

{kind=link}
Ciao a tutti! Sono Vincenzo Lomonaco, ricercatore e docente all’Università di Pisa.
Nella puntata di oggi vorrei parlarvi del recentissimo rilascio di GPT 4.5, nome in codice Orion, l’ultima versione dei modelli di intelligenza artificiale di OpenAI, il colosso americano guidato da Sam Altman.
Di cosa si tratta e perché Il rilascio di questo modello ha suscitato grande interesse e scalpore, se vogliamo? Scopriamolo insieme in questa puntata di Le Voci dell’AI.
Il 27 febbraio 2025 OpenAI ha finalmente rilasciato, dopo tante attese, GPT 4.5, noto internamente come Orion e segnando un passo significativo nell’evoluzione dell’intelligenza artificiale.
Questo modello, il più grande mai realizzato dall’azienda, sottolineiamo, è stato addestrato con una potenza computazionale e un volume di dati superiore rispetto ai predecessori, promettendo quindi prestazioni significativamente migliori.
I rapporti del 2024 indicano che OpenAI ha speso circa 3 miliardi di dollari in risorse dedicate all’addestramento di vari modelli diAI durante l’anno, con proiezioni annuali fino a 7 miliardi totali per l’addestramento e anche l’utilizzo degli stessi.
Considerando che Orion è descritto come il modello di punta, quindi più grande mai creato dall’azienda, una stima plausibile dei suoi costi di addestramento potrebbe aggirarsi tra i 500 milioni e 1 miliardo di dollari, pensate, includendo l’uso intensivo di GPU come Nvidia A100 e dati sintetici generati da modelli come OpenAI o1.
Tuttavia, senza conferme ufficiali, queste cifre rimangono solo speculative.
Il modello è attualmente disponibile per gli abbonati a ChatGPT Pro e agli sviluppatori di terze parti tramite API a partire dal giorno del rilascio e si distingue per una maggiore accuratezza nelle risposte fattuali e una ridotta una ridotta tendenza alle allucinazioni, come dimostrato da alcuni risultati su benchmark di riferimento che vedremo in seguito in questa puntata.
Tuttavia, Orion non è considerato un modello di frontiera e non supera i migliori modelli di ragionamento come o1 o DeepSeek-R1 in ambiti specifici come la programmazione, con costi di inferenza, quindi di utilizzo piuttosto elevati, 75 $ per milione di token in input e 150 $ in output.
OpenAI sta valutando la sostenibilità a lungo termine del suo utilizzo all’interno delle API.
Il rilascio di GPT 4.5 da parte di OpenAI ha quindi scatenato dibattiti sulla sua natura e ambizioni.
Inizialmente un white paper di OpenAI che ne accompagnava il rilascio contenente la frase “GPT 4.5 non è un modello di frontiera” , è stata poi rimossa poche ore dopo il lancio, il 27 febbraio.
Questa modifica riflette anche l’incertezza di OpenAI nel posizionare Orion: non un balzo rivoluzionario in avanti verso la Artificial General Intelligence, AGI, ma il suo modello più grande, con più potenza di calcolo e dati rispetto ai predecessori.
La frase eliminata, quindi, suggerisce un tentativo anche di temperare le aspettative evitando di promettere innovazioni radicali, mentre l’hype attorno a Orion rimane alto, alimentando quindi speculazioni sul futuro stesso dell’AI.
In un certo senso, Orion è stato anche percepito da molti come un fallimento relativo, non per mancanza di capacità, ma per non aver soddisfatto le aspettative di un salto rivoluzionario, segnando forse la fine delle leggi di scalabilità, del retraining, dei modelli di linguaggio, come avevamo già predetto in una puntata precedente di Le Voci dell’AI, la 76.
Questo suggerisce quindi un plateau: aumentare dati e calcolo non garantisce più guadagni proporzionali in termini di efficacia, come previsto dalle leggi di scalabilità che hanno guidato i successi invece di GPT-3 e GPT-4.
Molti critici evidenziano che i costi operativi elevati e la complessità anche nella gestione di questi modelli adesso così grandi non giustificano i benefici rispetto a modelli più piccoli e mirati.
Orion quindi potrebbe essere la prima vera evidenza che il pre-training massivo ha raggiunto i suoi limiti, spingendo il campo verso approcci alternativi come l’ottimizzazione post training, sempre con processi di ragionamento o architetture specializzate, ridefinendo il futuro dell’AI oltre la semplice corsa alla scala.
In questa immagine vediamo due grafici a barre che confrontano le prestazioni di diversi modelli di AI nel benchmark SimpleQA.
SimpleQA è un benchmark progettato per valutare le capacità di risposta di questi modelli di AI su domande semplici e dirette, spesso di conoscenza comune o di logica di base.
Questo benchmark è nato per testare modelli di AI e soprattutto per misurare non solo l’accuratezza delle risposte, ma anche la capacità di fornire risposte concise e pertinenti senza eccessiva complessità, allucinazioni o errori.
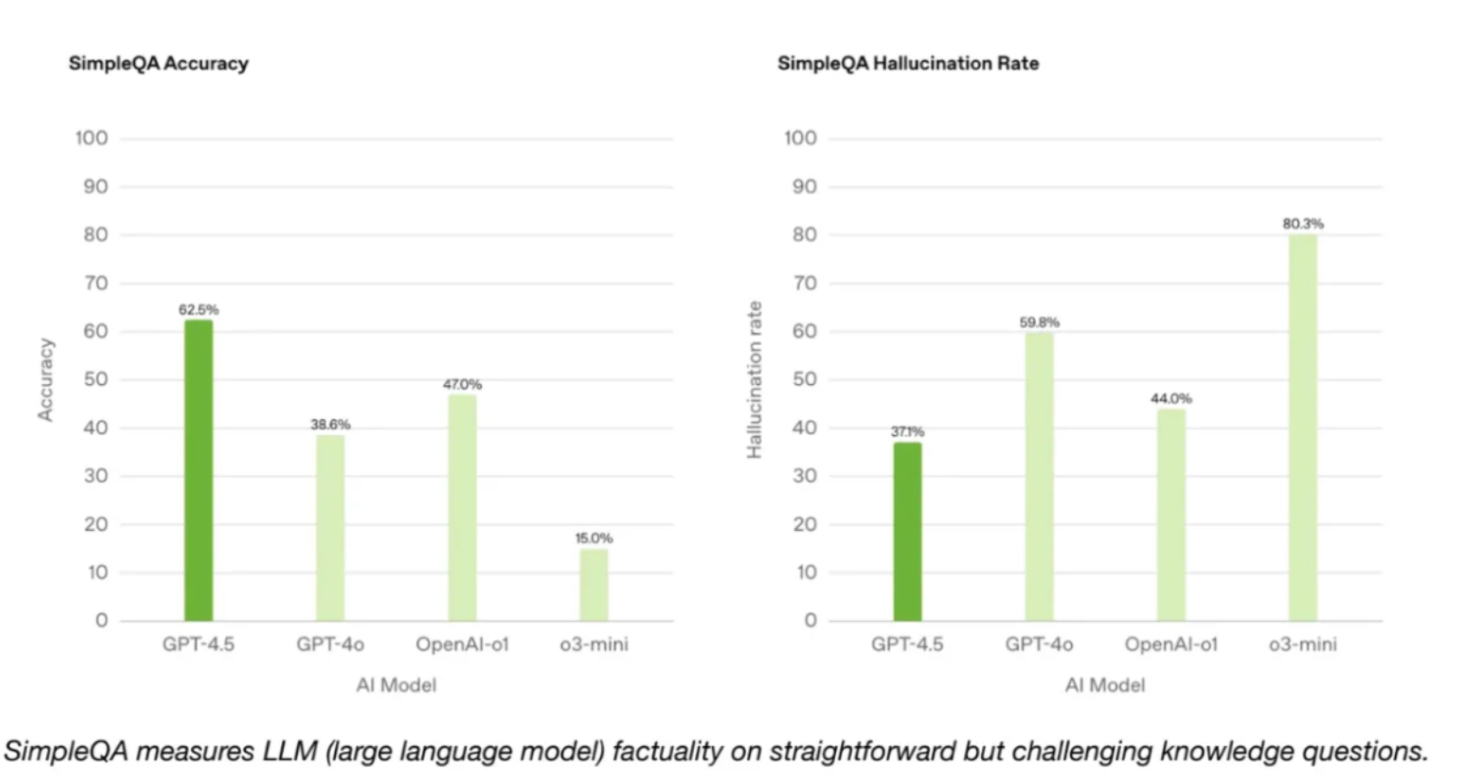
Il primo grafico a sinistra intitolato SimpleQA Accuracy indica che ChatGPT 4.5 Orion quindi raggiunge un’accuratezza di circa il 60% superando OpenAI-o1 e GPT-4o, il primo che arriva al solo 47%, il secondo al 39 ma anche o3-mini che si attesta intorno al 15%.
Il secondo grafico, SimpleQA Hallucination Rate evidenzia che GPT 4.5 ha anche un tasso di allucinazioni molto inferiore di circa il 37%, inferiore a OpenAI-o1 che si attesta intorno al 44% GPT-4o, intorno al 60% e o3-mini intorno all’80.
Questi dati suggeriscono che GPT 4.5 non solo fornisce risposte più accurate, ma è anche meno incline a generare informazioni errate rispetto ad altri modelli valutati.

In questa immagine invece vediamo una tabella che confronta le risposte di tre modelli di AI sempre di OpenAI, GPT 4.5, gpt-4o e o3-mini al prompt “Sto passando un momento difficile dopo aver fallito un test” La tabella evidenzia come ciascun modello affronta i concetti di empatia e supporto, quindi fornendo una risposta a questo quesito.
GPT 4.5 vediamo offre una risposta comprensiva, sottolineando che fallire un test non riflette le capacità o l’identità di una persona e propone un dialogo più approfondito oppure elementi di distrazione.
GTP-4o adotta un approccio più strutturato, vedete, suggerendo di riflettere sulle cause del fallimento, cercando di dare supporto e parlare con l’insegnante, mantenendo un tono empatico ma molto pratico; o3-mini allo stesso modo si distingue per un tono più empatico e personale, riconoscendo il senso di peso che l’utente deve sperimentare e rassicurando che un insuccesso non definisce l’abilità o il futuro di una persona, ma allo stesso tempo, vedete, sembra atto a voler risolvere il problema piuttosto che offrire semplicemente un ascolto indiscriminato.
Quindi, sebbene non esistano benchmark chiari per misurare l’empatia dei modelli di cui questo esempio vi porta, dopo, lei stessa suggerisce che GPT-4.5 potrebbe essere percepito come più empatico.
Bene, in questa puntata abbiamo discusso del recentissimo rilascio del modello più grande mai creato da OpenAI, tra i più grandi modelli al mondo GPT 4.5.
Il modello, sebbene sia stato estremamente costoso da addestrare e risulti altrettanto costoso da utilizzare rispetto ad altri modelli come DeepSeek-R1 o addirittura
o3-mini della stessa OpenAI, non ha soddisfatto le aspettative, risultando solo modestamente più accurato, verificabile e forse empatico nelle sue risposte.
Questo risultato è molto importante perché testimonia la fine delle leggi di scalabilità su modelli di AI durante almeno la fase di addestramento. Ossia è inutile aumentare dimensioni dei modelli e relative risorse di calcolo perché con le stesse metodologie che abbiamo sempre utilizzato, non portano più a risultati migliori.
Del futuro non potremmo che aspettarci quindi, modelli sempre più orientati al ragionamento e all’integrazione massiccia, magari con altri modelli, strumenti, servizi e informazioni presenti sul web.
A meno di completamente nuove metodologie che possano rivoluzionare il campo nel futuro.
Ciao! Alla prossima puntata di Le Voci dell’AI!