


Stability AI ha rilasciato Stable Virtual Camera, attualmente in versione di anteprima di ricerca. Questo modello diffusion multi-vista trasforma le immagini 2D in video 3D immersivi con profondità e prospettiva realistiche, spiega l’azienda, senza ricostruzioni complesse o ottimizzazioni specifiche per la scena. Stability AI invita la comunità di ricerca a esplorare le sue capacità e a contribuire al suo sviluppo.
Una telecamera virtuale è uno strumento digitale utilizzato nella cinematografia e nell’animazione 3D per catturare e navigare in scene digitali in tempo reale. Stable Virtual Camera si basa su questo concetto, combinando il familiare controllo delle telecamere virtuali tradizionali con la potenza dell’intelligenza artificiale generativa per offrire un controllo preciso e intuitivo sui risultati video 3D.
A differenza dei modelli video 3D tradizionali, che si basano su grandi insiemi di immagini di input o su una complessa pre-elaborazione, Stable Virtual Camera genera nuove viste di una scena a partire da una o più immagini di input con angolazioni specificate dall’utente. Il modello produce output video 3D coerenti e uniformi, sottolinea Stability AI, fornendo video con traiettoria continua attraverso percorsi dinamici della telecamera.
Il modello è disponibile per uso di ricerca con licenza non commerciale. È possibile leggere il paper, scaricare i pesi su Hugging Face e accedere al codice su GitHub.

Stable Virtual Camera – spiega Stability AI – offre funzionalità avanzate per la generazione di video 3D, tra cui:
- Controllo dinamico della telecamera: Supporta traiettorie della telecamera definite dall’utente e molteplici percorsi dinamici della telecamera, tra cui: 360°, Lemniscate (percorso a forma di ∞), Spiral, Dolly Zoom In, Dolly Zoom Out, Zoom In, Zoom Out, Move Forward, Move Backward, Pan Up, Pan Down, Pan Left, Pan Right e Roll.
- Input flessibili: Genera video 3D da una sola immagine di ingresso o fino a 32.
- Rapporti di aspetto multipli: In grado di produrre video in formato quadrato (1:1), verticale (9:16), orizzontale (16:9) e altri rapporti d’aspetto personalizzati senza necessità di ulteriore training.
- Generazione di video lunghi: Garantisce la coerenza 3D nei video fino a 1.000 fotogrammi, consentendo loop e transizioni fluide, anche quando si rivisitano gli stessi punti di vista.
Secondo Stability AI, Stable Virtual Camera raggiunge risultati all’avanguardia nei benchmark novel view synthesis (NVS), superando modelli come ViewCrafter e CAT3D. Eccelle sia in NVS large-viewpoint, che enfatizza la capacità di generazione, sia in NVS small-viewpoint, che privilegia la fluidità temporale.
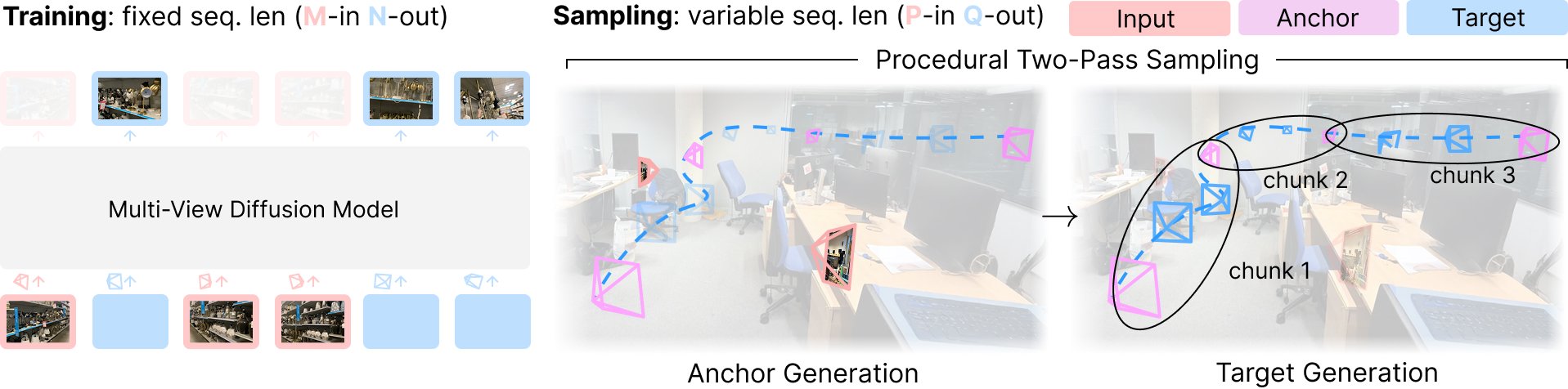 Stable Virtual Camera è addestrato come modello di diffusione multi-vista con una sequenza di lunghezza fissa, utilizzando un numero fisso di viste di ingresso e di destinazione (M-in, N-out).
Stable Virtual Camera è addestrato come modello di diffusione multi-vista con una sequenza di lunghezza fissa, utilizzando un numero fisso di viste di ingresso e di destinazione (M-in, N-out).
Durante il campionamento, funziona come un renderer generativo flessibile, in grado di gestire lunghezze di ingresso e di uscita variabili (P-in, Q-out). Ciò è possibile grazie a un processo di campionamento procedurale a due passaggi: prima la generazione delle viste di ancoraggio, poi il rendering delle viste di destinazione in chunk per garantire risultati omogenei e coerenti.
Per quanto riguarda le limitazioni del modello, Stability AI spiega che, nella sua versione iniziale, Stable Virtual Camera può produrre risultati di qualità inferiore in alcuni scenari. Le immagini di input con esseri umani, animali o texture dinamiche come l’acqua spesso portano a risultati degradati. Inoltre, scene molto ambigue, percorsi complessi della telecamera che intersecano oggetti o superfici e oggetti di forma irregolare possono causare artefatti di flickering, soprattutto quando i punti di vista di destinazione differiscono significativamente dalle immagini di input.
Maggiori informazioni sono disponibili sul sito di Stability AI.









{kind=link}