

{kind=link}
Ciao a tutti, sono Vincenzo Lomonaco, ricercatore e docente all’Università di Pisa.
Nella puntata di oggi parliamo di AutoEncoders, una soluzione sempre più usata nel mondo dell’intelligenza artificiale per tantissime applicazioni e come componente essenziale di numerose soluzioni metodologiche allo stato dell’arte.
Di cosa si tratta e perché è così interessante soprattutto in mancanza di insiemi di dati di addestramento particolarmente accurati ed etichettati? Perché è una soluzione usatissima nel contesto del rilevamento di anomalie, a prescindere dal dominio e tipo di dato? Scopriamolo insieme in questa puntata di Le Voci dell’AI.
Come abbiamo discusso più volte nel contesto di questa rubrica, l’apprendimento supervisionato e quello non supervisionato sono due paradigmi distinti dell’apprendimento automatico: nel primo il modello apprende da dati etichettati, quindi input associati a un output noto, mentre il secondo lavora su dati non etichettati cercando di scoprire strutture o rappresentazioni latenti all’interno dei dati stessi.
In questo contesto si inseriscono gli AutoEncoder, una classe di reti neurali artificiali progettate per l’apprendimento non supervisionato.
Il loro obiettivo è apprendere una rappresentazione compressa di un input per poi ricostruirlo il più fedelmente possibile.
L’output è quindi identico all’input e l’errore di ricostruzione funge da segnale per aggiornare i pesi della rete attraverso gli stessi schemi di addestramento tipici dell’apprendimento supervisionato, come la discesa del gradiente e la back propagation.
Gli AutoEncoder sono composti da due componenti principali: l’encoder, che trasforma l’input in una rappresentazione latente di dimensione inferiori e il decoder che tenta di ricostruire l’input originale da questa rappresentazione intermedia.
Gli AutoEncoders, introdotti già negli anni ’80, sono stati inizialmente utilizzati per la riduzione della dimensionalità, la compressione, ma con l’avvento del deep learning hanno anche guadagnato una nuova attenzione grazie alla loro capacità di apprendere rappresentazioni profonde.
Le principali varianti metodologiche includono gli Sparse AutoEncoder che forzano l’attivazione di pochi neuroni della rappresentazione latente per ottenere codifiche più interpretabili, generali e robuste, e i Variational AutoEncoder che adottano un approccio probabilistico e sono impiegati nella generazione di nuovi dati simili a quelli di partenza.
Un’altra variante molto importante è quella dei Denoising AutoEncoder, progettata per ricostruire l’input originale a partire da una versione corrotta dal rumore.
Questo costringe il modello ad apprendere caratteristiche più robuste in varianti generalizzabili dei dati e questa capacità li rende strumenti molto efficaci non solo nella compressione, ma anche nel pretraining di modelli più complessi e altre applicazioni.
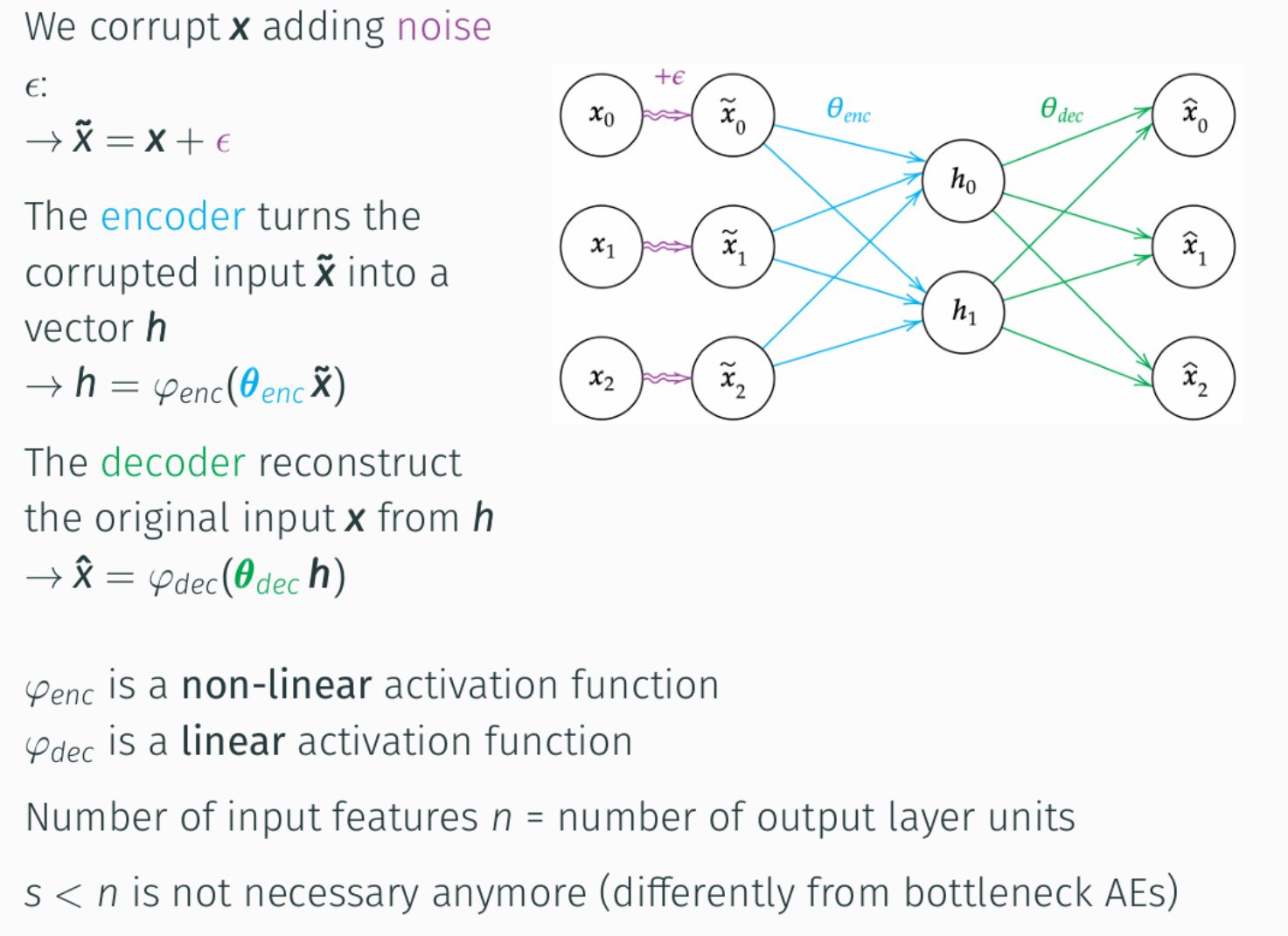
In questa immagine vediamo una possibile implementazione di un Denoising AutoEncoder.
Il processo inizia corrompendo l’input originale x, aggiungendo del rumore ε, ottenendo così un input rumoroso x̃.
Questo input corrotto viene poi dato in pasto all’encoder. L’encoder presentato dalla funzione ɸenc con parametri θenc trasforma x̃ in una rappresentazione latente compressa h.
Si noti che ɸenc utilizza una funzione di attivazione non lineare, permettendo al modello di catturare relazioni complesse nei dati di input.
Successivamente, il decoder rappresentato dalla funzione ɸdec con parametri θdec, prende questa rappresentazione h, compressa, latente e cerca di ricostruire l’input originale pulito x producendo quindi un output x̂.
A differenza dell’encoder, il decoder spesso impiega una funzione di attivazione lineare, specialmente quando l’output desiderato è un valore continuo.
Il processo di addestramento di un modello di questo tipo mira a minimizzare l’errore di ricostruzione tra l’output predetto ricostruito, x̂ e l’input originale pulito x.
Ciò si ottiene utilizzando una funzione di perdita come l’errore quadratico medio, la differenza tra questi due vettori e un algoritmo di ottimizzazione come la discesa del gradiente stocastica.
Durante l’addestramento, quindi, il modello impara a ripulire, se vogliamo, il rumore e a catturare le caratteristiche intrinseche della distribuzione dei dati originali.
E questa la capacità di estrarre pattern sottostanti e ignorare le fluttuazioni casuali che rende i Denoising AutoEncoder particolarmente efficaci per compiti come rilevamento di anomalie e la riduzione del rumore.
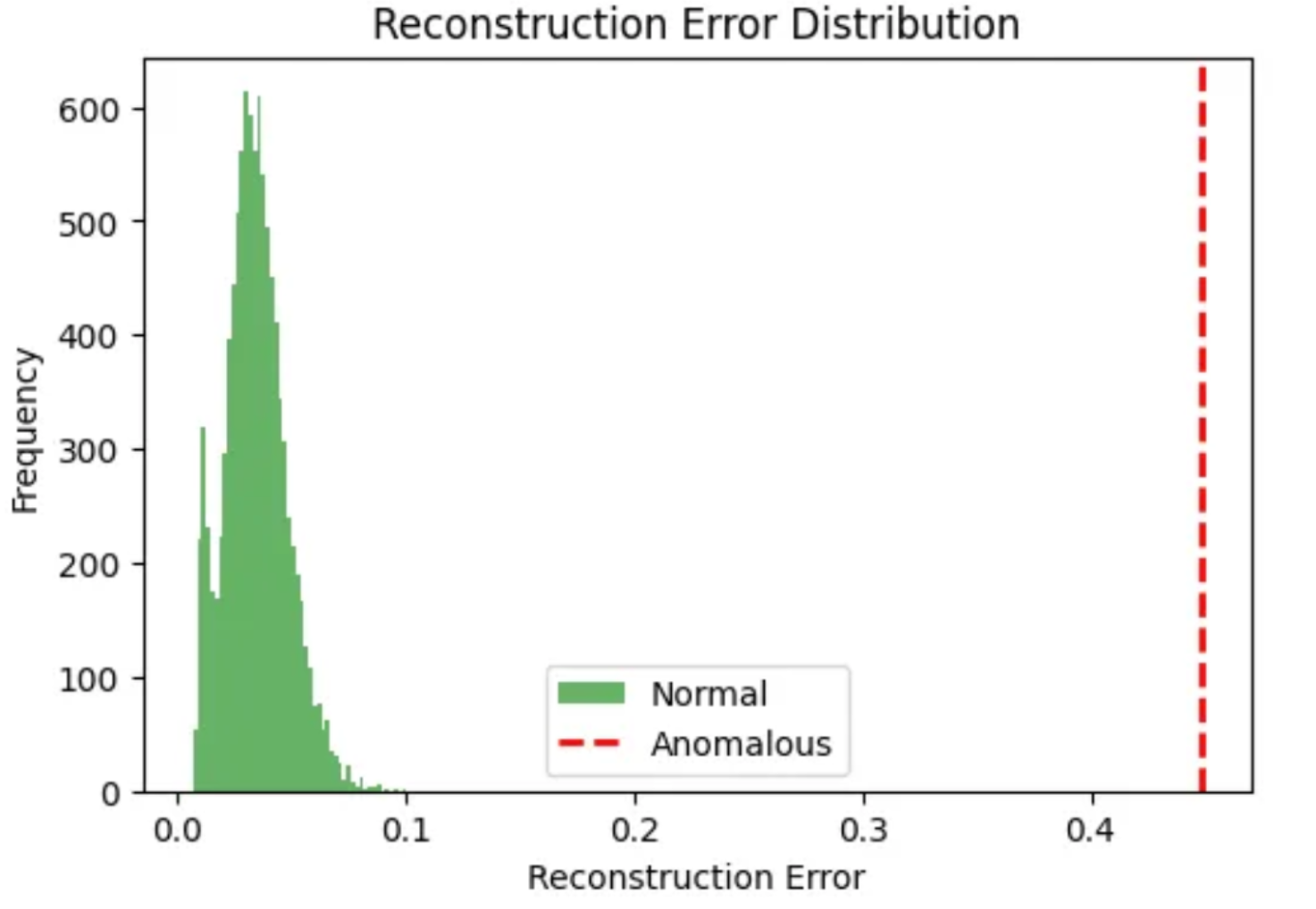
In questa immagine vediamo invece un istogramma della distribuzione dell’errore di ricostruzione generato da un AutoEncoder.
La campana di colore verde rappresenta gli errori di ricostruzione per i dati considerati normali.
Si può notare che la maggior parte dei dati normali ha un errore di ricostruzione molto basso e concentrato attorno a valori prossimi allo zero, indicando che l’AutoEncoder è stato in grado di ricostruire questi dati con alta fedeltà.
La linea verticale rossa tratteggiata, invece, può essere intesa come una soglia per segnalare eventuali anomalie.
Il suo posizionamento qui corrisponde a un valore di errore di ricostruzione significativamente più alto, vedete, circa 0,45.
Questo evidenzia come i dati anomali producano un errore di ricostruzione molto elevato e questo è il principio fondamentale alla base dell’uso delle AutoEncoder per il rilevamento di anomalie.
Un AutoEncoder viene addestrato esclusivamente sui dati normali, imparando a codificare e decodificare efficientemente solo i pattern tipici e attesi e di conseguenza quando gli viene presentato un dato che devia significativamente da questi pattern appresi, un’anomalia per definizione, il modello non è in grado di ricostruirlo accuratamente, risultando in un errore di ricostruzione notevolmente superiore rispetto ai dati normali.
Questo approccio si presta a svariate applicazioni e tipi di dati per il rilevamento di frodi.
Ad esempio, nelle transizioni finanziarie, un AutoEncoder può essere addestrato su milioni di transizioni legittime: una transizione fraudolenta che si discosta dei pattern tipici: importo insolito, località inaspettata, frequenza anomala, genererà un errore di ricostruzione elevato, segnalando come una potenziale frode l’accaduto.
Nei dati di sensori per il monitoraggio della salute dei macchinari industriali, l’AutoEncoder impara il comportamento normale di vibrazioni, temperatura o pressione e un guasto imminente che altera questi pattern si manifesterà con un alto errore di ricostruzione nella sicurezza informatica.
Analizzando il traffico di rete, l’AutoEncoder apprende i pattern di comunicazione leciti e tentativi di intrusione o attacchi di diniego del servizio che presentano comportamenti di rete inusuali saranno identificati da errori di ricostruzione altrettanto elevati e così anche nel mondo della visione artificiale, per esempio per immagini mediche, ad esempio risonanze magnetiche o raggi X, addestrando l’AutoEncoder su immagini sane, anomalie come tumori o lesioni produrranno un elevato errore di ricostruzione nelle regioni interessate.
In sintesi, la chiave è la capacità dell’AutoEncoder di modellare la normalità e di segnalare con un alto errore di ricostruzione tutto ciò che non si conforma a tale normalità.
Indipendentemente dalla natura specifica dei dati, che siano tabulari, serie, temporali, immagini, eccetera.
Bene, in questa puntata abbiamo discusso del concetto e metodologia dell’AutoEncoder, uno strumento molto semplice e potente basato su reti neurali artificiali, che può essere usato per imparare la distribuzione dei dati ordinaria ed essere usata per vari scopi, dalla compressione al rilevamento di anomalie e AutoEncoder che possono essere visti anche come i precursori dei modelli generativi più potenti basati su Transformers, ma sono ancora utilizzati massimi oggi per diverse applicazioni e casi di studio reali.
Ciao! Alla prossima puntata di Le Voci dell’AI.