

{kind=link}
Ciao a tutti, sono Vincenzo Lomonaco, ricercatore e docente all’Università di Pisa.
Nella puntata di oggi ci concentriamo su uno strumento davvero eccezionale che sta spopolando nel web e stupendo tutti per la sua incredibile potenzialità.
Oggi parliamo di GPT-4o Image Generation, forse il miglior strumento di generazione automatica di immagini, azzardo a dire, mai creato dall’umanità.
Di cosa si tratta nel dettaglio e come è stato possibile creare uno strumento così potente? Come funziona nella pratica e quali sono i nuovi scenari applicativi che abilita? Scopriamolo insieme In questa puntata di Le Voci dell’AI.
OpenAI ha recentemente introdotto la generazione di immagini con GPT-4o Image Generation, una nuova funzione integrata in ChatGPT.
Questo aggiornamento consente agli utenti di creare immagini direttamente dalla chat e al momento è disponibile per chi ha un abbonamento Plus, Pro o Team, mentre il rilascio per gli utenti gratuiti è stato rinviato per l’altissima richiesta di utilizzare questo modello, quindi anche le risorse computazionali richieste.
GPT-4 è un modello omnimodale capace di gestire diversi tipi di dati e offre miglioramenti nella coerenza visiva, nella resa del testo all’interno delle immagini, come vedremo.
A differenza di DALL-E che veniva utilizzato all’interno di ChatGPT finora per la generazione di immagini che usava un metodo di diffusione, GPT-4o genera immagini in modo auto regressivo, quindi con una tecnologia e un processo più lento forse, ma con risultati di qualità nettamente superiore.
Per garantire un uso responsabile, OpenAI ha inoltre implementato filtri avanzati per bloccare la generazione di contenuti inappropriati e ha anche incluso nei metadati delle informazioni per segnalare che le immagini sono effettivamente generate dall’AI.
Sul mercato GPT-4o Image Generation si confronta con altri strumenti come MidJourney, noto per la sua creatività, mentre GPT-4o si distingue per immagini più realistiche e dettagliate.
Questa innovazione segna, se vogliamo, un’evoluzione significativa nelle capacità multimodali dell’intelligenza artificiale, offrendo agli utenti uno strumento potente per creare immagini direttamente attraverso il testo.
Ma quali sono stati i passaggi storici chiave dietro questa soluzione di AI? La sintografia è la creazione di immagini attraverso l’intelligenza artificiale, senza l’uso di strumenti tradizionali come fotocamere o pennelli.
Il termine nasce dall’unione di sintesi e grafia, indicando un processo in cui le immagini vengono generate digitalmente a partire da descrizioni testuali o dati preesistenti.
I primi esperimenti risalgono agli anni 2010, con reti neurali in grado di apprendere stili artistici e modificarli come DeepDream di Google.
Nel 2021 OpenAI ha rivoluzionato il settore della sintografia con DALL-E, capace di trasformare testi in immagini dettagliate e a seguire poi MidJourney e Stable Diffusion hanno reso la sintografia sempre più accessibile a tutti, permettendo agli utenti di creare opere visive con semplici prompt testuali.
L’evoluzione in questo settore è poi continuata con DALL-E 2 e 3 che hanno migliorato la qualità del controllo della generazione e oggi il lancio di GPT-4o Image Generation segna un nuovo capitolo.
Integrato in ChatGPT, questo strumento sfrutta un modello auto regressivo per produrre immagini con maggior precisione e realismo incredibili rispetto ai predecessori.
Questa innovazione conferma quindi il ruolo centrale della sintografia nell’AI, ampliando le possibilità creative per professionisti e appassionati.
Ma cerchiamo di capire GPT-40 Image Generation e quali sono i suoi vantaggi più significativi.
Innanzitutto garantisce una maggiore consistenza nella rappresentazione degli oggetti, mantenendo relazioni corrette tra attributi e forme, anche in composizioni complesse.
Inoltre migliora la resa del testo all’interno delle immagini, consentendo la generazione di scritte chiare e leggibili, un aspetto cruciale per applicazioni come poster informativi o fumetti.
La funzione Upload Restyle permette invece agli utenti di caricare immagini esistenti e modificarle secondo nuove indicazioni, facilitando l’adattamento di contenuti visivi preesistenti grazie alla capacità di comprendere poi istruzioni dettagliate.
GPT può generare immagini che rispondono con precisione a richieste specifiche, migliorando l’accuratezza dei risultati.
Infine, la possibilità di creare immagini con sfondi trasparenti agevola l’integrazione di elementi visivi in vari contesti, come loghi e presentazioni, quindi per supporto grafico.
Queste caratteristiche effettivamente rendono ChatGPT-4o strumento potentissimo anche a livello commerciale, molto versatile per la creazione di contenuti visivi.

In questa immagine vediamo le avanzate capacità di generazione fotorealistica di ChatGPT, evidenziando due aspetti tecnicamente complessi: la creazione di testo accurato all’interno delle immagini e la coerenza visiva degli elementi.
Ripeto, non si tratta di due fotografie, ma di due immagini generate a partire da descrizioni testuali.
Incredibile, non trovate? In passato l’integrazione di scritte leggibile nelle immagini era una sfida per i modelli generativi, spesso risultando in caratteri distorti o illeggibili.
Qui invece il testo appare nitido, ben allineato, quindi con chiarezza importante a livello geometrico e contestualmente appropriato, come dimostrano sia la lavagna scritta a mano nella prima immagine, sia il cartello stradale nella seconda.
La fedeltà ai dettagli è un altro punto di forza.
Il riflesso della lavagna di vetro a sinistra mostra una comprensione sofisticata della prospettiva e della luce, mentre le streghe nella seconda immagine sono rappresentate con realismo, mantenendo l’ambientazione urbana coerente.
Inoltre, l’accuratezza semantica, quindi non solo sintattica, del testo dei segnali stradali, dimostra un miglioramento significativo nella generazione di immagini testuali, aspetto quindi fondamentale in sottolineare per applicazioni pratiche come design grafico, creazione di contenuti per l’advertising, ecc.
Con GPT-4o OpenAI quindi, compie un passo in avanti della sintografia, offrendo strumenti più affidabili per la generazione di immagini integrate con testo chiaro e leggibile, aprendo nuove possibilità creative e commerciali.
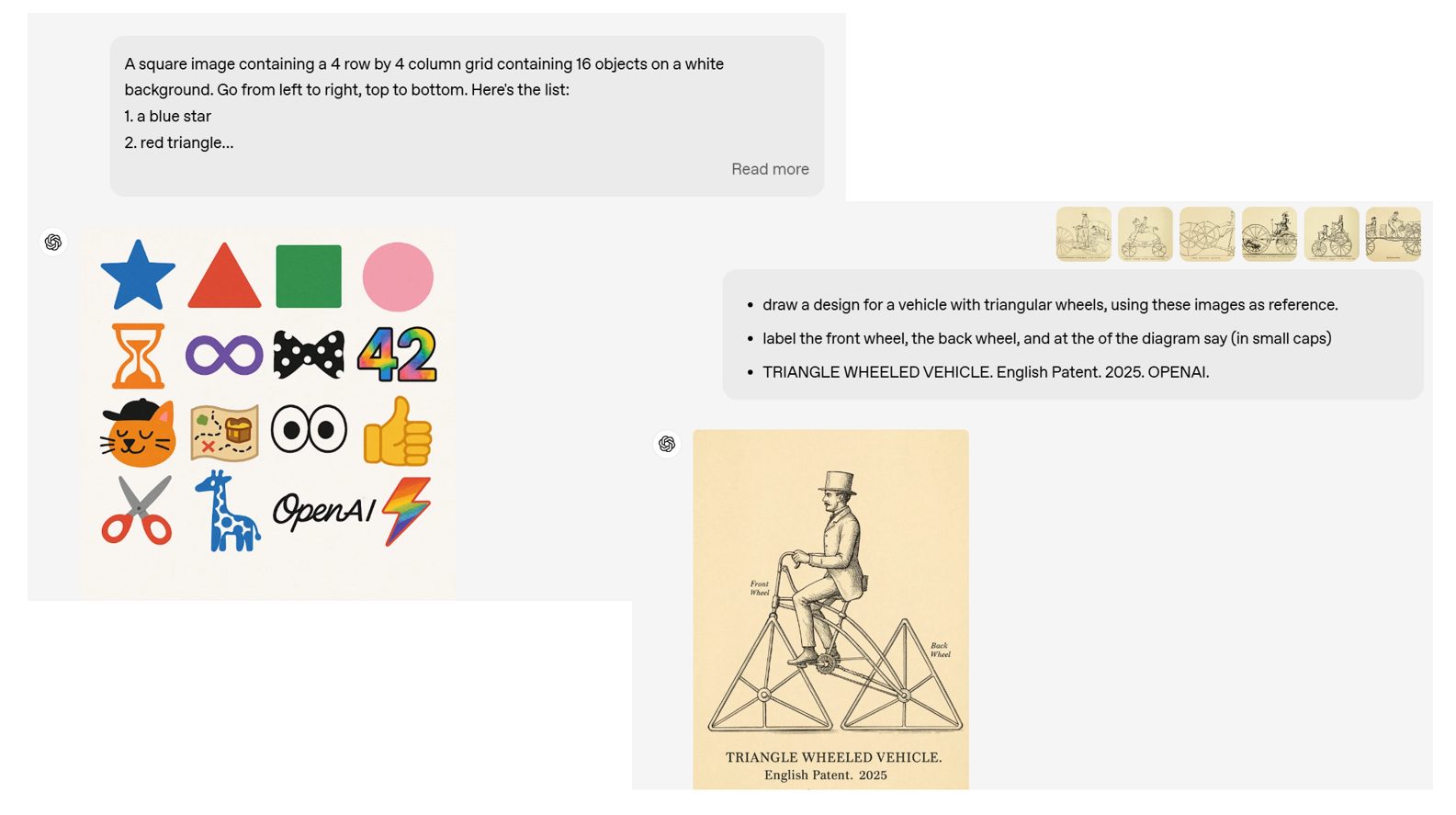
Queste altre due interazioni di esempio con la GPT riassumono invece due importanti funzionalità di GPT-4o per la generazione di immagini.
Innanzitutto dimostra la capacità del modello di comprendere e rendere graficamente composizioni complesse di oggetti.
La griglia di 16 oggetti, che include quindi forme geometriche, emoji e logo di OpenAI, evidenzia come questo strumento possa gestire una varietà di elementi e disporli in modo coerente all’interno di un’immagine.
Questa abilità supera le limitazioni dei modelli precedenti, che faticavano anche a gestire più di cinque oggetti in una singola composizione.
Nella seconda immagine sulla destra, invece, si mostra la capacità di ChatGPT di comprendere il concetto di stile partendo da esempi visuali e mantenere la coerenza del soggetto.
Il disegno in questione mostra un veicolo con ruote triangolari ispirato a immagini di riferimento e dimostra come il modello possa interpretare uno stile visivo e applicarlo a un soggetto diverso.
In sintesi, l’immagine mette in evidenza la versatilità e la potenza di questo strumento nella generazione di immagini, aprendo nuove possibilità per la creazione di contenuti visivi complessi, ma soprattutto stilisticamente coerenti.
E questo spiega anche il numero di immagini importanti che abbiamo visto nel web negli ultimi giorni, con lo stile inconfondibile dello Studio Ghibli di Miyazaki.
Bene, in questa puntata di Le Voci dell’AI abbiamo discusso del recentissimo rilascio di OpenAi GPT-4o Image Generation e di come questa nuova potentissima funzionalità stia facendo impazzire il web nella generazione di immagini, a partire da prompt testuali o altre immagini di riferimento.
Non si tratta di un qualcosa totalmente inaspettato, direi a livello metodologico di prodotto, ma la qualità che questo strumento ha raggiunto è così sorprendente da aver raggiunto forse un punto di svolta fondamentale.
Non si tratta più di strumenti di sinto grafia interessanti, potenziali e legati solo all’intrattenimento.
Si intravede chiaramente l’utilizzo di questi strumenti in chiari ambiti commerciali e produttivi per la grafica, la pubblicità, il giornalismo, il cinema e molto altro.
Si tratta senz’altro di un momento storico rivoluzionario per la comunicazione e l’arte visuale più in generale.
Ciao! Alla prossima puntata di Le Voci dell’AI!