

{kind=link}
Ciao a tutti, sono Vincenzo Lomonaco, ricercatore e docente all’Università di Pisa.
Nella puntata di oggi parliamo di qualcosa di assolutamente fondamentale per l’implementazione e l’utilizzo dell’intelligenza artificiale moderna basata sui Large Language Models.
Parliamo della tecnica di batching continuo per velocizzare l’inferenza e quindi i tempi di risposta delle nostre soluzioni di AI.
È possibile raggruppare in modo intelligente le richieste di utilizzo dei modelli di Ai nel cloud prima di effettuare delle predizioni in modo asincrono e scomposto? E soprattutto, quanto impatta tutto ciò in termini di tempi di attesa e consumo? Scopriamolo insieme in questa puntata di Le Voci dell’AI.
Con l’evoluzione dei modelli linguistici di grandi dimensioni, sempre più potenti e costosi in termini computazionali, è emersa l’esigenza di ottimizzare i processi di inferenza, di predizione, soprattutto in contesti, quelli cloud, dove decine o centinaia di utenti inviano richieste allo stesso tempo. In uno scenario multiutente ogni richiesta di inferenza non è più un evento isolato, ma parte di un flusso continuo di richieste di input provenienti da diverse fonti.
Questo ha spinto verso lo studio di soluzioni in grado di sfruttare questo elevato parallelismo potenziale. Una delle più rilevanti è il continuous batching.
Questa tecnica consente di aggregare in tempo reale richieste diverse in un unico batch, massimizzando l’uso delle GPU senza dover aspettare che tutti gli input abbiano la stessa lunghezza o provengano dallo stesso utente.
In questo contesto si inserisce vLLM, un sistema open source progettato per fornire inferenza ad alta efficienza per Large Language Models su larga scala.
vLLM introduce un motore di scheduling ottimizzato chiamato Page Attention, che consente una gestione dinamica della memoria delle richieste in ingresso, riducendo drasticamente la latenza e aumentando il throughput.
Questa architettura si sta rapidamente affermando come standard de facto dell’inferenza per i Large Language Models, grazie anche al supporto attivo di attori industriali come IBM e RedHat che lo stanno adottando e promuovendo nei loro ambienti enterprise e infrastrutture native cloud.
Il successo di vLLM riflette la crescente necessità del settore di soluzioni scalabili, efficienti e open source per offrire inferenza di alta qualità a un numero sempre maggiore di utenti, quindi rendendo sostenibile di fatto l’utilizzo dei Large Language Models in produzione e favorendo l’integrazione dell’AI generativa in applicazioni real time multiutente.
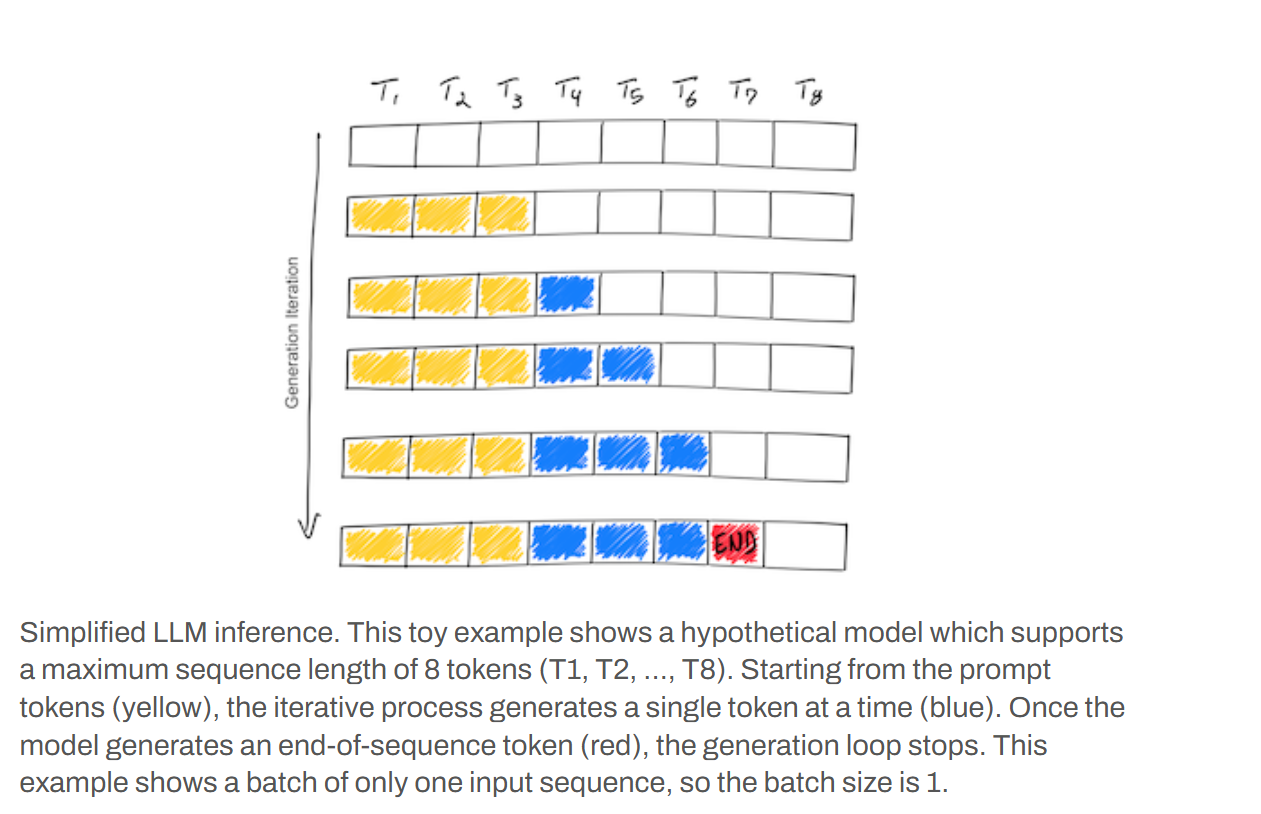
In questa immagine vediamo in modo semplificato il processo di inferenza di un Large Language Model per la generazione di testo.
Si tratta di un esempio ipotetico in cui il modello supporta una lunghezza massima di sequenza di otto token – sottoparole – da T1 a T8.
Il diagramma mostra quindi l’evoluzione della generazione attraverso diverse iterazioni di generazione rappresentate dalle righe orizzontali.
All’inizio la prima riga rappresenta una serie di token di input che caratterizzano il nostro prompt, la query, evidenziati in giallo.
L’inferenza è un processo iterativo che a ogni passaggio/iterazione genera un singolo nuovo token rappresentato dai blocchi blu.
Questi nuovi token vengono aggiunti sequenzialmente alla stringa già generata.
Ecco, l’esempio mostra quindi come i token blu si accumulino di iterazione in iterazione tenendo conto di quelle precedentemente prodotti per massimizzare la coerenza linguistica e generare quindi la nostra risposta testuale.
Il processo di generazione si arresta quando il modello produce un token di fine sequenza, evidenziato in rosso nell’ultima riga. Questo token indica che la risposta è stata completata.
Questo tipo di inferenza, dove i token vengono generati uno alla volta per una singola richiesta, è spesso inefficiente per carichi di lavoro molto elevati e richieste parallele molto frequenti.
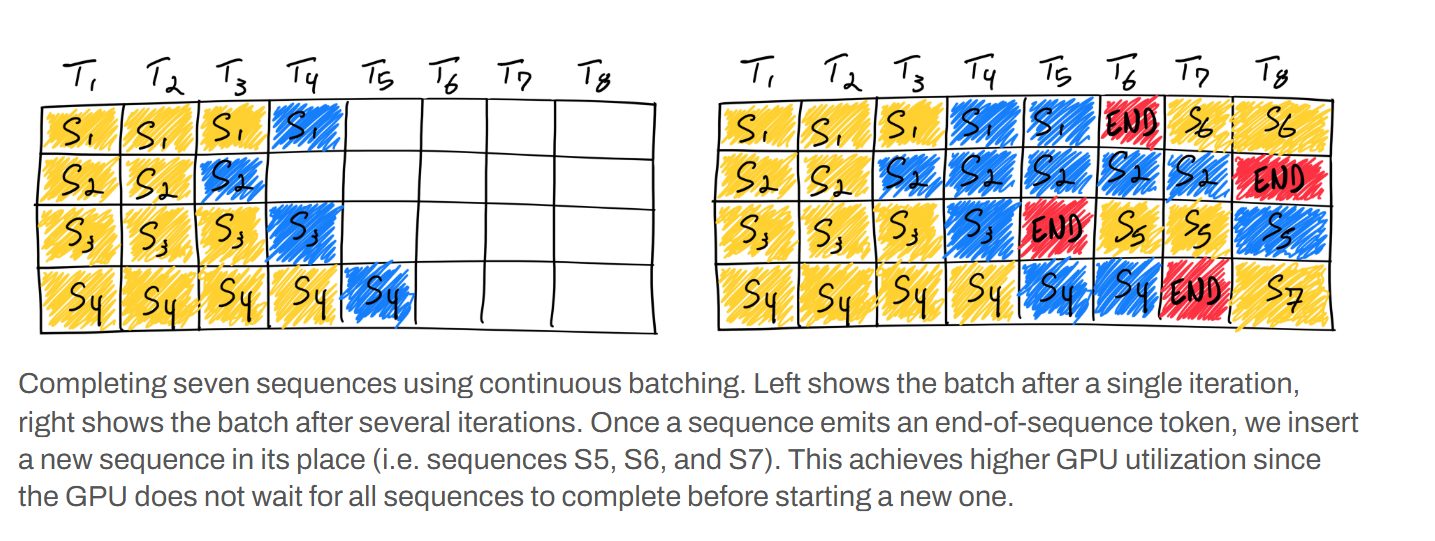
In questa immagine, Invece, vediamo due approcci per gestire più richieste in parallelo nella inferenza di un Large Language Model, entrambi basati sul concetto di batching – raggruppamento.
Il batching consiste nell’elaborare più sequenze di input contemporaneamente per sfruttare meglio le capacità di calcolo, in particolare di quello parallelo offerto dalle GPU.
La parte sinistra del diagramma mostra l’inizio di un processo che potrebbe rappresentare sia un batching naïve, come viene detto, sia l’inizio di un batching continuo.
Qui quattro sequenze o richieste, S1 S2 S3 S4, vengono elaborate simultaneamente.
Ogni riga rappresenta una sequenza; i token gialli, come prima, sono i prodotti iniziali, mentre quelli blu sono i token appena generati dalla prima iterazione.
Nel naïve il sistema attenderebbe che tutte le sequenze nel batch siano completate, cioè che ognuna generi il suo token di fine sequenza prima di elaborare un nuovo batch.
Questo, ovviamente, comporta delle inefficienze, perché alcune sequenze potrebbero terminare molto prima di altre, lasciando risorse delle GPU inattive in attesa.
La parte destra dell’immagine invece illustra proprio il concetto di continuous batching o batch in continuo dopo diverse iterazioni: si nota che alcune sequenze, S1, S3, S4, hanno già emesso il loro token di fine sequenza rosso.
Il punto cruciale del continuous batching è che non appena una sequenza viene completata, il suo slot nel batch non rimane vuoto.
Invece, una nuova sequenza come S5, S6, S7, che compaiono al posto delle sequenze terminate, viene immediatamente inserita nel batch per iniziare l’elaborazione.
Questo meccanismo consente un elevato e quasi continuo utilizzo della GPU.
Le risorse di calcolo sono quindi sempre occupate a elaborare sequenze attive, massimizzando il throughput e riducendo i tempi di attesa complessivi del sistema.
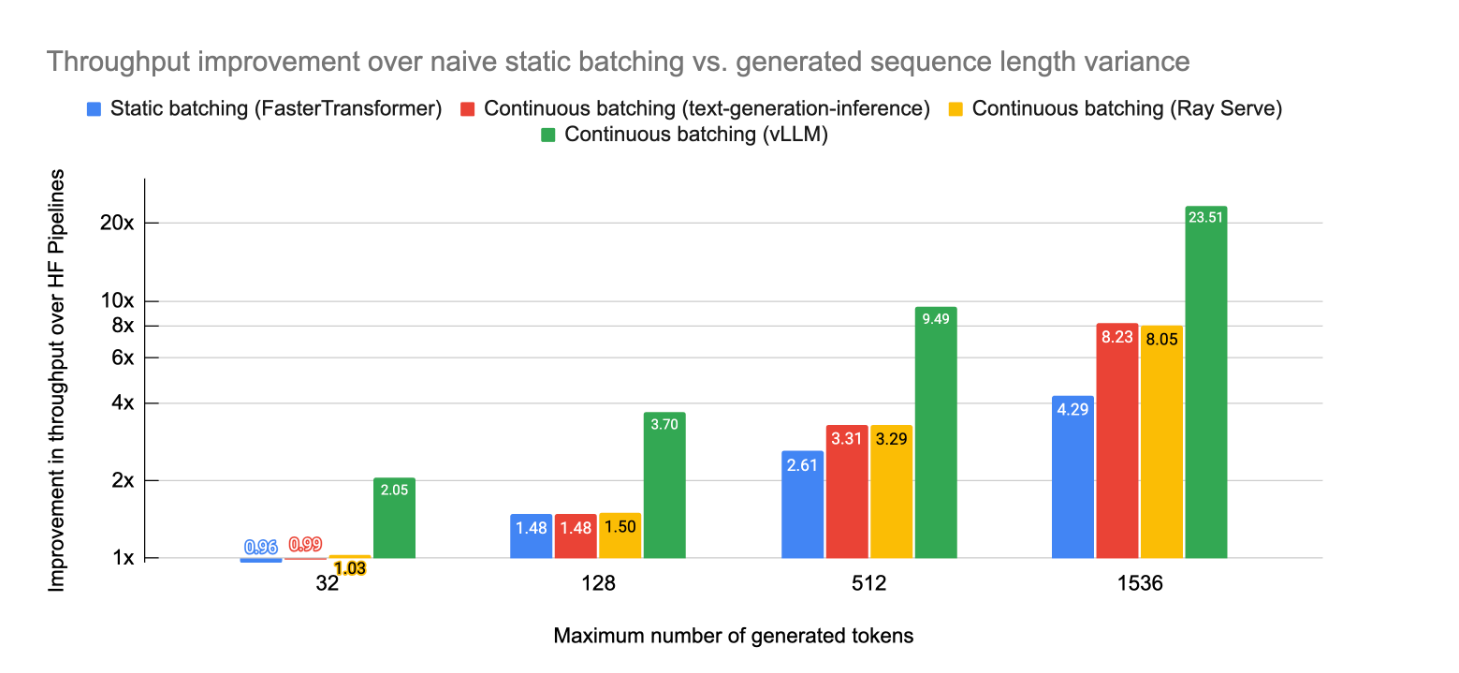
In questo grafico vediamo invece i risultati empirici nell’applicazione di questa strategia.
In particolare vediamo il miglioramento del throughput, quindi la quantità di lavoro svolto per unità di tempo di diverse tecniche di batching su una pipeline di Hugging Face.
Sull’asse orizzontale troviamo il numero massimo di token generati, quindi la lunghezza della sequenza, mentre sull’asse verticale è riportato il miglioramento del throughput come maggioramento rispetto alla baseline.
Si possono osservare quattro diverse strategie: static batching in blu e tre implementazioni diverse di continuous batching, in rosso, giallo e verde per lunghezza di token generati molto brevi, per esempio 32 e fino a un numero massimo di 1536.
Il miglioramento, come vediamo, è limitato, inizialmente, per sequenze molto brevi, ma man mano che il numero massimo di token generati aumenta Il vantaggio del continuous batching diventa sempre più pronunciato.
In particolare, per 1536 token, il Continuous batching basato su vLLM, in verde, emerge chiaramente come il metodo più performante, raggiungendo anche un impressionante miglioramento di 23 volte rispetto al batching statico.
Anche le altre Implementazioni di continuous batching come Ray Serve e text-generation inference mostrano miglioramenti significativi intorno all’8⨯.
Bene, in questa puntata abbiamo discusso di batching dinamico o continuo e di come questa strategia sia essenziale oggi per la gestione e l’efficientamento di modelli di AI nel cloud che devono soddisfare richieste multiutente in parallelo.
I risultati empirici dimostrano chiaramente come il continuous batching, specialmente in implementazioni ottimizzate come vLLM, sia cruciale per massimizzare l’efficienza e le prestazioni dell’inferenza dei Large Language Models, soprattutto quando le sequenze da generare sono particolarmente lunghe Nel futuro non potremmo che aspettarci soluzioni sempre più sofisticate e all’avanguardia per l’inferenza, ma anche l’addestramento parallelo e per sfruttare al massimo l’hardware a nostra disposizione e garantire ai nostri utenti tempi di risposta sempre più rapidi.
Ciao! Alla prossima puntata di Le Voci dell’AI!