

{kind=link}
Ciao a tutti, sono Vincenzo Lomonaco, ricercatore e docente all’Università di Pisa.
Nella puntata di oggi torniamo a parlare di Apprendimento Automatico Continuo o Continual Learning e di come questo paradigma si stia evolvendo a pari passo con l’avanzata dei Large Language Models e dei modelli fondazionali.
Qual è il futuro di questo paradigma? Ha ancora senso oggi, con la presenza di modelli addestrati, sempre più capaci e con accesso dinamico al web? Quali sono le direzioni di ricerca più promettenti per il presente e il futuro di questa disciplina?
Scopriamolo insieme in questa puntata di Le Voci dell’AI.
L’apprendimento automatico continuo o Continual Learning, come abbiamo già introdotto nella puntata 47 di Le Voci dell’AI, è un paradigma di intelligenza artificiale del machine learning che mira a sviluppare modelli capaci di apprendere continuamente nel tempo, incorporando nuove informazioni e capacità, senza dimenticare quelle apprese in precedenza.
Questo approccio si distingue dal tradizionale schema di apprendimento statico, in cui un modello viene addestrato una sola volta su un insieme di dati prestabilito.
Il tema del Continual Learning è da sempre centrale nel dibattito dell’AI, soprattutto per la sua vicinanza alle capacità cognitive umane, che permettono ovviamente di apprendere in modo progressivo e adattivo.
Tuttavia, per anni è rimasto un ambito, direi, di nicchia della ricerca, ostacolato da limiti computazionali e dall’assenza di framework specifici e più pratici.
Con l’esplosione del deep learning, però, il Continual Learning ha riacceso l’interesse della comunità di AI mainstream grazie alla possibilità di combinare l’efficienza delle reti neurali profonde con tecniche di apprendimento incrementale.
Le sfide principali del Continual Learning rimangono il Catastrophic Forgetting, ossia la perdita catastrofica di conoscenze precedenti apprese durante il processamento di dati incontrati nel passato, l’ottimizzazione delle risorse e la gestione della distribuzione di dati non stazionaria.
Oggi il Continual Learning è visto come un passo cruciale verso sistemi di AI più autonomi, adattabili e capaci di operare in ambienti dinamici reali.
Il Continual Learning, inteso quindi come la capacità di acquisire, mantenere e aggiornare conoscenze nel tempo, è stato quindi a lungo riconosciuto come un pilastro dell’intelligenza artificiale e naturale.
Tuttavia, con l’ascesa dei Large Language Models e dei Foundation Models, capaci di affrontare una vasta gamma di compiti grazie a un pre-addestramento su dati di scala globale, molti si chiedono se il Continual Learning sia ancora realmente necessario.
In particolare, si è diffusa l’idea che, poiché questi modelli possono accedere a conoscenze esterne continuamente aggiornate tramite il web, sia sufficiente vederli come interfacce statiche su un sapere dinamico esterno, curato e mantenuto dagli esseri umani.
In questa prospettiva l’evoluzione non avviene all’interno del modello, ma nell’ambiente informativo che lo circonda, riducendo l’urgenza di sviluppare modelli capaci di apprendere in modo autonomo e incrementale.
Inoltre, l’apparente versatilità e generalità dei Large Language Model centralizzati sembra rendere superfluo un apprendimento continuo, specialmente quando nuovi compiti possono essere gestiti tramite prompt con contesti molto grandi.
Tuttavia, questa visione trascura i limiti intrinseci di modelli statici di grande scala, come l’obsolescenza della conoscenza, l’inefficacia, l’inefficienza, nell’adattamento personalizzato e l’incapacità di riorganizzarsi dinamicamente.
Aspetti per cui il Continual Learning, ma non solo, rilevano tema cruciale.
Ad esempio, anche se oggi molti Large Language Models possono accedere autonomamente a Internet per recuperare informazioni aggiornate, questa capacità non equivale, badate bene, a un reale apprendimento continuo.
Prendiamo il caso di un nuovo farmaco approvato nel 2024 per il trattamento del diabete.
Un Large Language Model potrebbe trovare senz’altro la notizia online e riportarne i dettagli su richiesta, ma non integrerebbe stabilmente quella conoscenza nella propria rappresentazione interna.
Ogni volta, quindi che l’informazione necessaria dovrebbe essere riscoperta da zero.
Ecco, questo approccio, basato su un accesso esterno e momentaneo al sapere, è piuttosto fragile rispetto a scenari che richiedono generalizzazione, ragionamento multipassaggio, uso ripetuto delle stesse nozioni in contesti diversi.
Un modello continuamente addestrato, invece, interiorizza e struttura i nuovi dati, rendendoli parte del proprio sapere permanente e questo lo rende molto più efficiente, affidabile e contestualmente coerente, senza dipendere da ricerche estemporanee o dalla disponibilità di fonti online in tempo reale.
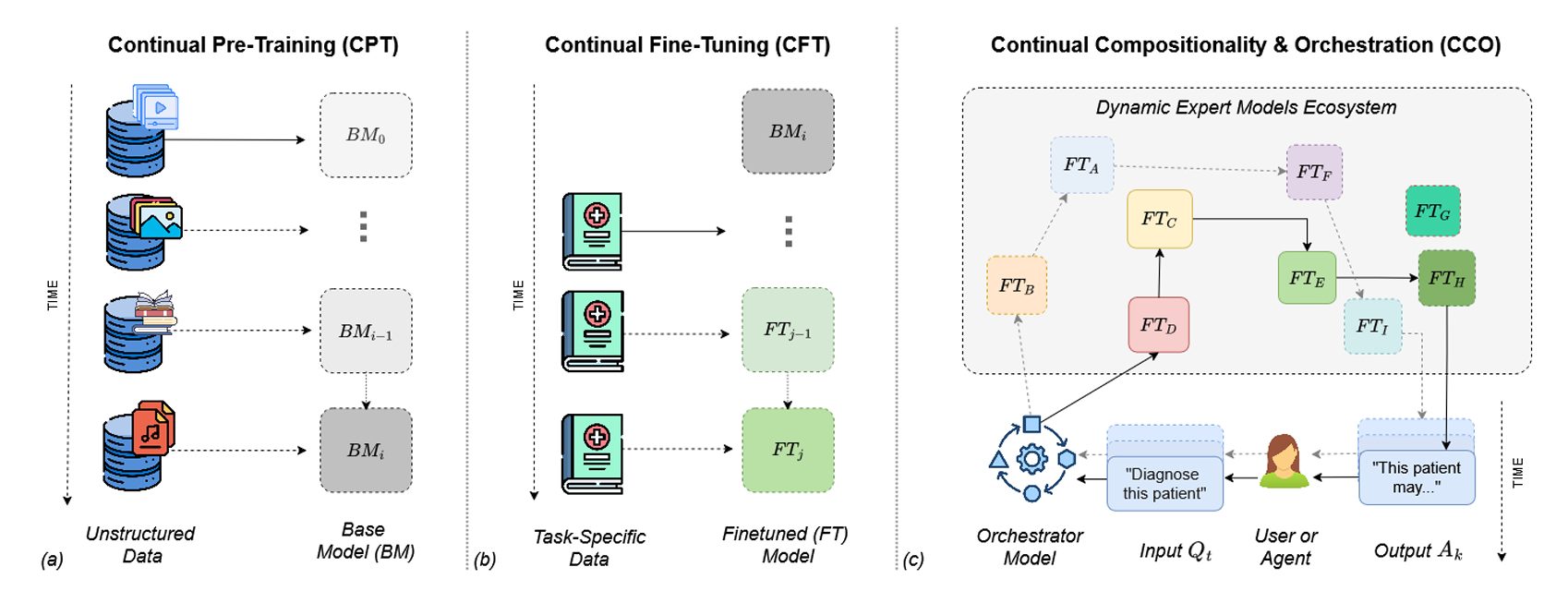
In questa immagine vediamo illustrato in modo sintetico e visuale tre direzioni di ricerca fondamentali per il futuro del Continual Learning nel contesto dell’AI contemporanea, il Continual Pre-Training (CPT), il Continual Fine Tuning (CFT) e la Continual Compositionality & Orchestration (CCO).
Nella prima sezione (a) a sinistra, il CPT – Continual Pre-Training mostra come un modello di base evidenziato con le lettere BM venga progressivamente aggiornato attraverso l’ingestione continua di dati non strutturati provenienti da fonti eterogenee, quindi testi, immagini, audio, video.
Questo processo, che evolve nel tempo, quindi da BM0 a BMi, è essenziale per mitigare la stasi delle conoscenze e adattare, migliorare il modello fondazionale continuamente e incrementalmente.
La sezione (b), al centro, invece rappresenta il Continual Fine Tuning, dove modelli pre-addestrati, costruiti anche nello step precedente, vengono specializzati, raffinati su un insieme di dati specifici di dominio, ad esempio l’ambito medico, per generare versioni continuamente ottimizzate, FTj senza dover riaggiustare completamente il modello di partenza.
Questa strategia permette ovviamente di personalizzare e adattare in maniera efficiente le nostre soluzioni di AI, mantenendo la memoria delle esperienze precedenti.
Infine, nella sezione (c), a destra vediamo rappresentato il paradigma, direi molto più attuale emergente del CCO, in cui un ecosistema dinamico di modelli esperti FTA, FTB… FTH, è orchestrato da un modello centrale in grado di comporre e ricombinare moduli diversi in funzione di richieste specifiche.
In questo scenario, per esempio, l’utente o un agente pone una domanda: “diagnostica questo paziente” e l’orchestratore seleziona, in funzione di questa richiesta i modelli più rilevanti per generare una risposta coerente e contestualizzata.
Questo approccio, quindi, riflette una visione dell’AI non più basata su un singolo modello monolitico, ma su una rete modulare adattabile di componenti specializzati che evolvono nel tempo.
Mentre i Large Language Model tradizionali sembrano offrire risposte generaliste, attingendo quindi a conoscenze statiche, la Continual Compositionality & Orchestration propone un’architettura scalabile e composizionale in grado di affrontare compiti complessi e molto dinamici, migliorando quindi progressivamente le prestazioni attraverso interazioni e utilizzo flessibile delle competenze.
In sintesi, l’immagine sostiene l’idea che il Continual Learning non solo rimane rilevante nell’era dei Foundation Models, ma rappresenta una direzione cruciale per lo sviluppo di sistemi intelligenti capaci di apprendere costantemente, adattandosi in modo efficiente e capace di collaborare in ecosistemi cognitivi decentralizzati.
Bene, in questa puntata abbiamo discusso di apprendimento automatico continuo, un paradigma di machine learning che mette al centro la sostenibilità dell’intero ciclo di vita, delle soluzioni AI, ma anche la capacità di adattarsi e personalizzarli tempestivamente in funzione delle esigenze.
In particolare ho discusso di tre direzioni di ricerca in cui io credo che Continual Learning possa davvero avere un impatto significativo nel presente e nel prossimo futuro.
L’aggiornamento di modelli fondazionali di grandi dimensioni, il raffinamento e personalizzazione di soluzioni di AI, il continuo coordinamento ed orchestrazione di soluzioni decentralizzate e multi agente.
Ecco, in questo soprattutto, che rappresenta lo scenario più dinamico e interessante, credo che il Continual Learning dimostrerà i suoi vantaggi più significativi.
Ciao! Alla prossima puntata di Le Voci dell’AI!