


Come sottolinea Google, il primo modello Gemma è stato lanciato all’inizio dello scorso anno e da allora è cresciuto fino a diventare un fiorente Gemmaverse con oltre 160 milioni di download complessivi. Questo ecosistema comprende la famiglia di oltre una dozzina di modelli specializzati per ogni tipo di applicazione, dalla salvaguardia alle applicazioni mediche e, soprattutto, le innumerevoli innovazioni della community. Da innovatori come Roboflow, che ha creato una computer vision enterprise, all’Institute of Science di Tokyo, che ha creato varianti giapponesi di Gemma ad alta capacità.
Sulla base di questo sorprendente slancio, il team di Google DeepMind ha ora annunciato la full release di Gemma 3n: mentre la preview del mese scorso ne offriva un assaggio, ora si sblocca tutta la potenza di questa architettura mobile-first.
Gemma 3n è stato progettato da Google per la community di sviluppatori che ha contribuito a palsmare Gemma. È supportato dagli strumenti preferiti dai developer, tra cui Hugging Face Transformers, llama.cpp, Google AI Edge, Ollama, MLX e molti altri, che consentono di fare il fine-tuning e il deployment con facilità delle proprie applicazioni specifiche on-device.
Secondo Google DeepMind, Gemma 3n rappresenta un importante passo avanti per l’IA on-device, portando potenti capacità multimodali ai dispositivi edge con prestazioni che in precedenza erano riscontrabili solo nei modelli di frontiera basati su cloud dello scorso anno.
È multimodale per design: Gemma 3n supporta in modo nativo input e output di immagini, audio, video e testo.
Ed è ottimizzato per l’utilizzo on-device: Progettati con un occhio di riguardo all’efficienza, i modelli Gemma 3n sono disponibili in due dimensioni basate su parametri effettivi: E2B e E4B. Sebbene il loro numero di parametri grezzi sia rispettivamente di 5B e 8B, le innovazioni architetturali consentono loro di funzionare con un ingombro di memoria paragonabile a quello dei modelli tradizionali 2B e 4B, operando con appena 2GB (E2B) e 3GB (E4B) di memoria.
 Presenta un’architettura innovativa: Il cuore di Gemma 3n è costituito da componenti innovativi come l’architettura MatFormer per la flessibilità di calcolo, Per Layer Embeddings (PLE) per l’efficienza della memoria, LAuReL e AltUp per l’efficienza architetturale e nuovi encoder audio e vision basati su MobileNet-v5 ottimizzati per i casi d’uso su dispositivo.
Presenta un’architettura innovativa: Il cuore di Gemma 3n è costituito da componenti innovativi come l’architettura MatFormer per la flessibilità di calcolo, Per Layer Embeddings (PLE) per l’efficienza della memoria, LAuReL e AltUp per l’efficienza architetturale e nuovi encoder audio e vision basati su MobileNet-v5 ottimizzati per i casi d’uso su dispositivo.
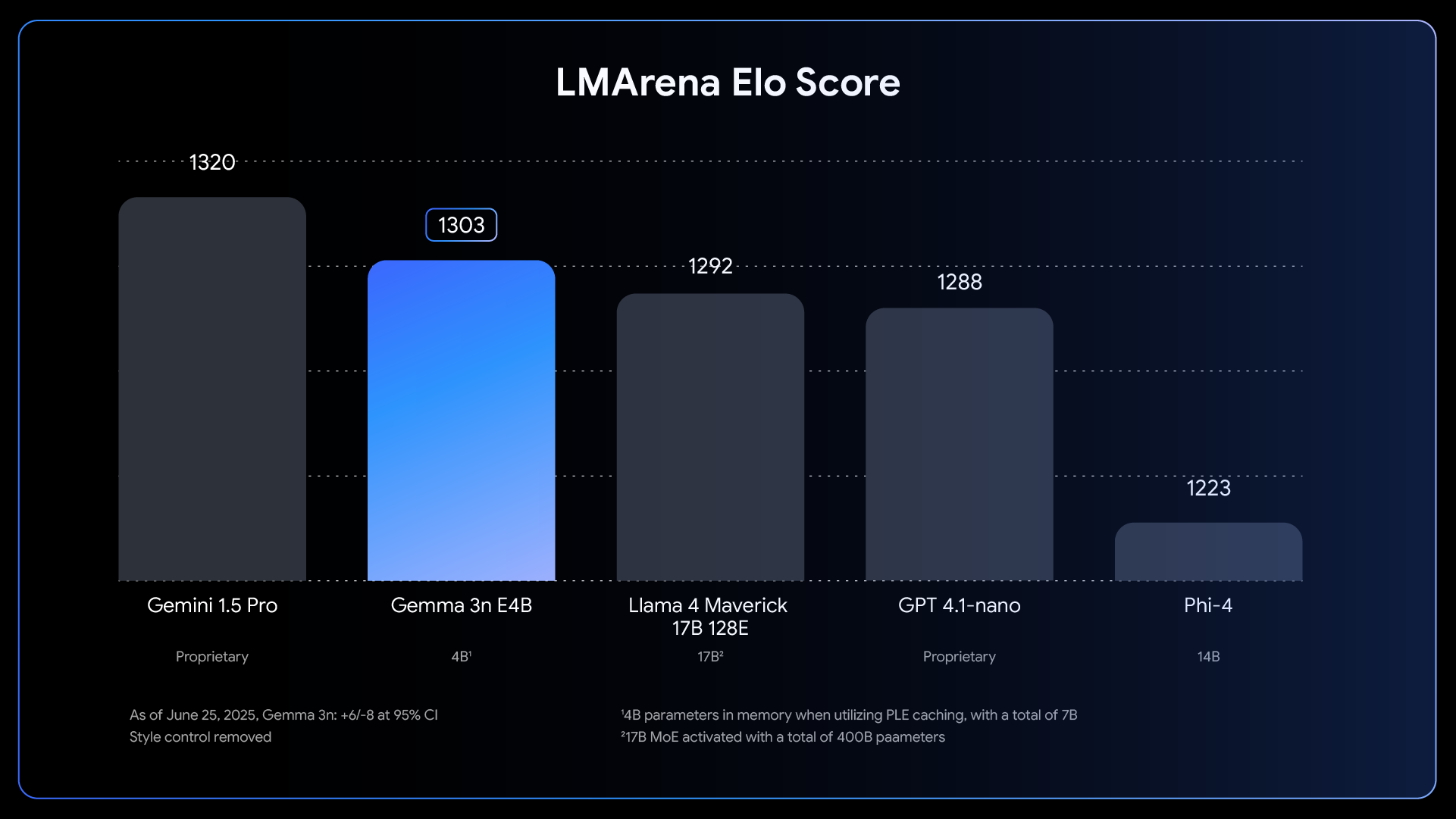
Inoltre, hanno una qualità migliorata: Gemma 3n offre miglioramenti qualitativi – sottolinea il team di Google DeepMind – in termini di multilinguismo (supporto di 140 lingue per il testo e comprensione multimodale di 35 lingue), matematica, coding e ragionamento. La versione E4B raggiunge un punteggio LMArena superiore a 1300, diventando così il primo modello sotto i 10 miliardi di parametri a raggiungere questo benchmark.
Per ottenere questo salto di qualità nelle prestazioni sul dispositivo – spiega Google – è stato necessario ripensare il modello dalle fondamenta, alla cui base c’è l’architettura mobile-first di Gemma 3n, unica nel suo genere.
Nel blog di Google per gli sviluppatori è possibile ottenere ulteriori dettagli sulla nuova architettura di Gemma 3n e vedere alcuni risultati nei benchmark, oltre a informazioni su come iniziare a esplorare il potenziale del nuovo modello.









{kind=link}