

{kind=link}
Ciao a tutti, sono Vincenzo Lomonaco ricercatore e docente all’Università di Pisa.
Nella puntata di oggi non possiamo non parlare della recente assegnazione del Turing Award del 2024, il premio annuale che rappresenta una sorta di premio Nobel per l’informatica.
Quest’anno il premio è stato assegnato a Andrew Barto e Richard Sutton (da sinistra a destra nella foto) per il loro lavoro pionieristico nell’ambito dell’apprendimento con rinforzo.

Di cosa si tratta e perché questo paradigma di apprendimento automatico si è rilevato particolarmente utile e fondamentale anche per l’intelligenza artificiale moderna? Scopriamolo insieme in questa puntata di Le Voci dell’AI.
Il Premio Turing del 2024 è considerato il massimo riconoscimento nel campo dell’informatica.
È stato recentemente assegnato a Andrew Barto e Richard Sutton, due informatici nordamericani per i loro contributi pioneristici all’apprendimento mediante rinforzo, noto come anche come reinforcement learning, una branca dell’intelligenza artificiale che consente alle macchine di apprendere attraverso l’esperienza diretta con l’ambiente.
Il loro lavoro, iniziato negli anni ‘80, ha gettato le basi per applicazioni avanzate come AlphaGo di Google e ChatGPT di OpenAI, dimostrando l’efficacia di questo paradigma in scenari molto complessi.
Il premio Turing è spesso definito il premio Nobel dell’informatica e assegnato annualmente dalla Association for Computing Machinery – ACM a individui che hanno apportato contributi di eccezionale importanza tecnica e duratura nel campo dell’informatica.
Intitolato ad Alan Turing, pioniere della scienza computazionale dell’informatica, il premio sottolinea l’impatto significativo e duraturo delle scoperte tecnologiche informatiche sulla società.
Dal 2014 il riconoscimento è accompagnato anche da un premio in denaro di 1.000.000 di dollari, sponsorizzato da Google, a testimonianza del valore attribuito a tali contributi.
La ricerca di base è stata inizialmente marginale e ora riconosciuta come fondamentale per lo sviluppo delle IAI moderne.
I due scienziati hanno recentemente spesso preoccupazioni riguardo al rilascio prematuro di modelli di intelligenza artificiale non adeguatamente testati, sottolineando l’importanza di pratiche ingegneristiche responsabili per mitigare i rischi associati allo sviluppo dell’intelligenza artificiale.
Il Premio Turing, infatti, non solo celebra tali innovazioni, ma funge anche da promemoria dell’importanza di sviluppi tecnologici sicuri e responsabili, garantendo che i progressi dell’IA siano implementati con la dovuta cautela per massimizzare i benefici, ma anche ridurre al minimo i rischi potenziali per la società.
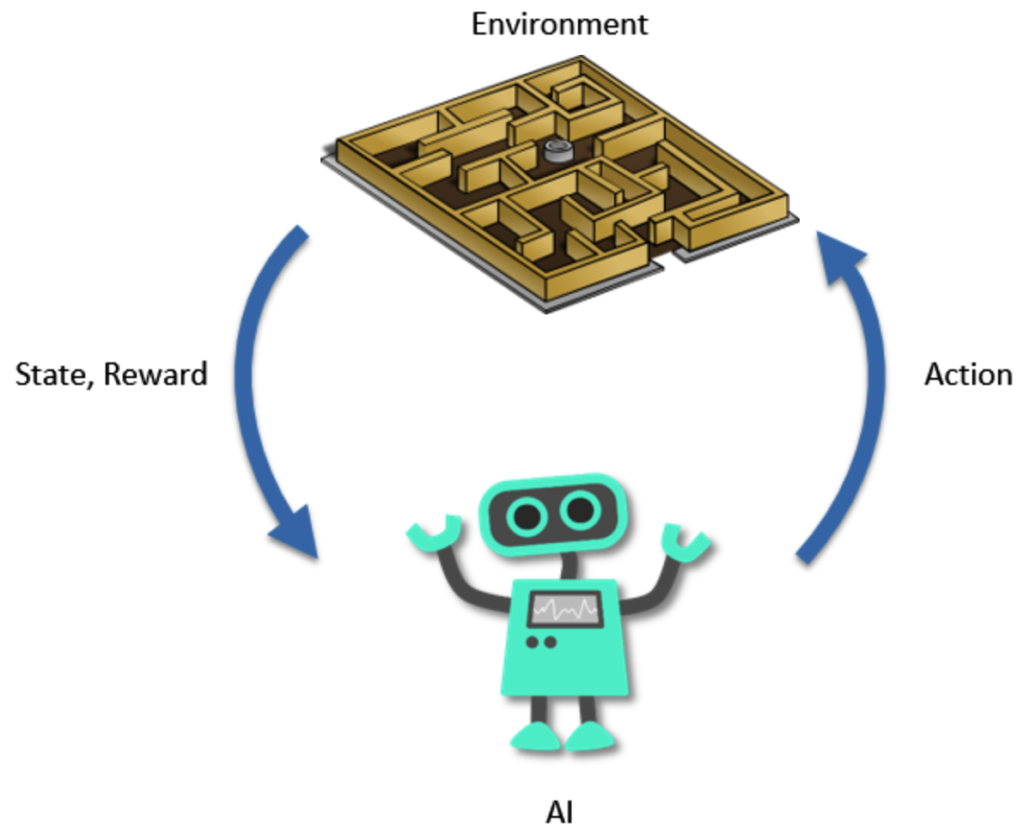
Ma che cos’è l’apprendimento con rinforzo? Il reinforcement learning, come vediamo dall’immagine, è un tipo di intelligenza artificiale in cui un agente, che può essere o un programma o un sistema, impara a prendere decisioni provando diverse azioni e ricevendo ricompense o penalità in base ai risultati ottenuti.
Il concetto si ispira al modo in cui impariamo noi umani dagli errori e dai successi nella vita quotidiana.
Se un’azione porta a un buon risultato, è più probabile che venga ripetuta in futuro. Se invece porta a un risultato negativo, è meglio evitarla.
L’agente quindi esplora il suo ambiente e sceglie le azioni da compiere per raggiungere un obiettivo, basandosi sulle esperienze passate.
Per migliorare deve anche trovare una sorta di equilibrio tra provare nuove strategie e sfruttare quelle già note che funzionano meglio.
Tra i metodi più usati nel reinforcement learning, uno dei più semplici e noti è il Q-learning, che insegna all’agente a capire quali azioni nel presente potrebbero portare a migliori ricompense nel futuro.
Una versione più avanzata, chiamata Deep Q- Networks, DQN, utilizza reti neurali artificiali per affrontare problemi ancor più complessi.
E sulla base di questi metodi più tradizionali, una serie di varianti via via più sofisticate sono state create negli ultimi anni, rendendo questo approccio molto utile e robusto, a prescindere dal campo applicativo.
L’apprendimento con rinforzo è usato infatti in maniera pratica in molti campi.
Nei videogiochi, per esempio, dove l’intelligenza artificiale impara a giocare da sola, nei robot che apprendono movimenti precisi per raggiungere obiettivi strategici e produttivi, nelle auto a guida autonoma che imparano a reagire alle dinamiche del traffico e persino della finanza per sviluppare strategie di investimento intelligenti.
Questo metodo è così potente perché permette ai sistemi di imparare in autonomia, migliorando continuamente le loro capacità, senza bisogno di istruzioni dettagliate da parte di programmatori o esperti di dominio.
L’apprendimento con rinforzi ha avuto grandi successi, soprattutto negli ultimi anni, grazie all’uso combinato con modelli avanzati di AI, i Large Language Models, di cui parliamo spesso in questa rubrica.
Inizialmente il RL veniva applicato partendo da zero, senza conoscenze pregresse, e richiedeva milioni di tentativi per imparare, rendendolo poco pratico.
Oggi invece viene usato solamente per raffinare e specializzare modelli già addestrati, rendendolo estremamente efficace.
Un esempio è ChatGPT, che utilizza il reinforced learning per migliorare il question answering, le risposte che dà in funzione di una domanda esplicita.
Grazie al Reinforced Learning from Human Feedback di cui abbiamo parlato nell’episodio 74 di Le Voci dell’AI, il modello viene affinato in base alle preferenze degli utenti, generando risposte più pertinenti e sicure.
Un altro progresso fondamentale è l’uso del RL per insegnare ai modelli a ragionare per passaggi intermedi, come nel caso di DeepSeek-R1. Qui l’RL aiuta l’AI a non limitarsi a risposte immediate, ma a scomporre problemi complessi in passaggi più semplici e logici, migliorando quindi la capacità di ragionamento.
Questi avanzamenti rendono quindi l’RL uno strumento chiave per sviluppare chatbot, agenti più intelligenti e affidabili, capaci non solo di rispondere con precisione, ma anche di seguire un processo di pensiero più simile e spiegabile come quello umano.
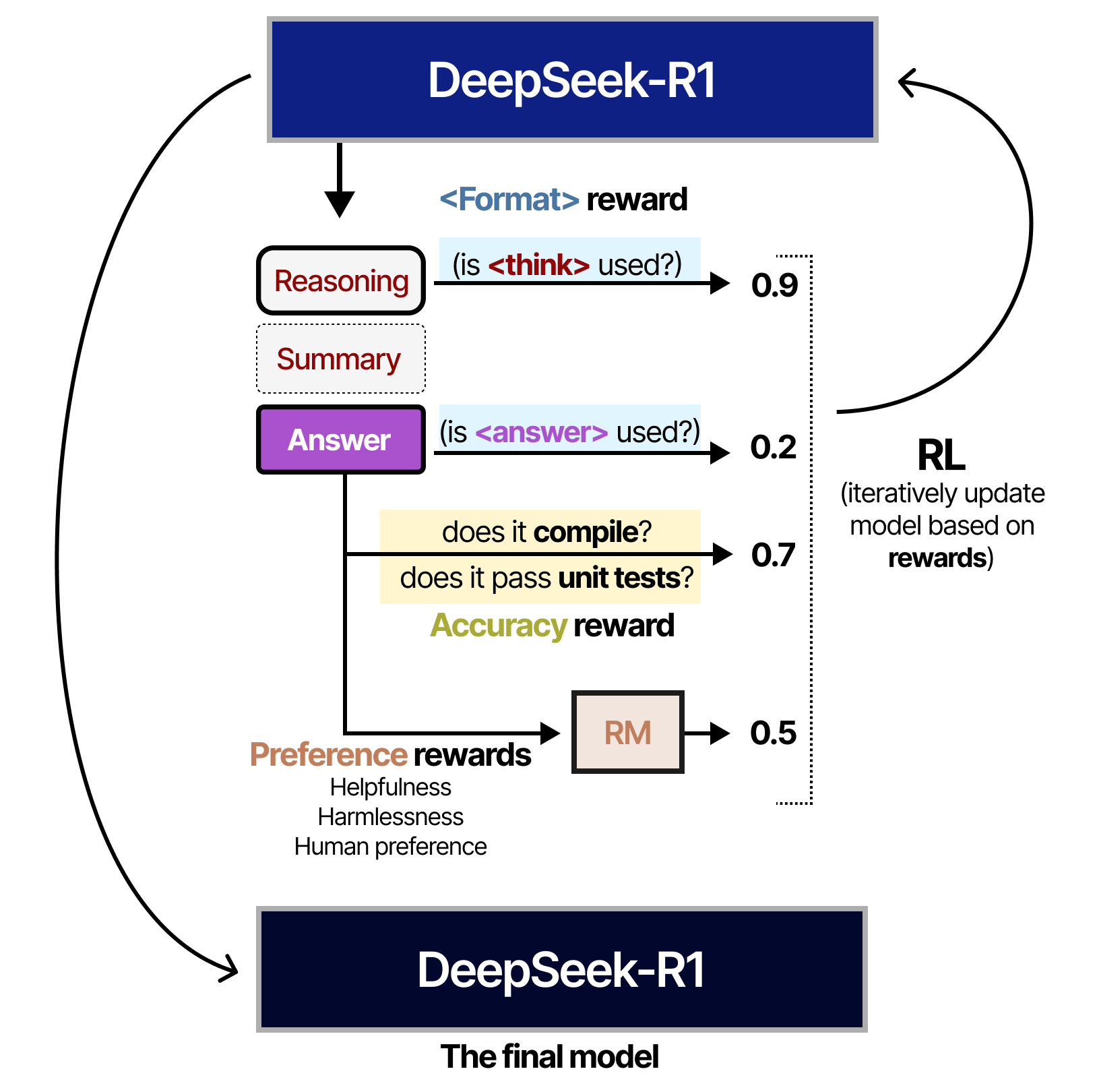
In questa immagine vediamo come il reinforced learning sia utilizzato per la creazione di un modello open source, DeepSeek-R1. Qui il RL viene utilizzato esplicitamente per migliorare le capacità del modello di ragionare in modo strutturato grazie a una funzione di ricompensa ben definita.
In particolare, l’addestramento premia il modello in base a criteri chiari e misurabili della qualità delle sue risposte.
Per esempio, viene assegnata una ricompensa elevata a 0.9 se il modello utilizza esplicitamente un passaggio di ragionamento e incentiva la suddivisione dei problemi in step logici.
Inoltre, viene attribuito un punteggio minore, 0.2, se il modello fornisce direttamente una risposta esaustiva senza passaggi intermedi.
Nel contesto della programmazione di questo esempio specifico, la funzione di ricompensa può essere arricchita ulteriormente perché esistono metriche oggettive per valutare le risposte.
Se il codice generato, per esempio, si compila, è traducibile in linguaggio macchina e supera dei test di efficacia, il modello viene premiato ulteriormente con 0.7.
Infine, viene applicata una ricompensa basata sulle preferenze umane, laddove disponibili, che tiene conto di fattori come utilità, sicurezza e preferenze dell’utente.
Questa struttura di ricompensa chiara e misurabile il motivo per cui il rinforzo è particolarmente utile in ambiti strutturati come la programmazione, dove può guidare il modello a ragionare meglio e produrre risultati più affidabili attraverso un miglioramento iterativo.
Bene, in questa puntata abbiamo discusso del paradigma dell’apprendimento con rinforzo e di come esso si sia affermato come una metodologia fondamentale per lo sviluppo di soluzioni di intelligenza artificiale allo stato dell’arte, come ChatGPT.
In particolare abbiamo evidenziato due importantissimi utilizzi di queste tecniche nel contesto di modelli fondazionali genetici il raffinamento dei comportamenti e risposte a seguito di feedback umani e il miglioramento dei processi di ragionamento.
In futuro ci aspettiamo un uso ancor più consistente dell’apprendimento con rinforzo per magari meglio guidare l’utilizzo di collettivi, di modelli, di agenti per la risoluzione di compiti complessi dove un solo modello non potrebbe fornire risposte sufficientemente adeguate.
Ciao! Alla prossima puntata di Le Voci dell’AI!