


Pregi e difetti dell’architettura che integra due unità di elaborazione complete e autonome all’interno di un singolo package
agosto 2006 I tempi in cui ogni nuova versione di un processore assicurava
un incremento di prestazioni dell’ordine di qualche punto percentuale sembrano
prossimi al termine. Nei lunghi anni in cui la microarchitettura di ciascuna
famiglia di processori si è mantenuta relativamente stabile, le principali
strategie per l’aumento di prestazioni sono state più o meno le solite:
- Aumentare il clock del processore, per eseguire più velocemente
quelle operazioni complesse che non richiedono un continuo interscambio di
dati con la memoria; - Aumentare la quantità di cache integrata nel processore, per ridurre
il più possibile il bisogno di ricorrere alla memoria esterna; - Aumentare la larghezza di banda verso la memoria esterna e abbassarne la
latenza, così che, quando il dato cercato non si trovasse nella cache,
lo si potrebbe recuperare nel più breve tempo compatibile con la tecnologia
delle RAM dinamiche.
In altre parole, volendo fare un paragone fra una CPU e un motore, quel che
si è fatto negli ultimi anni nell’ambito di ogni famiglia di processori
è stato semplicemente un tentativo di raggiungere regimi di rotazione
sempre più alti, ottimizzando aspirazione e scarico per non vanificare
i vantaggi conseguibili per aver spinto il motore in piena “zona rossa”.
Il motore, però, è rimasto praticamente sempre lo stesso.
Ci sono però altri modi per aumentare le prestazioni di un motore:
aumentare la cilindrata a parità di cilindri, per far sì che a
ogni rotazione dell’albero il motore compia un maggior lavoro, o aggiungere
cilindri, per aumentare la potenza in misura quasi proporzionale al loro numero.
Va sottolineato che entrambe le strategie aumentano le prestazioni a parità
di regime di rotazione del motore, e che entrambe assicurano un guadagno di
potenza quasi proporzionale all’incremento di cilindrata o di cilindri.
Nel mondo delle CPU, l’equivalente dell’aumento della cilindrata è
in un certo senso paragonabile al passaggio da 32 a 64 bit.
In un processore a 64 bit i registri si allungano, così ogni operazione
in aritmetica intera può trattare una mole di dati esattamente doppia
rispetto a prima. Anche il data path verso la memoria solitamente si allarga,
con effetti benefici sulla banda fra CPU e RAM. Infine, lo spazio di memoria
indirizzabile aumenta in modo estremamente rilevante, grazie al passaggio da
32 a 64 bit anche nei registri di indirizzamento. Insomma, il “cilindro”
viene reso più grande e, parallelamente, si cerca di fare in modo che
possa anche “respirare” meglio.
Tuttavia, c’è un limite al beneficio ottenibile su questa strada. Se
la maggior parte dei programmi lavora con numeri piccoli che potrebbero benissimo
stare in un registro a 32 bit, non si ha alcun vantaggio dalla semplice introduzione
di registri di estensione maggiore. Con numeri “piccoli” i bit aggiuntivi
non serviranno, e se il clock del processore rimarrà uguale, il tempo
richiesto per una somma fra due numeri rimarrà esattamente lo stesso
di prima.
Se i programmi lavorano con quantità di dati non esorbitanti, tali
da poter essere contenute nella cache nella maggior parte delle situazioni operative
tipiche, accadrà relativamente di rado che i dati debbano essere recuperati
dalla RAM. Quindi, un raddoppio della larghezza del canale verso la RAM porterà
benefici solo in fasi infrequenti dell’elaborazione.
Se, infine, i programmi in esecuzione in un dato momento lavorano con una
quantità di dati complessiva troppo grande per la cache, ma abbastanza
piccola per poter stare in uno spazio di memoria a 32 bit (meno di 4 Gbyte),
il fatto di disporre, con CPU a 64 bit, di uno spazio di memoria 4 miliardi
di volte maggiore non incide realmente sulle prestazioni ottenibili. Per questo
è poco probabile che a breve l’industria intraprenda un passaggio da
64 a 128 bit nei processori general purpose: probabilmente, escludendo l’ambito
server e la sua insaziabile “fame” di memoria, con la maggior parte
dei PC e delle applicazioni individuali siamo ancora lontani dall’aver pienamente
bisogno dei 64 bit.
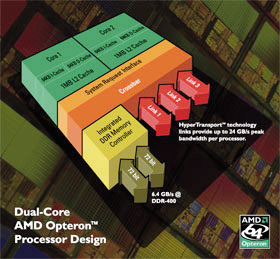
Nei processori dual core l’interconnessione fra i due core integrati nella
CPU può avvenire attraverso il system bus, oppure tramite una crossbar
ad alta velocità. Ogni core disponde di una propria cache, oppure può
esservi una cache condivisa in modo dinamico.
Una CPU bicilindrica
Rimane l’altra strategia: l’aumento del numero di cilindri. In prima approssimazione,
in un motore monocilindrico, l’aggiunta di un secondo cilindro identico al primo
raddoppia quasi esattamente la potenza disponibile. L’equivalente in una CPU
è l’aggiunta di un secondo core identico al primo, operante alla stessa
frequenza e basato sulla stessa microarchitettura.
La potenza di calcolo disponibile sarà quasi esattamente doppia, a condizione
che i due core non risentano l’uno della presenza dell’altro, ad esempio per
concorrenza nell’accesso al bus, alla cache o alla memoria. Questi rischi sono
reali e ineliminabili, ma con una progettazione accurata è possibile
attenuarli in misura notevole.
Ma non è tutto. L’architettura dual core aiuta anche a ridurre
i consumi. Nei motori, un corretto frazionamento della cilindrata totale
porta a un funzionamento più regolare e a un miglior rendimento energetico.
Anche per le CPU, basate su tecnologia a semiconduttore, esistono considerazioni
fisiche ed energetiche che legano prestazioni, consumi e frequenza di funzionamento.
In particolare, l’aumento sfrenato di clock ha una ripercussione severa sui
consumi. Infatti, la potenza assorbita dai transistor che compongono la CPU
dipende dalla frequenza con cui viene loro richiesto di cambiare stato. L’esperienza
mostra, però, che al crescere della frequenza di lavoro le prestazioni
crescono meno della frequenza, mentre il consumo elettrico cresce ancora più
velocemente della frequenza.
In altre parole, un aumento del 10% del clock può tradursi in un aumento
di potenza elettrica assorbita pari al 15% o più. Per questo motivo,
la strada dell’aumento di frequenza della CPU per aumentare le prestazioni non
è percorribile all’infinito; tutta la potenza elettrica assorbita, infatti,
finisce con il tramutarsi in calore che deve essere asportato per evitare danni
irreparabili alla CPU.
Dopo anni di crescita, il consumo energetico specifico di alcune CPU
x86 ad alte prestazioni ha raggiunto il livello di alcune decine di
nanoJoule per istruzione eseguita (nJ/instr): urge una inversione di rotta,
e soprattutto un ripensamento degli obiettivi di progetto rispetto all’epoca
attuale, in cui l’unità di misura più importante erano i MIPS
per MHz, se non i MHz tout court.
Semplificando al massimo, supponiamo che un core operante a 2 GHz assorba
50 W, e che un core operante a 4 GHz, ammesso di riuscire a costruirlo e raffreddarlo
in modo adeguato, assorba non 100 ma 150W. Il raddoppio della frequenza ci è
costato un triplicamento di potenza elettrica assorbita (nonché del sistema
di raffreddamento).
Se avessimo invece accostato due CPU da 2 GHz, il consumo elettrico totale
sarebbe stato di 50+50=100 W; in altre parole, l’aumento dei consumi elettrici
risulterebbe direttamente proporzionale all’aumento della frequenza. Inoltre,
fabbricare un numero doppio di CPU a 2 GHz è molto più facile,
è tecnicamente fattibile fin da oggi ed è industrialmente più
conveniente che concentrare tutte le forze sullo sviluppo di CPU a 4 GHz.
La prima lezione che se ne trae è: grazie alla tecnologia dual core,
possiamo aumentare da subito in modo molto significativo le prestazioni mantenendo
sotto controllo il problema dei consumi elettrici e quello della dissipazione
termica.
Ma possiamo anche ribaltare il discorso e osservare che se oggi siamo in grado
di produrre una CPU a 2 GHz che consuma 50 W, sicuramente è alla nostra
portata la produzione di due CPU a 1 GHz, fra l’altro a costo assai basso (grazie
alla tecnologia più semplice e già matura e, magari, alla possibilità
di riutilizzare la capacità produttiva in eccesso delle fabbriche “vecchie”).
Per effetto della non linearità della relazione fra consumi elettrici
e clock, la CPU a 1 GHz consumerebbe non 25, ma magari solo 15 W. Quindi potremmo
da subito costruire un processore dual core, con 2 core operanti alla frequenza
di 1 GHz, che garantirebbe più o meno le stesse prestazioni del processore
singolo da 2 GHz, ma con un consumo di soli 15+15=30 W anziché 50 W.
La seconda lezione è quindi: grazie alla tecnologia dual core possiamo
costruire processori potenti come quelli attuali, ma con un consumo elettrico
sensibilmente più basso.
Ma attenzione: la parità di potenza di calcolo totale non significa
prestazioni equivalenti in tutte le condizioni d’uso. Una CPU dual core può
non produrre le stesse prestazioni percepite di un processore single core con
uguale potenza di calcolo.
Questo succede quando i programmi non sono scritti per avvantaggiarsi
di un processore dual core e quindi, invece di far eseguire in parallelo
a ogni core metà delle operazioni dell’algoritmo, le fanno eseguire tutte
a un solo core. In questo caso il processore dual core è sfruttato per
metà, in quanto il secondo core non viene fatto lavorare dall’applicazione.
In tali circostanze, le prestazioni percepite dall’utente con processore dual
core sarebbero quindi inferiori del 50% a quelle assicurate dal processore tradizionale.
Non è solo per incuria o negligenza dei programmatori che un applicativo
può non usare in modo ottimale la potenza dei core disponibili. Alcuni
algoritmi sono intrinsecamente sequenziali e non sono parallelizzabili per motivi
concettuali. Altri sono parallelizzabili, ma con un degrado di efficienza tanto
maggiore quanto maggiore è il numero di esecutori fra i quali viene distribuito
il lavoro.
Per fare un paragone, se un uomo impiega 10 minuti per svolgere da solo un
determinato compito manuale, l’esperienza insegna che 10 uomini attrezzati allo
stesso modo non riescono a completare tutti insieme lo stesso lavoro in un decimo
del tempo, ma ne impiegano di più. I motivi possono essere conflitti
nell’accesso alle risorse, inefficienze dovute alla necessità di coordinare
e regolare il lavoro degli esecutori, dipendenze ineliminabili fra il lavoro
di un esecutore e quello degli altri.
Il dual core in contesto reale
Nel caso di un processore dual core, si può dire che il massimo beneficio
in termini di prestazioni percepite si può ottenere se il principale
lavoro da svolgere, quello più gravoso e sul quale si concentra maggiormente
l’attenzione dell’utente, è organizzato in modo tale da poter essere
ripartito esattamente al 50% fra i due core, anche se tale task capita solo
in modo occasionale. Questo risulta facile se vi è un solo processo da
eseguire, e tutte le operazioni svolte da questo processo sono codificate in
modo parallelo, cosa non sempre possibile, come già discusso.
Il massimo sfruttamento della potenza di calcolo del processore si ottiene,
invece, facendo sì che i due core siano costantemente tenuti carichi
al 100%. Anche senza politiche di scheduling ad hoc, questa condizione può
prodursi quasi spontaneamente in un sistema multitasking con un gran numero
di processi che effettuano più elaborazione che I/O: quando un processo
in esecuzione su un core si sospende per attesa dati, il sistema operativo può
trasferire il controllo a un altro processo pronto per l’esecuzione.
La situazione in un PC reale è intermedia fra questi due estremi: vi
sono alcune decine di processi, e solitamente uno di essi è quello su
cui si concentra l’attenzione dell’utente (in genere è l’applicazione
in foreground, oppure la shell: Windows Explorer). L’utente si aspetta che l’applicazione
in primo piano sia eseguita alla massima velocità possibile, ma anche
che gli altri processi in background evolvano senza rallentare la macchina.
Su macchine come i server, impiegati per eseguire un gran
numero di compiti relativamente brevi, l’architettura dual core produce vantaggi
evidenti sulla latenza di esecuzione perché aumenta la probabilità
di trovare un core almeno parzialmente scarico quando arriva il nuovo task da
eseguire: questo può quindi iniziare subito, seppure magari a velocità
ridotta, e il client remoto non resterà in attesa per troppo tempo. In
molte applicazioni interattive, ad esempio Web server, la riduzione della latenza
conta più dell’aumento di velocità reale.
Altra situazione in cui il dual core è spesso in vantaggio sul single
core si verifica quando un task pesante, per esempio un antivirus,
debba essere eseguito in background senza rallentare troppo
il funzionamento del task in foreground (per esempio il word
processor o il Web browser). Soprattutto, non si vuole che l’antivirus provochi
occasionalmente dei momenti di “sordità” completa del PC
alle sollecitazioni dell’utente (tastiera, mouse). Se l’antivirus gira su uno
dei due core, ciò comporta un limite invalicabile alla CPU power che
può essergli destinata: al massimo il 50%. L’altro core resta sempre,
almeno parzialmente, scarico per lancio di nuovi programmi o per eseguire senza
intoppi l’applicazione in primo piano.
Da tutto ciò deduciamo una terza lezione: dal punto di vista delle
prestazioni percepite, il dual core è in vantaggio in certe situazioni,
e in svantaggio in altre. L’architettura più adatta dipende dal tipo
di utilizzo previsto (single task o multitask; workstation o server) e dal tipo
di applicazioni (ottimizzate per multicore oppure no), ma anche dalle aspettative
dell’utente: se conta di più la performance dell’applicazione in primo
piano, ed è spesso il caso dei giochi, meglio un single core ad altissima
frequenza. Se conta di più la riduzione della latenza in un sistema multitasking,
meglio un dual core.
Meglio, però, abituarsi fin d’ora al termine “multicore”,
dal momento che verso la fine del 2006 si cominceranno a vedere i primi processori
x86 quad core a 65 nm, mentre le roadmap parlano già di processori a
8 core per il 2008.






{kind=link}