

{kind=link}
Ciao a tutti, sono Vincenzo Lomonaco, ricercatore e docente all’Università di Pisa.
Nella puntata di oggi parliamo di un modello open source di punta appena rilasciato da Mistral AI, parliamo di Voxtral, indiscutibilmente il miglior modello di riconoscimento vocale open source, con un ottimo compromesso tra efficienza, prezzo ed efficacia.
Si tratta davvero di un passo in avanti nell’interazione vocale con i nostri assistenti intelligenti? Voxtral rappresenta davvero un modello competitivo di matrice europea che sfida i modelli chiusi di OpenAI e altri colossi americani e cinesi? Scopriamolo insieme in questa puntata di Le Voci dell’AI.
Il 15 luglio 2025 Mistral ha annunciato il rilascio di Voxtral, una nuova famiglia di modelli open source per la comprensione vocale.
Dispone in due varianti Voxtral Small, con 24 miliardi di parametri, pensata per applicazioni cloud e per supportare servizi produttivi e Voxtral Mini, con 3 miliardi di parametri, adatta all’uso locale su dispositivi integrati.
Entrambe le versioni sono distribuite sotto la licenza molto permissiva Apache 2 e accessibili anche tramite Api Mistral con un endpoint ottimizzato per la trascrizione Voxtral Mini Transcribe, che offre costi di gran lunga inferiori rispetto a molte altre soluzioni commerciali concorrenti.
Ciò che distingue Voxtral è la sua capacità di gestire contesti molto lunghi.
Pensate che può elaborare fino a 32.000 token, quindi circa 30 minuti di audio per la trascrizione, anche 40 minuti per l’analisi semantica.
E inoltre, grazie all’integrazione di una backbone basata su Mistral Small 3.1, il Large Language Model di Mistral, Voxtral supporta nativamente domande e risposte, riepiloghi semantici direttamente a partire dall’audio. Ecco, Voxtral è quindi un modello nativamente multilingua, con prestazioni di alto livello in inglese, francese, spagnolo, portoghese, tedesco, italiano, eccetera, tra le lingue più ampiamente utilizzate. I risultati sui benchmark di riferimento dimostrano che Voxtral Small supera l’accuratezza di modelli open source come Whisper Large versione 3 di OpenAI e si confronta favorevolmente con modelli proprietari come GPT 4 mini, Gemini 2.5 Flash, Elevenlabs Scribe, offrendo risultati eccellenti a meno della metà del prezzo.
Infine, Voxtral abilita La funzione function calling da voce, consentendo di attivare comandi vocali flussi o chiamate API direttamente da input vocale.
Questo rende Voxtral un sistema aperto, flessibile, molto potente per la trascrizione, la comprensione avanzata e attivazione di azioni vocali in ambienti reali, quindi ideale come interfaccia per i nostri assistenti virtuali.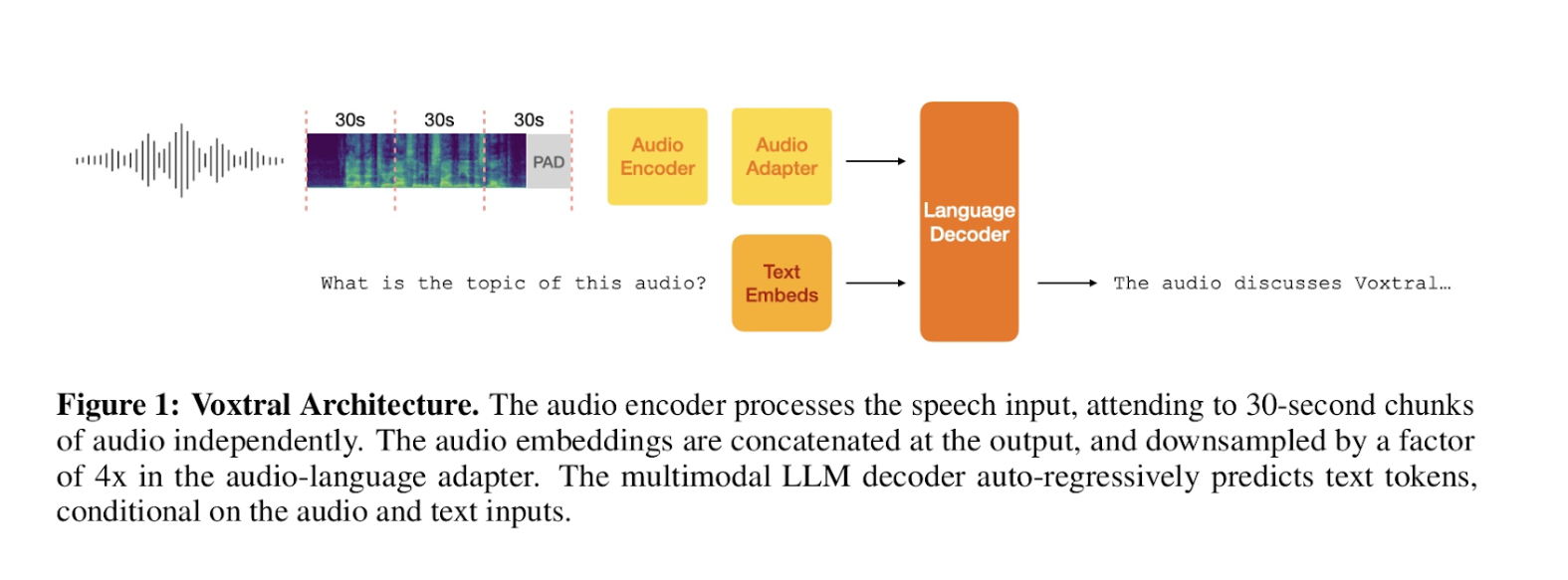
In questa immagine vediamo l’architettura Voxtral ad alto livello.
Si tratta di un sistema multimodale, altamente modulare e flessibile, capace di gestire sia la trascrizione vocale che la comprensione del genere testuale tramite interfaccia vocale.
Il processo inizia con l’input audio suddiviso in chunk, quindi pezzetti indipendenti di 30 secondi.
Ogni chunk è elaborato da un audio encoder, le cui uscite sono poi concatenate e ridotte di quattro volte in termini di dimensioni da un audio adapter, convertendo l’acustica in embedding compatti.
Parallelamente, l’input testuale è trasformato in embedding testuali e il cuore del sistema è il language decoder, un modello a tutti gli effetti multimodale, che riceve sia gli embedding audio sia quelli testuali.
Questa architettura combinata permette a Voxtral di eccellere nella generazione di trascrizioni vocali, decodificando l’audio in testo e nella comprensione testuale con l’interfaccia vocale, quindi interpretando domande audio testuali per generare risposte coerenti.
La sua modularità risiede nei componenti indipendenti, quindi encoder, adapter ed embeds, che alimentano il decoder centrale consentendo aggiornamenti mirati.
La flessibilità è evidente nella capacità del decoder di condizionare l’output, cioè il testo generato su input sia audio che testuali, rendendo quindi Voxtral adattabile a scenari puramente vocali, puramente testuali o multimediali complessi.
L’adapter è poi essenziale per aumentare le dimensioni del contesto considerato, preservandone la ricchezza informativa.
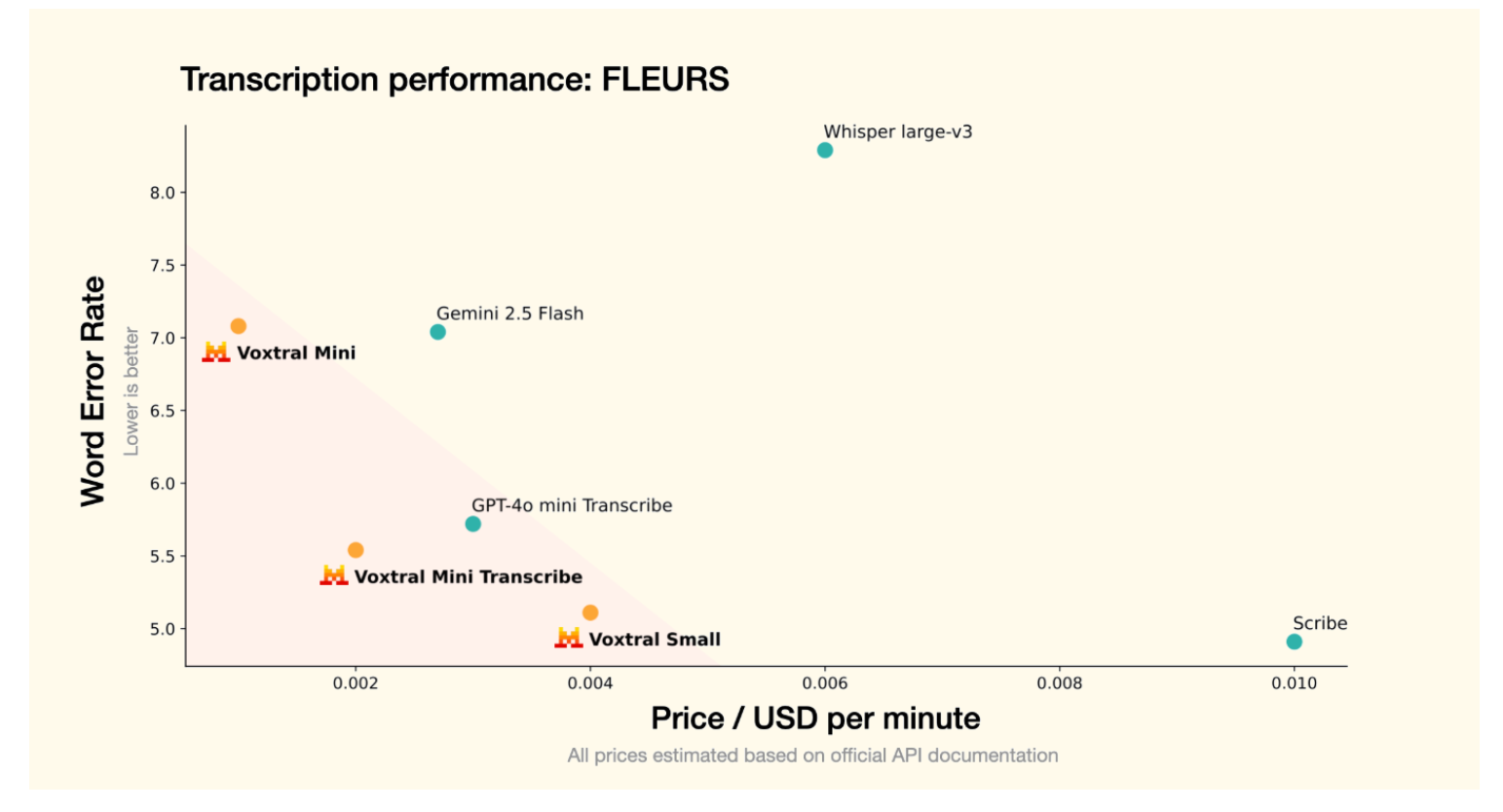
In questo grafico, invece, vediamo una comparazione tra diversi modelli di trascrizione vocale, valutandone l’accuratezza con il numero di parole sbagliate sull’asse delle Y, dove un valore inferiore è ovviamente migliore e il costo per minuto prezzo in dollari per minuto sull’asse delle X.
Anche in questo caso, meno spendiamo e meglio è.
L’area rosa in basso a sinistra indica la zona preferibile con errore basso e costo contenuto.
Nel grafico Voxtral Mini mostra un errore di circa il 7% e un costo inferiore a 0,002 $ al minuto.
I modelli Voxtral mini Transcribe e Voxtral small evidenziano prestazioni anche superiori, entrambi con un errore sotto il 5,5% e costi abbastanza competitivi.
In particolare Voxtral small si distingue con l’errore più basso tra tutti i modelli presentati qui, attestandosi intorno al 5%, con un costo di circa zero zero zero 4$ al minuto.0,004 $ In confronto, Gemini 2.5 Flash e GPT-4o mini e Transcribe presentano un Word Error Rate leggermente superiore rispetto ai modelli Voxtral composti intermedi, mentre Whisper Large versione 3 di OpenAI e mai si posiziona con un WER elevato oltre l’8% e un costo relativamente alto.
Infine, Scribd mostra un errore molto basso, certamente, ma è il più costoso di tutti, superando 0,01 $ al minuto.
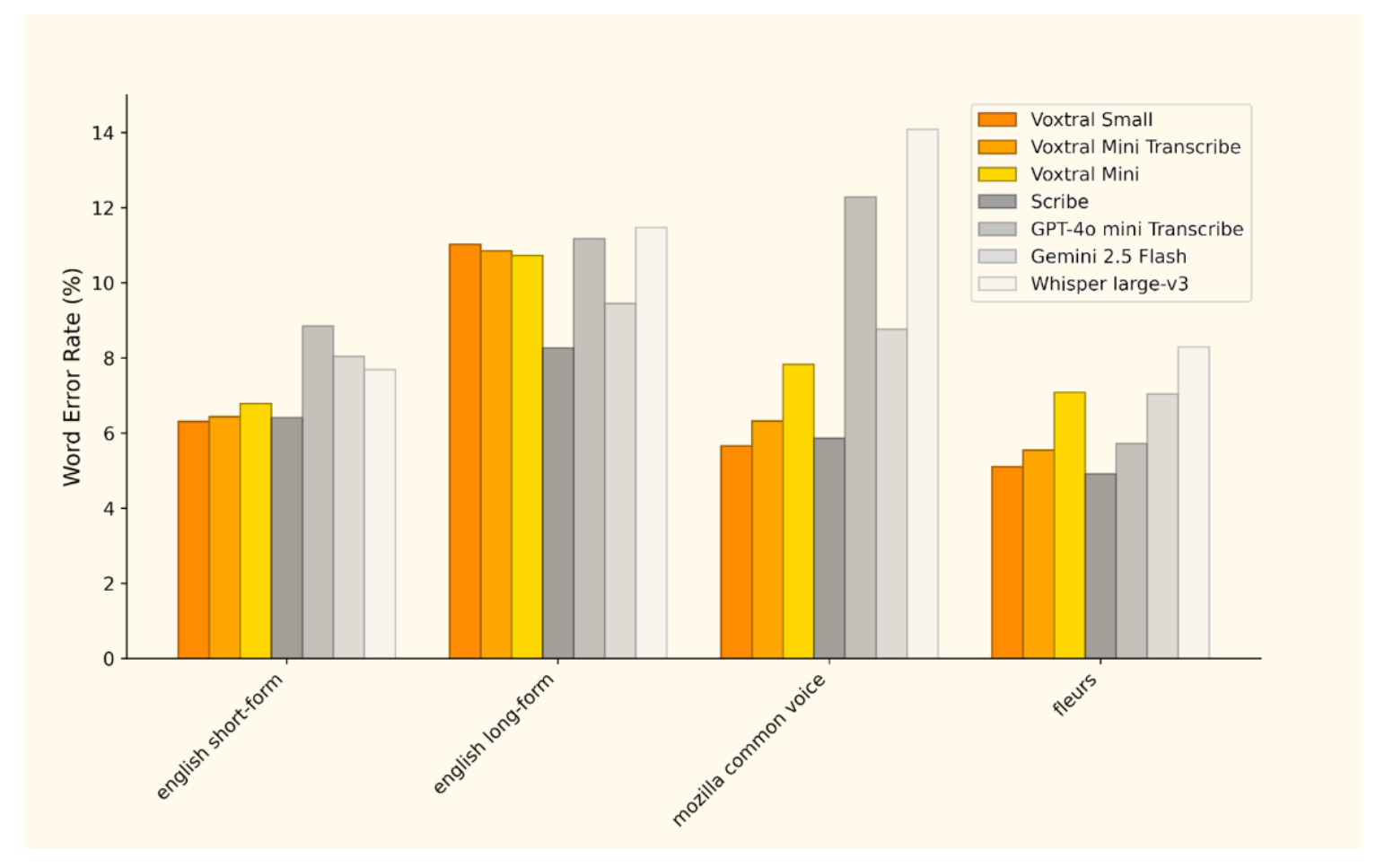
In questa immagine, infine, si mostra un grafico a barre comparativo che valuta le capacità di trascrizione puramente di trascrizione di Voxtral con quelle di altri modelli leader nel campo, misurate sempre tramite Word Error Rate su diversi dataset. I dataset includono English Short Form, English Long Form Mozilla Common Voice e Fleurs e ciascuno di essi presenta sfide diverse, ovviamente, per la trascrizione.
Per quanto riguarda English Short form, Voxtral small e Voxtral mini Transcribe mostrano performance simili e competitive con un errore leggermente superiore al 6%, mentre Voxtral Mini si attesta intorno a 6,5.
Rispetto ai concorrenti, In questo scenario Scribe e GPT GPT-4o mini Transcribe presentano un Word Error Rate più basso, mentre Gemini 2.5 Flash e Whisper sono meno accurati.
Nel dataset English Long Form più complesso Voxtral small e Voxtral mini Transcribe si distinguono mantenendo un errore intorno all’11%, abbastanza utilizzabile come strumento di trascrizione.
Un risultato comunque notevole che li posiziona in modo molto competitivo, allineato rispetto ai competitors a una frazione del prezzo.
Su Mozilla Common Voice Su Mozilla Common Voice Voxtral small e Voxtral mini Transcribe continuano a dimostrare performance molto solide, con un errore rispettivamente sotto il rispettivamente sotto il 6 e 7% e Box Real Mini si mantiene sotto all’8%.
In questo scenario i modelli Voxtral competono molto efficacemente con Scribd e Gemini, superando nettamente gli altri modelli che mostrano errori superiore al 12%, pensate.
Infine sul DataSet Fleurs, i modelli Voxtral confermano la loro eccellenza con errori intorno a 5-5,5%, raggiungendo quasi Scribe e risultando significativamente più accurati di Gemini e Whisper.
Questo evidenzia la capacità di Voxtral di mantenere un’elevata precisione anche su dataset multilingue o particolarmente variegati.
Complessivamente, direi che l’analisi del grafico rileva che i modelli Voxtral small e Voxtral mini Transcribe offrono capacità di trascrizione molto molto competitive, spesso superiori rispetto ai concorrenti su diversi tipi di audio, dimostrando particolare forza nella gestione di audiotrascrizioni di grande varietà e di lunghezze differenti.
Bene, in questa puntata abbiamo discusso di Voxtral, l’efficiente e molto efficace modello di riconoscimento e il ragionamento vocale rilasciato recentissimamente da Mistral AI.
Si tratta di un modello open source di matrice europea che segna un passaggio importante nel panorama dell’intelligenza artificiale mondiale.
Parliamo di un modello aperto che sarà senz’altro utilizzatissimo vista la sua dimensione molto maneggevole, la flessibilità e la modularità in un mondo sempre più orientato all’utilizzo di assistenti vocali, anche attraverso l’interazione vocale e non solo testuale, che in molti casi può essere più lenta e meno dinamica.
Ciao, dalla prossima puntata di Le Voci dell’AI.