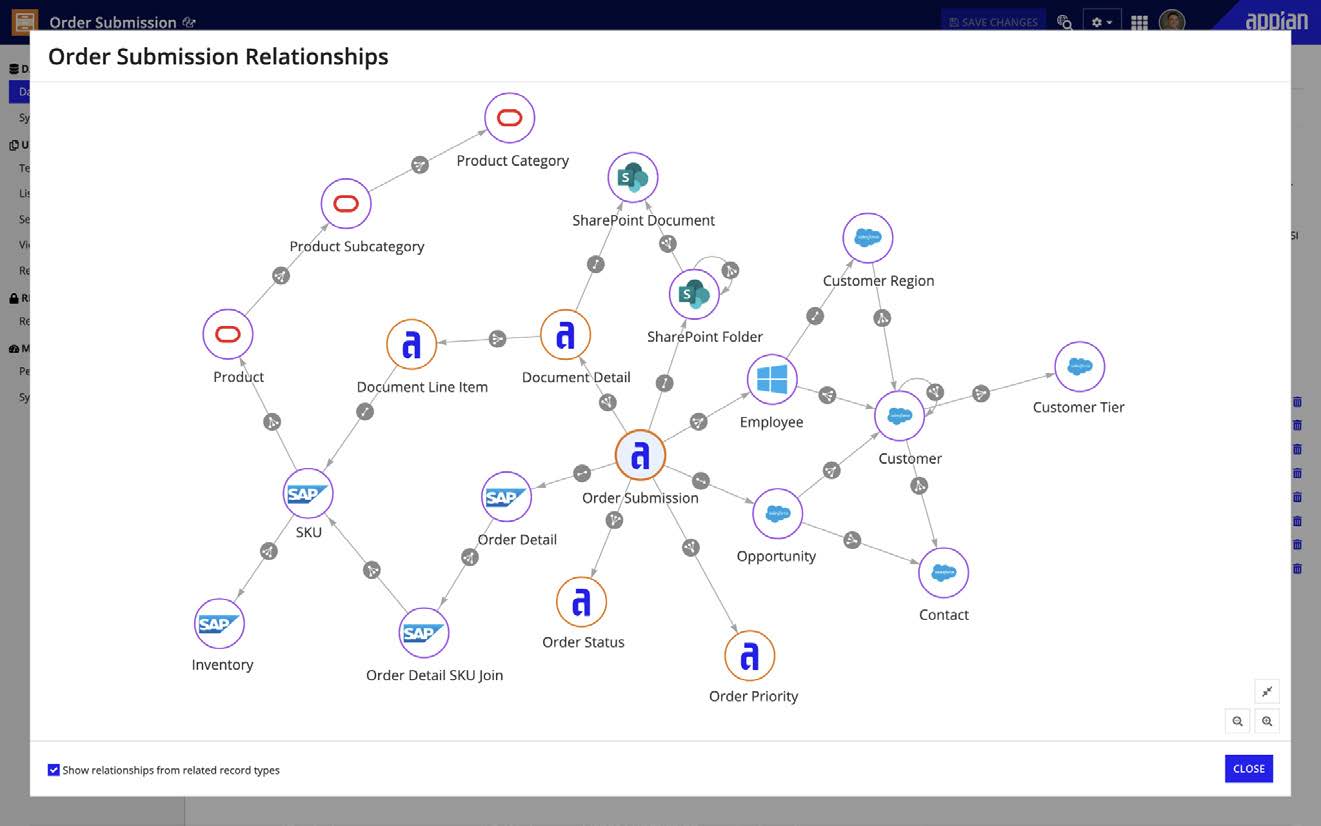
Il Data Fabric svolge una funzione centrale di unificazione e virtualizzazione dei dati provenienti da sistemi eterogenei, presentandoli agli agenti e alle applicazioni come un modello coerente e governato. È questo livello di astrazione che consente all’IA di operare con un contesto stabile: gli agenti non interrogano fonti in modo libero, ma si appoggiano al fabric, che stabilisce quali dati esporre e con quali permessi. In questo modo viene evitato il problema tipico dei chatbot standalone, che falliscono quando i dati arrivano da contesti diversi e non allineati.
L’evoluzione riguarda anche i contenuti non strutturati. Il Data Fabric estende infatti il proprio modello agli oggetti documentali, permettendo agli agenti di estrarre informazioni non solo dai dati strutturati, ma anche dai dati contenuti nei documenti gestiti nei processi. “Posso applicare il Data Fabric anche ai documenti e recuperare informazioni non solo dai dati, ma dai dati dentro i documenti che gestisco”, osserva Speranza. Il risultato è un’operatività coerente e sicura: l’agente lavora su dati e documenti con le stesse regole di accesso del processo, evitando fughe fuori perimetro e mantenendo coerenza semantica.
Governance e ROI: l’IA come leva selettiva, non come etichetta universale
Appian non promette un’IA buona per tutto. Speranza descrive una struttura interna di value engineering che misura il ritorno dell’investimento sui singoli business case e aiuta a decidere dove l’IA ha senso e dove no: “Misuriamo il beneficio dell’investimento nell’adottare l’AI nei processi e diciamo anche dove non ha senso utilizzarla. Non siamo la panacea di tutti i mali”. L’affermazione evita di spingere GenAI in task dove peggiorerebbe costi o complessità.
Questo approccio risponde a una distorsione di mercato: molte iniziative sono partite perché l’IA era percepita come requisito per ottenere budget, ma sono state poi fermate da costi e scarsa governabilità. Legare l’agente al processo, con perimetro definito, e misurare il ROI prima e dopo l’adozione permette di industrializzare solo ciò che è sostenibile.
Public sector: maturazione dell’IA, ma trasformazione frenata da asimmetrie e governance dei dati
Nel public sector italiano, l’adozione dell’intelligenza artificiale sta entrando in una fase meno sperimentale e più industriale, ma con velocità molto diverse tra amministrazioni. Silvia Speranza descrive una Pubblica Amministrazione che ha iniziato a selezionare con maggiore attenzione dove applicare l’IA e con quali obiettivi di servizio, dopo una prima ondata di iniziative spesso guidate dall’urgenza di fare AI. Tuttavia, questa maturazione si scontra con un panorama frammentato: accanto a enti che hanno già capito come innestare agenti e automazione nei processi a beneficio di cittadini e imprese, restano realtà ferme per ragioni che non sono solo tecnologiche. L’elemento discriminante, nella sua lettura, è la capacità di governo: senza una leadership che imponga condivisione dei dati, standard comuni e responsabilità trasversali, l’IA rischia di rimanere confinata a progetti pilota non scalabili.
Speranza nota un cambio di atteggiamento rispetto all’hype iniziale: la PA centrale sta diventando più selettiva negli investimenti e cerca progetti dove l’IA generi benefici misurabili sul servizio. Questa evoluzione è coerente con la logica Appian di IA process-embedded: anche nel pubblico l’IA ha senso solo quando migliora tempi amministrativi, qualità delle decisioni o gestione di volumi documentali complessi.
Il nodo è la disomogeneità. Nella stessa geografia istituzionale convivono amministrazioni che hanno fatto passi da gigante su digitalizzazione e automazione e altre che restano bloccate. Dal punto di vista tecnico questo crea due popolazioni di progetti: enti pronti a innestare agenti specializzati in processi già modellati, e organizzazioni dove l’IA viene ancora concepita come appendice, con rischio di replicare i limiti dei chatbot standalone.
Il collo di bottiglia individuato è soprattutto organizzativo. Richiamando un confronto con Innovation Group, Speranza sottolinea che nella PA la trasformazione digitale è spesso rallentata da un tema di potere informativo: se le informazioni sono strumento di controllo interno, la loro condivisione tra uffici diventa difficile. Senza dato condiviso non esiste né Data Fabric efficace, né processo automatizzabile, né agente IA in grado di operare con contesto stabile.
Qui entra la variabile decisiva: la leadership. Secondo Speranza, quando un manager pubblico si assume responsabilità, impone standard e difende una direzione trasversale, la differenza si vede. In termini progettuali significa avere sponsor capaci di selezionare i processi giusti, obbligare interoperabilità tra direzioni e sostenere il change management contro resistenze interne. Senza questa spinta, la piattaforma resta un toolkit a isole e non un’infrastruttura di efficienza.
Infine, Speranza mette a fuoco un vantaggio pratico del modello Appian per la PA: una piattaforma unica consente a più fornitori di lavorare sullo stesso stack. In un settore vincolato da appalti frammentati, questo riduce duplicazioni, facilita riuso dei componenti e rende più controllabile l’introduzione di agenti IA in logiche human-in-the-loop.
Prospettive 2026: dalla sperimentazione alla messa in produzione controllata
La release 25.4 consolida una posizione industriale precisa: la GenAI, in impresa e nel pubblico, funziona quando è contestualizzata nei dati, incardinata nei processi e governata da persone e metriche di valore. Agent Studio rende gli agenti parte della catena operativa; Composer comprime tempi e rischio della modernizzazione low-code; Data Fabric garantisce contesto scalabile e sicuro, esteso anche ai documenti. È una risposta tecnica ai limiti dei chatbot generalisti e una proposta di IA da produzione, con confini chiari e risultati misurabili.
Dalla conversazione emerge una previsione chiara: il 2026 sarà meno rumoroso ma più produttivo. La fase in cui i clienti “volevano fare IA a ogni costo” sta lasciando spazio a progetti controllati che mirano a efficacia e scalabilità. Con Agent Studio e Composer, Appian scommette di intercettare questa maturazione del mercato: agenti specializzati per processi regolati e modernizzazione rapida come leva per ripulire il debito applicativo.






{kind=link}