

{kind=link}
Ciao a tutti, sono Vincenzo Lomonaco, ricercatore e docente all’Università di Pisa.
Nella puntata di oggi torniamo a parlare di visione artificiale e in particolare di object detection, ossia come rilevare all’interno di un’immagine la posizione e l’identità di uno o più oggetti di interesse.
Nella puntata precedente abbiamo discusso già di YOLO, un metodo classico e molto efficiente, basato su reti a convoluzione, ma è questo l’unico modo che abbiamo di implementare un sistema di rilevamento di oggetti.
Oggi sappiamo che, soprattutto per l’elaborazione del linguaggio naturale, l’architettura Transformers si è dimostrata particolarmente efficace.
E possibile applicarla anche in questo contesto? Scopriamolo insieme in questa puntata di Le Voci dell’AI.
Dopo il grande successo ottenuto nel campo dell’elaborazione del linguaggio naturale, i Transformers che abbiamo introdotto e spiegato nel dettaglio nella puntata 97 di Le Voci dell’AI, hanno trovato applicazione anche nel mondo della visione artificiale, rivoluzionando un settore tradizionalmente dominato dalle reti a convoluzione convolutional neural networks.
L’introduzione dei Vision Transformers, ViTs ha dimostrato che l’autoattenzione, questo cuore computazionale dei Transformers, può superare le CNN in compiti di classificazione immagini su larga scala.
Il ViT suddivide un’immagine in patch, in pezzettini, trattandoli come sequenze analoghe alle parole dei testi, permettendo così di modellare relazioni globali tra parti molto distanti tra loro nell’immagine, cosa difficile da realizzare con le reti a convoluzione che operano per lo più localmente.
Oltre al riconoscimento di oggetti, quindi la classificazione, i Transformers si sono estesi con successo ad attività come la segmentazione semantica, l’object detection per l’appunto, e la generazione di immagini, grazie a modelli, come DETR – DEtection TRansformers e i Diffusion Models, guidati da architetture più complesse ma comunque basate su Transformers.
Questi approcci beneficiano della capacità di catturare contesti ampi e flessibili, adattandosi a dati multimodali e migliorando la scalabilità con dataset di grandi dimensioni.
Tuttavia, l’alto costo computazionale dei Transformers rappresenta ancora una sfida e spinge la ricerca verso architetture ibride e ottimizzate.
In questa puntata di Le Voci dell’AI ci focalizziamo su DETR e su come questo rappresenti un’alternativa validissima all’approccio classico e intuendo offerto da YOLO e le sue varianti che abbiamo visto nella puntata precedente.
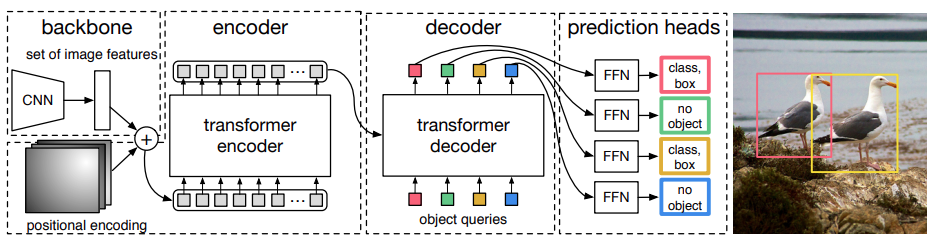
In questa immagine vediamo l’architettura originale di DETR – Detection Transformer, un modello che ha rivoluzionato il campo dell’oggetto detection, trattando il compito come un problema di corrispondenza diretta tra oggetti e predizioni ed eliminando per la prima volta la necessità di fasi di post-processing come la Non-Maximum Suppression (NMS), un’operazione molto tediosa, difficile da calibrare, necessaria anche in YOLO per eliminare rilevamenti multipli dello stesso oggetto, anche a meno di scostamenti di pochi pixel.
È cruciale sottolineare che, nonostante DETR sia noto per l’uso dei Transformers, si basa comunque su una solida backbone convoluzionale, che vedete sulla sinistra, per l’estrazione delle figure visive di basso livello.
Questa backbone è spesso una ResNet, una rete a convoluzione classica genera una mappa compatta di features sfruttando la forza delle convoluzione nel catturare pattern locali, quindi mettendo insieme pixel vicini.
Alcune proposte più recenti sicuramente hanno cercato di eliminare del tutto anche i livelli di convoluzione in favore di architetture Transformers pure, ma tali soluzioni si sono rilevate meno efficaci ad oggi, nel gestire immagini ad alta complessità del preservare dettagli spaziali molto fini.
Seguendo il diagramma da sinistra verso destra, le figure estratte dalla CNN vengono poi arricchite tramite un positional encoding, per la codifica della posizione che come abbiamo detto in passato, manca all’interno dei Transformers almeno nativamente.
E poi queste features posizionali vengono inviate al Transformer Encoder, che applica un meccanismo di autoattenzione – self attention – per modellare le relazioni tra tutte le parti dell’immagine.
Questo consente al modello di aggregare informazioni contestuali a lungo raggio e migliorare la comprensione strutturale della scena nella sua totalità.
In seguito queste figure elaborate vengono processate da un decoder che riceve un set fisso di Object Queries, vettori a pesi, che funzionano come ancore flessibili.
Ogni query compete per “attendere” di specializzarsi su specifiche regioni e predirre oggetti distinti.
Infine, le uscite del decoder passano attraverso i prediction heads composti da semplici reti neurali tradizionali completamente connesse ogni head produce quindi due risultati: la classe predetta, compresa un’etichetta speciale “no object” che segnala l’assenza di un oggetto e le coordinate della bounding box, il riquadro che dovrebbe circondare l’oggetto di interesse rilevato. Durante l’addestramento, DETR utilizza un algoritmo di back matching bipartito che associa in modo ottimale le predizioni con gli oggetti reali, quindi le etichette, evitando duplicazioni e la necessità della non maximus attraction.
Nell’esempio a destra, infine, si vede come due query abbiano rilevato correttamente i due gabbiani nell’immagine, mentre altre query siano rimaste inattive assegnate a “no object”.
In sostanza, DETR riesce a combinare efficacemente la potenza locale delle CNN con la flessibilità globale dei Transformer, mantenendo le convoluzioni come parte essenziale della pipeline, a differenza di modelli che le eliminano completamente ma con risultati inferiori.
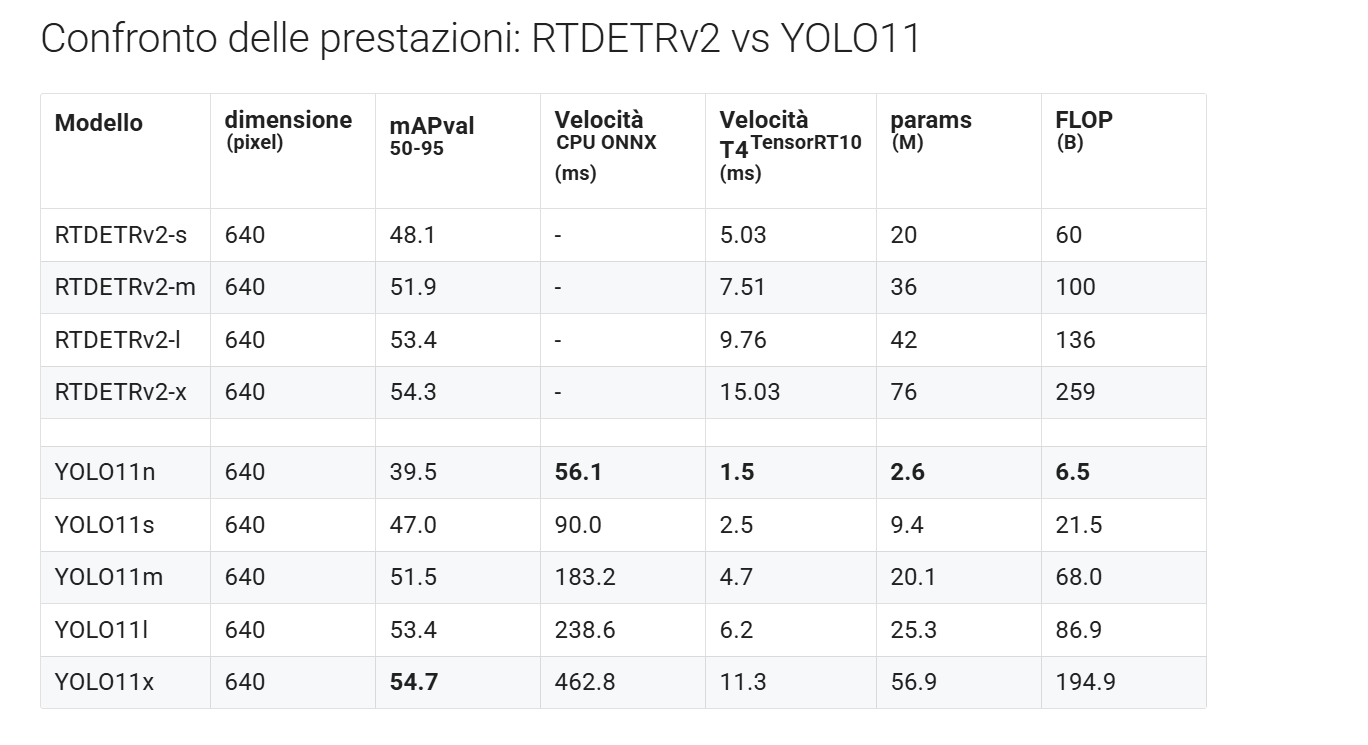
In questa tabella invece vediamo un confronto dettagliato tra le ultime evoluzioni delle due famiglie di modelli per l’object detection, RTDETRv2 e YOLO11, entrambe costruite sui concetti che abbiamo già discusso in questa puntata e la precedente, ma ulteriormente ottimizzate.
RTDETRv2, in particolare, rappresenta un’evoluzione più recente di DETR che mantiene l’idea centrale di eliminare la Non Maximus Suppression grazie all’uso di Transformer, ma introduce migliorie significative in termini di velocità, rendendolo un modello competitivo anche per scenari real time, proprio come YOLO e YOLO11, l’ultima versione sviluppata dall’azienda Ultralytics. Vediamo che in questi risultati riportati dalla stessa azienda YOLO11x raggiunge il miglior average position su COCO, un benchmark classico per l’object detection, con un risultato di 54.7, leggermente superiore al top di gamma di DETR, la versione x, che raggiunge 54.3.
Inoltre YOLO11 risulta anche più veloce, soprattutto nella variante più leggera YOLO11n, che raggiunge tempi di inferenza di appena 1.5 millisecondi su CPU TensorRT, contro i 5, pressappoco del più piccolo DETR, DETR-s.
Anche in termini di parametri e complessità computazionali Flows YOLO11 mostra dei vantaggi significativi.
Per esempio, la versione n conta solo 2.6 milioni di parametri e 6.5 miliardi di flop contro i 20 milioni di parametri e 60 miliardi di flop di DETR-s.
Tuttavia è importante sottolineare che i risultati qui riportati provengono direttamente dal sito di Ultralytics, quindi potrebbero riflettere ottimizzazioni specifiche per il loro ecosistema.
Ecco, nonostante YOLO11 qui dimostri un chiaro vantaggio nelle metriche di velocità, DETR, in questa sua versione Real-Time ottimizzata rimane competitivo grazie alla sua robustezza architetturale.
I modelli DETR, infatti si distinguono per la loro capacità di gestire relazioni complesse tra oggetti e scene grazie al meccanismo dell’attenzione che li rende anche più scalabili per compiti più avanzati o complessi su set di dati e problemi multiclasse.
Inoltre, esiste la possibilità concreta che varianti più leggere ed efficienti di RT emergano nel futuro prossimo, proprio guardando la crescita e le migliorie ottenute negli ultimi anni in questo contesto, combinando l’efficienza di YOLO con la potenza strutturale dei Transformer.
In sintesi, mentre YOLO11 si conferma la scelta attuale per applicazioni in real time, dove la velocità e l’efficienza è critica.
DETRv2 continua a rappresentare una base solida e promettente per futuri miglioramenti nell’object detection basato su Transformer.
Bene, in questa puntata abbiamo introdotto Detection Transformer che da qualche anno sta cominciando ad insidiare il primato di YOLO nel contesto della Object Detection.
Ad oggi le due architetture praticamente si equivalgono a livello di efficacia, anche se per l’efficienza YOLO sembra essere ancora preferibile.
Tutto sommato, però, mettere insieme blocchi computazionali ed elementi di salvataggio sembra essere un’idea vincente per il futuro, soprattutto nell’ottica di offrire con un solo modello molteplici funzionalità di comprensione di un’immagine non solo il rilevamento di oggetti.
Ciao! Alla prossima puntata di Le Voci dell’AI.