

{kind=link}
Ciao a tutti, sono Vincenzo Lomonaco, ricercatore e docente all’Università di Pisa.
Nella puntata di oggi parliamo ancora di Llama 4, la gamma di modelli e di prodotti di AI rilasciati recentemente da Meta, che ha prima eccitato e poi deluso la comunità AI con tante critiche e lamentele.
Dimissioni anche, che hanno portato a una vera e propria rivoluzione dentro Meta.
Di cosa si tratta e come si è arrivati a questo punto? Quali sono le azioni che Meta sta mettendo in atto per risollevare le sorti di Llama e dei suoi modelli open source? E come si relaziona tutto questo con il recente investimento di circa 15 miliardi in Scale AI? Scopriamolo insieme in questa puntata di Le Voci dell’AI.
Nelle ultime settimane l’attenzione del mondo di intelligenza artificiale si è concentrata sul rilascio della nuova famiglia di modelli Llama 4 di Meta, generando inizialmente un’ondata di entusiasmo come noi stessi abbiamo riportato nell’episodio 96 di questa rubrica.
L’annuncio, avvenuto ad aprile 2025, includeva due modelli principali Llama 4 Scout e Llama 4 Maverick, presentati come avanzamenti significativi rispetto alla generazione precedente.
Le promesse di Meta erano ambiziose si parlava di performance di punta, di maggiore comprensione contestuale e capacità di ragionamento più profonde.
La community, quindi, già galvanizzata da queste informazioni e dal rilascio di questi modelli open source, aveva accolto con grande interesse il lancio, sperando in un’alternativa solida ai modelli chiusi e proprietari come quelli di OpenAI o Anthropic.
Tuttavia, l’entusiasmo iniziale ha presto lasciato spazio alla delusione.
Diversi sono infatti i risultati riportati da ricercatori e sviluppatori indipendenti su benchmark terzi, che hanno mostrato performance significativamente inferiori rispetto a quanto dichiarato inizialmente da Meta.
In particolare, i modelli Scout e Maverick si sono posizionati ben al di sotto di altri modelli, anche più piccoli ed efficienti su compiti dell’elaborazione del linguaggio naturale, di programmazione e ragionamento astratto.
Questa discrepanza ha suscitato diverse critiche, alimentando il sospetto che i risultati pubblicizzati fossero stati ottenuti in modo molto artificioso e frettoloso.
A peggiorare la situazione è arrivata la continua posticipazione del rilascio di Llama 4 Behemoth, il modello di punta più grande della serie.
Inizialmente era previsto per aprile, poi è stato rimandato a giugno e ora il suo rilascio è ulteriormente slittato a una data indefinita nell’autunno 2025, addirittura oltre.
Secondo fonti interne, il ritardo sarebbe dovuto a performance non ancora soddisfacenti e a difficoltà interne di coordinamento tecnico.
Questo ulteriore rinvio ha profondamente deluso la comunità AI, che attendeva Behemoth come il vero concorrente ad armi pari di modelli di frontiera più avanzati.
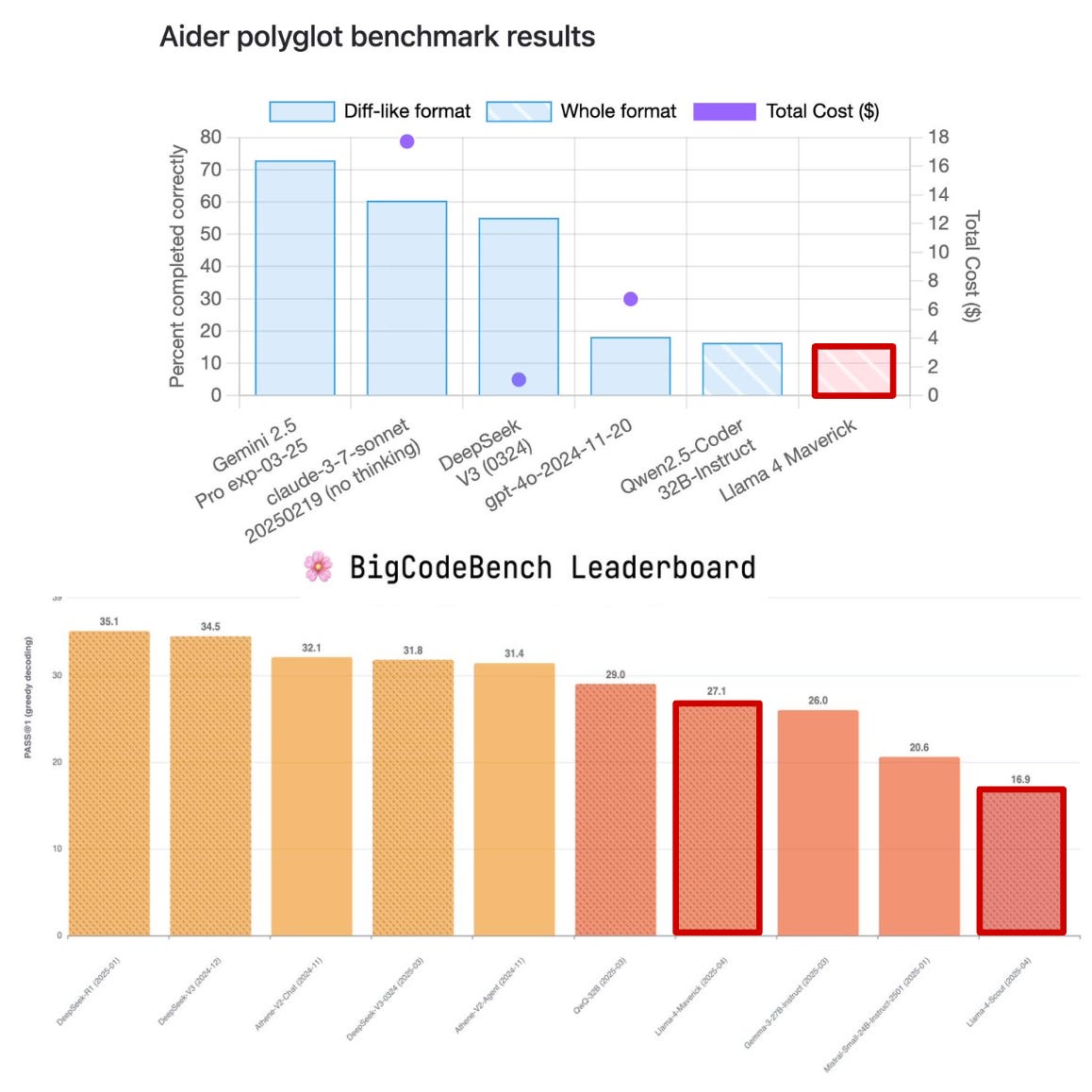
In questa immagine vediamo i risultati di diversi modelli di punta su due benchmark indipendenti, Aider polyglot benchmark e BigCodeBench Leaderboard, focalizzati sulle capacità dei modelli linguistici nei task di programmazione, evidenziando le prestazioni piuttosto deludenti di Llama 4 Maverick rispetto ai suoi concorrenti.
Nel primo grafico, quindi dell’Aider polyglot, si valuta la capacità dei modelli di completare correttamente delle modifiche al codice con il costo totale in dollari indicato da un punto viola.
Llama 4 Maverick, evidenziato con un riquadro rosso, si posiziona in fondo alla classifica completando correttamente una percentuale molto bassa, come vedete, di task rispetto a modelli come Gemini 2.5 Pro rilasciato pressoché nello stesso periodo o Claude 3.7 Sonnet che superano ampiamente il 60/70% di completamento.
Nonostante Maverick sia più economico e più efficiente, le sue performance lo rendono molto poco competitivo, sembra sacrificare troppo la qualità per ridurre i costi, fallendo in compiti di modifica del codice che richiedono precisione e contesto.
Il secondo grafico è relativo al benchmark di BigCodeBench e misura la capacità dei modelli di risolvere correttamente esercizi di programmazione in modo autonomo.
Anche qui Maverick ottiene un risultato molto basso, di circa 27 e la sua versione più piccola, Scout, ottiene soltanto 16.9 come punteggio, che è il più basso.
In questo grafico il confronto DeepSeek R1 guida la classifica con un punteggio di 35.
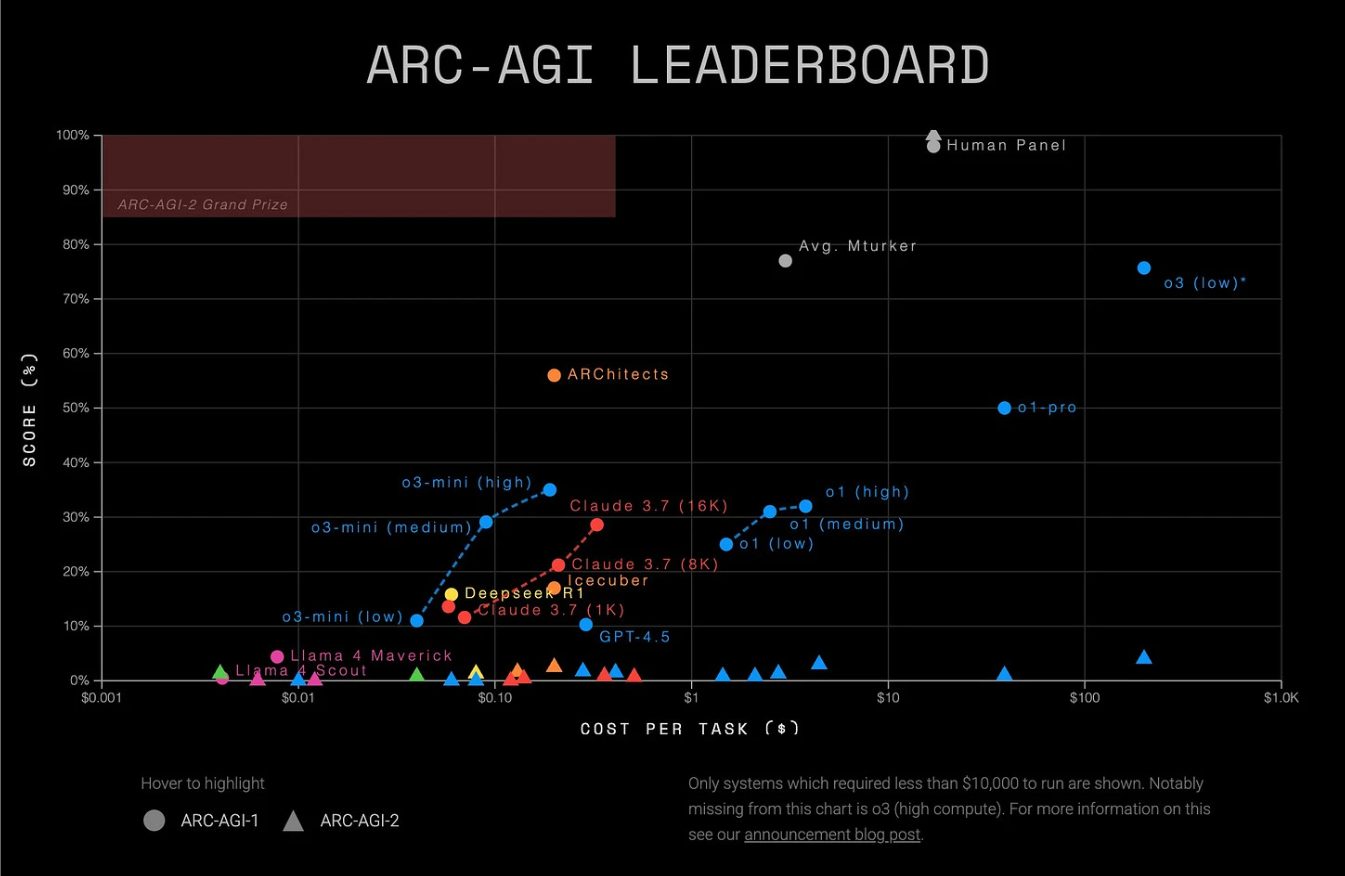
In questa immagine invece vediamo i risultati del benchmark ARC-AGI, un test progettato per valutare la capacità di ragionamento astratto e generalizzazione dei modelli di AI attraverso compiti complessi ispirati all’intelligenza umana come analogie visuo-spaziali e trasformazioni logiche.
Per saperne di più su questo benchmark potete far riferimento all’episodio 82 di questa rubrica, dove ne abbiamo parlato approfonditamente.
In questo grafico i modelli sono valutati in base al punteggio ottenuto sulle ordinate rispetto al costo sulle ascisse, offrendo così una visione bilanciata tra prestazioni di efficienza economica.
I modelli migliori si collocano in alto a sinistra, alto punteggio a basso costo.
Ecco, in questo contesto Llama 4 Maverick, in rosa, si posiziona tra i modelli con le prestazioni peggiori vicine allo zero, sia in accuratezza sia in valore, con un costo per task basso ma completamente insufficiente a giustificarne l’utilizzo.
A fianco di Llama 4 Maverick troviamo la versione Scout con risultati molto simili.
In netto contrasto vediamo invece modelli come GPT 4.5, Claude 3.7, DeepSeek R1 e soprattutto le varianti di o1 e o3-mini, che offrono performance sensibilmente superiori raggiungendo punteggi tra il 20% e il 60% a costi molto diversi.
Il divario prestazionale evidenziato in questo benchmark sottolinea ulteriormente, è un ulteriore esempio, del gap che sussiste tra Maverick e modelli di punta del settore, rafforzando quindi questa percezione che la nuova gamma di modelli Llama 4, almeno nelle sue versioni pubbliche, non sia competitiva nei task di ragionamento più avanzato, elemento chiave nella valutazione della reale intelligenza artificiale generale.
Dopo le performance deludenti dei modelli Llama 4, Mark Zuckerberg ha avviato una profonda ristrutturazione dell’intera organizzazione AI di Meta.
Il fulcro di questa svolta è l’investimento di circa 15 miliardi di dollari in Scale AI, che ha portato all’ingresso in azienda del suo fondatore Alexandr Wang, ora a capo di un nuovo laboratorio interno a Meta dedicato allo sviluppo dell’Artificial General Intelligence.
Questa mossa direi che rappresenta una scommessa strategica per Meta, che mira a iniettare nel cuore dell’azienda una cultura focalizzata sulla velocità, responsabilità tecnica e capacità di esecuzione nel contesto in cui erano percepiti come assenti fino adesso nei team e ai precedenti.
In parallelo è in corso un’aggressiva campagna di assunzioni con bonus da oltre 100 milioni di dollari. Infatti Meta sta cercando di strappare talenti chiave ai suoi competitors come OpenAI DeepMind e Anthropic.
L’obiettivo è chiaramente quello di recuperare terreno e rilancia la posizione dell’azienda nella corsa alle aree di frontiera.
Il messaggio di Zuckerberg è chiaro: per vincere nella prossima fase dell’AI non bastano modelli open, serve anche maggior controllo sui talenti, i dati e le infrastrutture.
Bene, in questa puntata abbiamo discusso del grande flop di Llama 4 e di come la prestazione del modello di punta Maverick abbiano profondamente deluso la comunità di AI.
All’interno di Meta sembra quindi crescere una profonda frustrazione nell’incapacità di competere con successo con altri attori internazionali come OpenAI e Google.
Gli errori relativi al rilascio precoce di Llama 4 sono solo l’ultima dimostrazione di un trend ormai consolidato.
Chissà se questa recente rivoluzione e il massiccio investimento di meta in Scale AI non cambi drammaticamente le carte in tavola e porti finalmente l’azienda a competere tra i grandi con modelli open source di cui noi tutti potremmo beneficiare.
Ciao! Alla prossima puntata di Le Voci dell’AI!