

{kind=link}
Ciao a tutti, sono Vincenzo Lomonaco, ricercatore e docente all’Università di Pisa.
Nella puntata di oggi di Le Voci dell’AI parliamo di uno studio molto recente pubblicato dall’Università di San Diego che ha fatto molto discutere nei giorni scorsi.
In questo studio ci si chiede: le grandi soluzioni di intelligenza artificiale come GPT 4.5, GPT-4o e Llama3 superano il test di Turing? Di che test si tratta e perché è un argomento molto interessante e polarizzante, nel contesto dell’intelligenza artificiale moderna? Scopriamolo insieme in questa puntata di Le Voci dell’AI.
Il recente rilascio dell’articolo scientifico intitolato Large Language Models Pass the Turing Test ha scatenato un acceso dibattito nella comunità scientifica e tecnologica dell’intelligenza artificiale, segnando una tappa importante nel dibattito e nella sua evoluzione.
Lo studio, condotto dai ricercatori Johnes e Bergen dell’Università di San Diego, documenta come alcuni modelli linguistici di grandi dimensioni, i Large Language Models, siano riusciti a superare con successo il test di Turing in contesti ovviamente controllati, ovvero a ingannare un numero statisticamente significativo di valutatori umani facendosi passare per esseri umani.
Questo risultato, che fino a pochi anni fa sembra lontano, ha implicazioni profonde: non solo dimostra la crescente sofisticazione di questi agenti di AI nel comprendere e generare il linguaggio naturale, ma solleva anche interrogativi urgenti su autenticità, fiducia e trasparenza nelle interazioni uomo macchina.
Questo articolo scientifico ha avuto un impatto immediato, catalizzando l’attenzione dei media, stimolando reazioni anche contrastanti tra esperti del settore e sollevando preoccupazioni anche etiche legate alla disinformazione, alla manipolazione e all’uso improprio di queste tecnologie.
Allo stesso tempo ha aperto anche nuove prospettive per l’integrazione di queste soluzioni di AI, quindi agenti virtuali al supporto dell’educazione della sanità e molto altro.
Il test di Turing, ideato da Alan Turing nel 1950, è un esperimento pensato per valutare se una macchina possa produrre risposte linguistiche indistinguibili da quelle umane.
In una configurazione classica un valutatore interagisce attraverso del testo in una chat con due interlocutori nascosti, un umano e uno artificiale, senza sapere chi è chi.
Se non riesce a distinguere la macchina dall’essere umano, si considera che l’intelligenza artificiale abbia superato il test.
Nel corso del tempo vari sistemi hanno provato a cimentarsi in questa impresa.
Per esempio negli anni ‘60 un agente AI, Eliza ha sorpreso la comunità per la sua efficacia, utilizzando semplici regole di pattern matching e trasformazioni testuali per generare risposte pertinenti, pur senza alcuna comprensione semantica.
Nel 2014 Eugene Goostman ha fatto lo stesso, in maniera forse ancor più sorprendente, per certi versi basandosi su script definiti una combinazione di parsing lessicale e risposte performattate e mostrando una maggiore varietà linguistica, ma ancora priva di vera consapevolezza e ragionamento profondo.
Stabilire se il test sia stato effettivamente superato o no resta piuttosto complesso. Il risultato dipende da come viene strutturata la verifica, dalla durata del dialogo e dalle aspettative e conoscenze di chi valuta.
Inoltre, molti osservano che il test in realtà misuri la capacità di imitare o confondere piuttosto che l’intelligenza autentica.
Per questo alcuni ritengono il test di Turing più un esercizio di inganno comunicativo che una prova effettiva di comprensione o pensiero artificiale.
Nel paper “Large Language Models Pass the Turing Test”, il protocollo di valutazione è stato progettato in questo modo: i partecipanti non sapevano chi fosse, chi e dovevano, al termine di un dialogo di circa 5 minuti, indicare quali dei due agenti con i quali interloquivano simultaneamente fosse umano. I ruoli venivano assegnati casualmente.
Sono stati testati diversi agenti di AI: GPT-4o, LLama3 ed Eliza e diversi soggetti umani che hanno partecipato al test con diversi background. Ogni valutatore partecipava a otto round con nuovi interlocutori, nuove combinazioni e le conversazioni venivano condotte in modalità asincrona testuale per evitare bias legati alla velocità di scrittura o lo stile di digitazione.
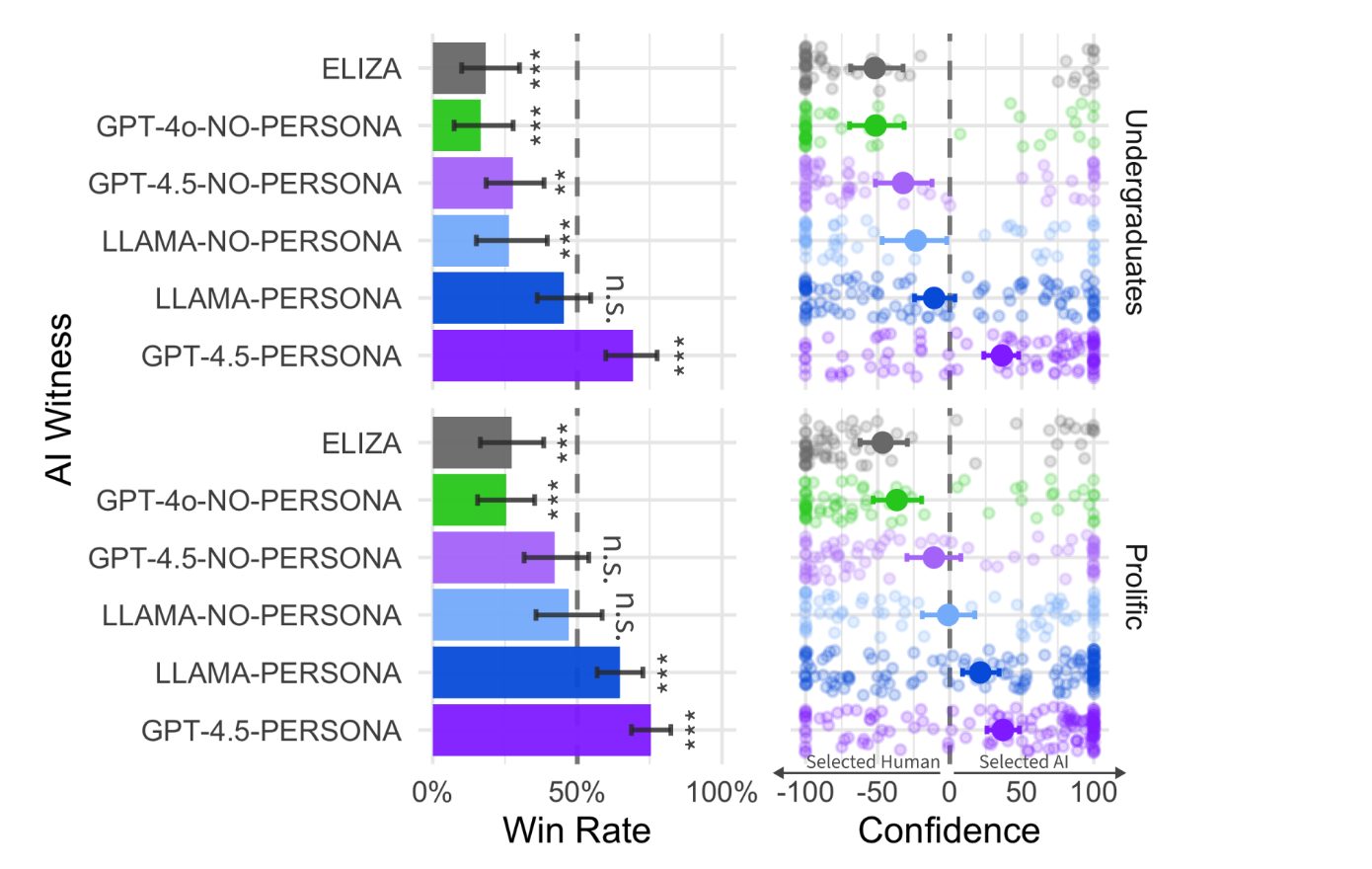
In questa immagine vediamo i risultati principali di quest’analisi, che ha coinvolto circa 300 partecipanti umani.
A sinistra, il grafico delle win rate indica la percentuale di volte in cui l’AI è stata erroneamente identificata come umana.
I modelli più avanzati come GPT 4.5 con questa modalità persona, cioè chiedendo a GPT di interpretare un personaggio specifico, hanno superato il 50% di successo, mentre Eliza e GPT-4 hanno registrato tassi significativamente inferiori.
Le barre di errore rappresentano gli intervalli di confidenza al 95% e gli asterischi segnalano differenze diciamo statisticamente irrilevanti, significative rispetto al caso, il 50%.
A destra, il grafico della confidence, invece, mostra la sicurezza dei valutatori in queste loro risposte e i punti rappresentano singoli test distribuiti lungo l’asse che va dal “sicuro di aver scelto l’AI?” – a sinistra – a “sicuro di aver scelto l’umano?” – a destra.
Si nota che i valutatori tendono ad essere più sicuri quando identificano correttamente un umano rispetto a quando scambiano l’AI per umano.
Le differenze tra Undergraduates, cioè gli studenti triennali e i partecipanti di Prolific, una piattaforma di crowdsourcing online, suggeriscono anche variazioni nella capacità di discriminare tra gruppi con esperienze diverse.
Nel complesso, però, questi risultati indicano che modelli avanzati, Large Language Models allo stato dell’arte, possono superare il Turing Test in condizioni controllate come queste, quindi, anche se la fiducia dei valutatori varia in base al contesto e al modello testato.
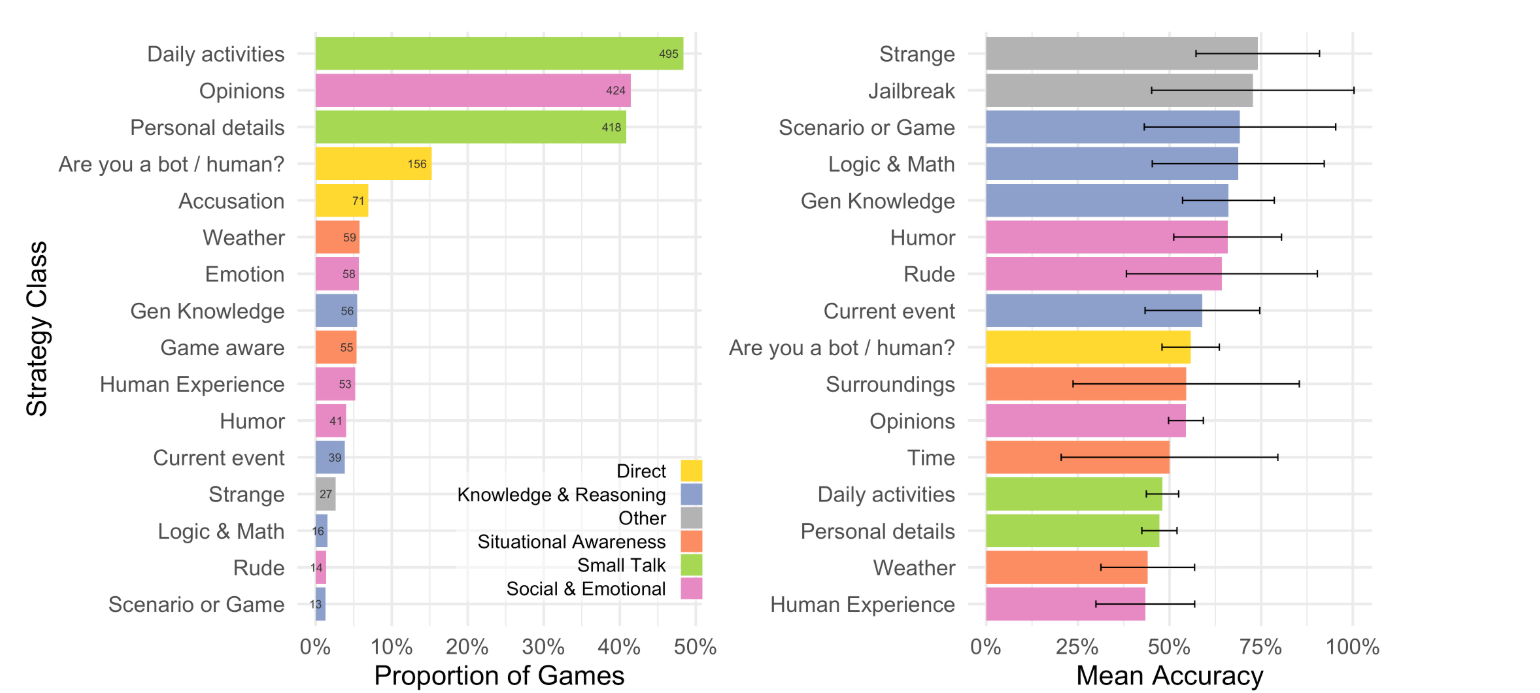
Questa figura mostra invece le strategie utilizzate dagli interrogatori per distinguere gli agenti tra umani e macchine a sinistra e la loro efficacia in termini di accuratezza media a destra.
La strategia più comune, come vedete, nel 61% dei casi è stata lo smalltalk, il chiacchiericcio con domande su attività quotidiana e dettagli personali.
Il 50% delle interazioni ha incluso invece quesiti su emozioni, opinioni e umorismo, mentre nel 19% dei casi gli interrogatori hanno chiesto direttamente se il testimone fosse umano oppure no.
Strategie basate sulla consapevolezza situazionale come domande sul meteo o sul contesto del test sono state usate nel 13% dei casi, mentre solo il 12% ha incluso verifiche su conoscenza specifica e ragionamento.
Il grafico a destra mostra che le strategie più efficaci per identificare correttamente le aree includevano domande “strane” o tentativi di jailbreak, quesiti che forzavano il sistema a rivelare la sua natura. Tuttavia, queste erano le strategie meno usate.
Al contrario, domande su esperienze umane e condizioni meteorologiche si sono rivelate tra le meno efficaci.
Questo suggerisce che i Large Language Models più avanzati sono più abili nel simulare conversazioni quotidiane o rispondere a domande anche personali, mentre hanno maggiore difficoltà con input insoliti o tentativi di manipolazione diretta.
Bene, in questa puntata abbiamo discusso del Turing Test, della sua importanza, ma anche di come superare un solo test non può certamente essere visto come un’evidenza sufficiente a giudicare un’AI indistinguibile dall’uomo, almeno a livello comportamentale o in termini di capacità.
Studi come quello discusso oggi evidenziano però progressi significativi nel simulare o dissimulare comportamenti umani, almeno per quanto riguarda l’interazione tramite il testo.
È ormai chiaro che nei prossimi anni sarà sempre più difficile distinguere l’interazione con uomini o macchine e che questo aprirà le porte a un uso significativo e pervasivo dei chatbot, gli assistenti virtuali, in ogni contesto della nostra sfera digitale.
Ciao! Alla prossima puntata di Le Voci dell’AI!