


Negli ultimi mesi abbiamo assistito a una vera rivoluzione nel modo in cui gli agenti AI possono interagire con il web. Tutto è iniziato con Anthropic e il suo progetto Computer Use, che ha aperto la strada a nuove forme di interazione tra AI e browser. Successivamente, OpenAI ha introdotto Operator, un ulteriore passo avanti verso la creazione di sistemi sempre più autonomi e versatili.
Oggi ci stiamo avvicinando a sistemi agentic capaci di muoversi sul web come fossero umani: possono navigare, cliccare, compilare moduli e persino prendere decisioni basate su contesti complessi.
In questo articolo ti spiegherò come creare un agente AI personalizzato che, a partire da un semplice prompt, può eseguire attività ripetitive, automatizzare ricerche online – come la ricerca di voli o prodotti su e-commerce – e ridurre drasticamente il tuo Switching Time, ossia il tempo perso passando da un’applicazione all’altra. Il tutto direttamente sul tuo computer e a bassissimo costo.
Ecco ad esempio cosa riesce a fare facilmente.
Di cosa si tratta e a cosa serve
Browser use è uno strumento che consente agli agenti AI di controllare il browser, rendendo accessibili le pagine web e automatizzando processi altrimenti manuali. Immagina di poter:
- Trovare e aggiungere al carrello su Amazon un libro di tua scelta.
- Effettuare ricerche di prezzi e prodotti.
- E, come nell’esempio che ti propongo ora, cercare voli da Milano a New York per il 2 luglio.
Questa tecnologia si pone l’obiettivo di semplificare compiti ripetitivi e noiosi, ottimizzando il tempo speso tra un click e l’altro.
E, sentendo loro, lo fanno molto bene:
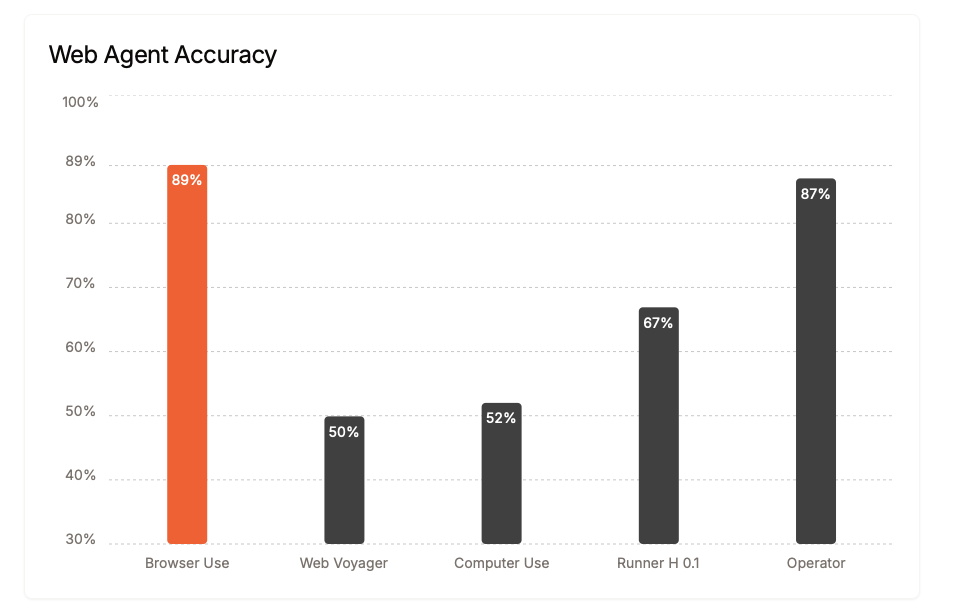
ingredienti
Per mettere in pratica questa “ricetta” ti serviranno:
- Browser Use: lo strumento per collegare l’AI al browser. Consulta la documentazione ufficiale.
- Python 3.11: requisito minimo.
- uv: per la gestione dell’ambiente virtuale (vedi guida su uv ).
- playwright: per l’automazione del browser.
- Un modello LLM: nella prima versione useremo ChatOpenAI (es. gpt-4o-mini), poi passeremo a ChatOllama per ridurre i costi di token.
- (Opzionale) Laminar: per monitorare e loggare le attività svolte dall’agente.
- Variabili d’ambiente: per gestire le API key in sicurezza (OPENAI_API_KEY, ANTHROPIC_API_KEY, LAMINAR_API_KEY, ecc.).
Livello di difficoltà
Apparente:
1/5 – Decaffeinato: sembra sia sufficiente inserire un prompt e attendere che l’agente finisca… non è così
Reale:
5/5 – Doppio espresso: Il contenuto richiede una discreta dimestichezza con Python, l’utilizzo di ambienti virtuali e la gestione delle API. Chi è alle prime armi con l’automazione e con questi mondi perderà un bel po’ di tempo e pazienza su aspetti di contorno.
Tempo di preparazione
30-60 minuti: tempo sufficiente per installare l’ambiente, configurare le chiavi API e far girare il primo agente che naviga per te.
procedimento
1. Preparare l’ambiente
- Crea un ambiente virtuale con uv (assicurati di usare Python 3.11 o superiore):
uv venv --python 3.11Attiva l’ambiente:
# Mac/Linux: source .venv/bin/activate # Windows: .venv\\Scripts\\activate - Installa Browser Use e le altre dipendenze:
uv pip install browser-use - Installa Playwright:
playwright install
2. Configurare le API Key
Crea un file .env nella root del progetto e inserisci le chiavi API per i vari modelli (es. OpenAI, Anthropic, eventualmente Laminar):
OPENAI_API_KEY=your_openai_api_key
ANTHROPIC_API_KEY=your_anthropic_api_key
LAMINAR_API_KEY=your_laminar_api_key
3. Versioni dell’agente
Versione 1 – Semplice e con OpenAI
Questa versione utilizza ChatOpenAI (ad es. gpt-4o-mini) per eseguire task come la ricerca di un libro su Amazon e, aggiuntivamente, una richiesta di voli.
Esempio 1: Ricerca e aggiunta al carrello di un libro
from langchain_openai import ChatOpenAI
from browser_use import Agent
from dotenv import load_dotenv
load_dotenv()
import asyncio
llm = ChatOpenAI(model="gpt-4o-mini")
async def main():
agent = Agent(
task="Find the book called 'Assumere un'intelligenza artificiale in azienda' on amazon.it, then add it to the cart. Then ask for user input",
llm=llm,
save_conversation_path="logs/conversation.json" # Save chat logs
)
result = await agent.run()
print(result)
asyncio.run(main())
Esempio 2: Ricerca voli da Milano a New York
Questo il risultato (notate che qui ho usato gpt-4o, gli altri modelli non riuscivano)
INFO [agent] ???? Result: Here are 3 flights from Milan to New York on July 2, 2025:
1. Flight on July 2, 2025 - Price: €499
2. Flight on July 3, 2025 - Price: €499
3. Flight on July 4, 2025 - Price: €576
Versione 2 – Utilizzo di Ollama per ridurre i costi
Passiamo ora a ChatOllama, che permette di utilizzare un LLM locale con costi ridotti, e aggiungiamo alcune opzioni extra.
from langchain_ollama import ChatOllama
from browser_use import Agent, SystemPrompt
from dotenv import load_dotenv
import asyncio
load_dotenv()
llm = ChatOllama(model="qwen2.5:latest", num_ctx=32000)
class MySystemPrompt(SystemPrompt):
def important_rules(self) -> str:
# Regole esistenti + aggiunta della nuova regola
existing_rules = super().important_rules()
new_rules = "\\n1. IMPORTANT RULE: - ALWAYS use HTTPS!!!"
return f'{existing_rules}{new_rules}'
async def main():
agent = Agent(
task="Cerca il libro '-Assumere un'intelligenza artificiale in azienda-' di Massimiliano Turazzini su Tecniche Nuove e dimmi il prezzo",
llm=llm,
system_prompt_class=MySystemPrompt,
save_conversation_path="logs/conversation.json"
)
result = await agent.run()
print(result)
asyncio.run(main())
N.B.: Puoi adattare anche questo esempio per la ricerca voli modificando il task in modo simile a quanto fatto in Versione 1.
Versione 3 – Ollama con opzioni full-optional e Laminar per l’audit
Questa versione integra un motore di logging esterno (Laminar) e una personalizzazione avanzata del prompt di sistema. È indicata per chi vuole un controllo maggiore sul processo e la possibilità di effettuare il parsing della cronologia delle azioni.
"""
Questo script utilizza un agente basato su LangChain e Ollama per eseguire ricerche sul web,
includendo il logging con Laminar e un SystemPrompt personalizzato.
"""
from langchain_ollama import ChatOllama
from browser_use import Agent, SystemPrompt
from dotenv import load_dotenv
import asyncio
import os
from lmnr import Laminar
# Carica le variabili d'ambiente
load_dotenv()
# Inizializza Laminar per il logging (opzionale)
Laminar.initialize(project_api_key=os.getenv("LAMINAR_API_KEY"))
# Inizializza il modello locale con Ollama
llm = ChatOllama(model="qwen2.5:latest", num_ctx=32000)
# Disabilita la telemetria anonima
os.environ["ANONYMIZED_TELEMETRY"] = "false"
class MySystemPrompt(SystemPrompt):
def important_rules(self) -> str:
existing_rules = super().important_rules()
new_rules = "\\n1. Important: - ALWAYS USE HTTPS!!!"
return f'{existing_rules}{new_rules}'
def format_agent_history(history_object):
# Recupera e formatta la cronologia delle azioni per facilitarne la lettura
all_actions = getattr(history_object, "all_results", [])
def format_action(action):
status = "✅ Completato" if action.get('is_done') else "⏳ In corso"
content = action.get('extracted_content', 'Nessun contenuto')
error = action.get('error', None)
output = f"{status}\\n"
if content:
output += f"???? Contenuto estratto:\\n{content}\\n"
if error:
output += f"❗ Errore: {error}\\n"
return output
for i, action in enumerate(all_actions, start=1):
print(f"--- Azione {i} ---")
print(format_action(action))
print("=" * 40)
async def main():
original_task = "Search the Book -Assumere un'intelligenza artificiale in azienda- on google.it and tell me the first price you find"
# Esempio: qui potresti aggiungere anche la richiesta di voli modificando il task
# Per esempio, per una ricerca voli, potresti usare:
# original_task = "Cerca voli da Milano a New York per il 2 luglio su google.it e mostrami il primo prezzo trovato"
improve_task = False
if improve_task:
improvement_instruction = (
"You are an expert prompt engineer for web navigation agents. "
"The following task needs to be executed by an agent that automatically navigates the web, "
"ensuring safe and accurate data retrieval. "
"Please improve the following task prompt by making it more detailed and specific, including any necessary steps, "
"constraints, and instructions to ensure successful web navigation and data extraction. "
"No confabulations: only output the straight prompt, no titles, introductions or closing statements.:\\n\\n"
f"Original Task: {original_task}"
)
improved_task = llm.invoke(improvement_instruction)
execute_task = improved_task.content
print("Prompt migliorato:", improved_task)
else:
execute_task = original_task
agent = Agent(
task=execute_task,
llm=llm,
system_prompt_class=MySystemPrompt,
save_conversation_path="logs/conversation.json"
)
result = await agent.run()
print(format_agent_history(result))
asyncio.run(main())
Risultato atteso
Dopo aver eseguito uno dei vari script, otterrai un agente AI in grado di navigare sul web, recuperare informazioni (ad esempio, il prezzo di un libro o la ricerca di voli) e registrare i passaggi eseguiti. La versione completa, oltre a restituire il risultato finale, genererà, oltre a una cronologia dettagliata, anche un riepilogo delle schermate principali come questo).

(anche se il task è finito, per qualche motivo non ha messo tutte le schermate)
Note finali
Modelli e capacità: accuratezza, costi e ragionamento
Se il costo dei token è una preoccupazione, prova a utilizzare ChatOllama al posto di ChatOpenAI. In questo modo potrai sfruttare un LLM locale riducendo le spese. Attenzione però che i modelli a disposizione in locale sono molto meno potenti e tendono a deviare di molto dall’obiettivo (io ho provato con Qwen 2.5).
Infatti, come sappiamo, non tutti i modelli funzionano allo stesso modo. Le capacità di ragionamento, la gestione dei token e le competenze multimodali – considerando che il sistema utilizza la vision di default – sono fondamentali. Ad esempio, con QWEN ho dovuto specificare esplicitamente l’utilizzo di Google per evitare che una ricerca sul prezzo dei token (come nel caso del prompt “Compare the token price of openai gpt-4o and DeepSeek-V3”) portasse a risultati da siti di criptovalute. Inoltre, LLama 3.2 in locale non è riuscito a interpretare correttamente il system prompt di Browser-Use, mentre 4o-mini si è dimostrato meno performante rispetto a 4o. Rimane anche il problema del supporto a GROQ. Un episodio lampante è stato quando, chiedendo all’agente di aggiungere al carrello su Amazon il mio libro, il modello ha finito per acquistare un titolo diverso; solo dopo aver corretto il prompt, dopo 31 passaggi e diversi token, l’agente ha iniziato a comportarsi come previsto. Questi esempi evidenziano l’importanza di scegliere il modello giusto e di affinare il prompt per ottenere risultati affidabili.
Salvataggio della cronologia delle azioni (agent_history.gif)
Un aspetto interessante è che, oltre al salvataggio dei log in formato JSON, il sistema è in grado di generare un file agent_history.gif che documenta visivamente tutti i passaggi effettuati dall’agente come quelli che avete visto in questi articoli. Se desideri conservare una traccia completa delle azioni, potrai recuperare questo file manualmente – al momento non è previsto un controllo automatico sul nome del file – e utilizzarlo per analisi e audit delle operazioni svolte.
La cosa difficile: monitoraggio e controllo dell’output
Il vero banco di prova resta il controllo dell’operato dell’agente: verificare se esegue correttamente le operazioni, evitando sprechi di token, tempo ed energia. Come approfondito nei miei post (link alla fine), il monitoraggio continuo è essenziale. Ho lavorato per sistemare l’output, rendendolo più leggibile, ma resta un’area che richiede interventi di programmazione “hard” per garantire affidabilità e precisione. Per questo motivo, nella versione completa è stato attivato un servizio di monitoraggio – che parte gratuitamente – in grado di dare un’idea precisa dei costi, dei token consumati e della quantità di traffico generato. Si chiama laminar e lo trovi su lmnr.ai
In ogni caso…
C’è molto da sperimentare. Questo post, tanto per cambiare, serviva ad accendere il tuo interesse verso questo nuovo tipo di agenti che stanno iniziando a muoversi per il web.
Pronto a rendere il tuo sito “Agent Friendly”?
Feedback
Mi piacerebbe sapere come hai integrato queste soluzioni nei tuoi workflow: quali task hai automatizzato? Hai sperimentato sia con modelli remoti che con LLM locali? Condividi la tua esperienza nei commenti o contattami su Twitter e maxturazzini.com.
Link utili
- Documentazione Browser Use
- Guida Quickstart di Browser Use
- Repository GitHub di Browser Use
- Community Discord di Browser Use
- Post approfondito sugli agentic systems sul mio blog
Dietro le quinte
Dietro le quinte, la creazione di questo articolo è stata per me un processo davvero impegnativo e iterativo. Inizialmente ho sperimentato con il modello o3-mini-high, che mi ha fornito spunti molto articolati e una serie di dettagli tecnici da approfondire. Durante questa fase, ho anche effettuato alcune ricerche su Internet per integrare informazioni ufficiali sulla documentazione di Browser Use, esempi di codice e indicazioni pratiche, così da arricchire il contenuto con dati reali e aggiornati.
Il codice presente nell’articolo è stato copiato dalla documentazione di Computer Use e successivamente rifinito sia con il supporto del modello o3-mini-high che utilizzando l’editor di codice di Cursor.ai, che mi ha permesso di ottimizzare alcune sezioni e migliorare la leggibilità del codice.
Successivamente, ho spostato l’attenzione su o3-mini, un modello che ha offerto risposte più sintetiche e dirette, perché… stavo finendo le possibilità. . L’obiettivo era bilanciare l’accuratezza tecnica con una comunicazione più “leggera” e immediata, in linea con lo stile di AI, Cookbook.
Da lì è iniziato il lavoro di editing manuale: decine di prove e modifiche sono state necessarie per rifinire ogni paragrafo, assicurandomi che ogni sezione fosse chiara e che il messaggio finale ispirasse i lettori a sperimentare questi strumenti. Anche l’utilizzo della funzione “edit in canvas” di ChatGPT non è andato come speravo: tendeva a riassumere eccessivamente i contenuti, costringendomi a lavorare un paragrafo alla volta per mantenere la ricchezza delle informazioni.
È stato un percorso fatto di aggiustamenti, correzioni e continue ottimizzazioni, con l’intento di trasmettere un’esperienza reale e trasparente di come si lavora con questi agenti AI. Spero davvero di averti ispirato e di averti dato spunti utili per avventurarti anche tu in questo affascinante mondo!






{kind=link}
Bravo Max, articolo semplice chiaro e molto utile.
Grazie 🙂