

{kind=link}
Ciao a tutti, sono Vincenzo Lomonaco, ricercatore e docente all’Università di Pisa.
Nella puntata di oggi parliamo di un articolo scientifico recentissimo che ha scosso tutta la comunità dell’intelligenza artificiale.
Parliamo di uno studio pubblicato da un team di ricercatori di Apple che evidenzia i limiti strutturali dei Large Language Models, soprattutto nel modo in cui essi ragionano di fronte a sfide via via più complesse.
Quali sono le conclusioni a cui sono arrivati e soprattutto, quali sono le implicazioni per il futuro dell’AI basata su queste metodologie?
Scopriamolo insieme in questa puntata di Le Voci dell’AI.
La scorsa settimana è uscito un articolo scientifico di Apple molto discusso, intitolato The Illusion of Thinking, che sta facendo parecchio rumore nella comunità; ne ha parlato anche Gary Marcus in un blog post sul suo blog dal titolo piuttosto provocatorio, A knockout blow for LLMs?.
Secondo lui e molti altri, questo studio potrebbe rappresentare un colpo decisivo contro l’idea che i grandi modelli linguistici come ChatGPT o Claude siano davvero capaci di ragionare.
Ma in realtà il dibattito non è nuovo.
Da anni si discute se questi modelli siano effettivamente in grado di ragionare oppure se stiano solo simulando il ragionamento, cioè producendo output che sembrano intelligenti, senza però capire davvero cosa stanno facendo.
Quello che fa Apple però, è portare una prospettiva nuova, un po’ diversa.
Invece di valutare le performance dei modelli solo in base a compiti classici di ragionamento, li analizza dal punto di vista della complessità computazionale dei problemi.
E cosa scopre? Che i Large Language models se la cavano bene quando i problemi sono semplici, cioè risolvibili con algoritmi rapidi, di tipo lineare o costante.
Ma appena la complessità cresce, come nei problemi NP-hard, le loro prestazioni crollano, anche se la formulazione linguistica del compito rimane piuttosto simile.
Questo è interessante perché suggerisce che i modelli non stanno davvero capendo il problema, ma reagiscono in base a quanto è facile, sotto il cofano, dal punto di vista computazionale lo stesso.
Un altro punto importante è che non basta semplicemente aumentare la dimensione del modello o il tempo a disposizione per risolvere un problema.
Anche modelli molto grandi continuano a fallire su compiti complessi, quindi la scalabilità a livello di risorse da sola non sembra bastare a far emergere un vero ragionamento.
In sintesi Apple ci dice che c’è un limite strutturale, non solo quantitativo, alle capacità di questi modelli.
Ovviamente questo non vuol dire che i Large Language Models siano inutili, anzi in molti contesti sono strumenti straordinari, ma ci mette in guardia contro l’idea che siano già in grado di pensare in senso pieno.
Ma vediamo i loro risultati principali più nel dettaglio.
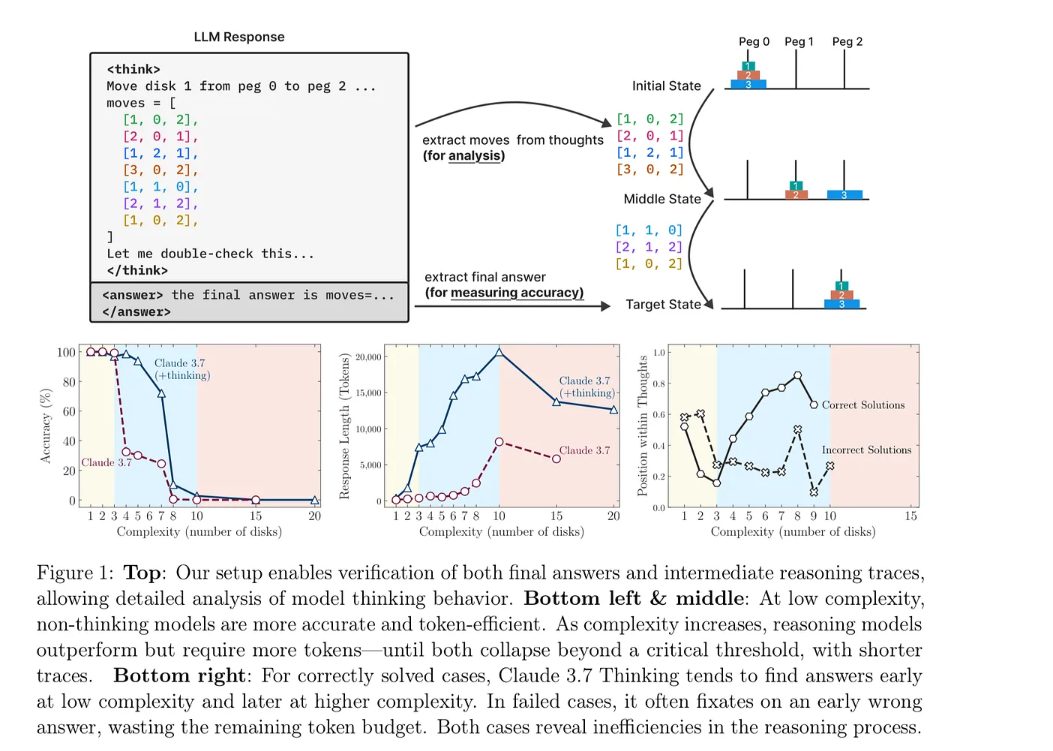
In questa immagine vediamo uno degli esperimenti centrali del paper, basato sul classico problema delle Torri di Hanoi, un compito noto in informatica per testare le capacità di pianificazione e ragionamento sequenziale.
L’obiettivo in questo caso è spostare una pila di dischi da un piolo iniziale a uno di destinazione seguendo due regole principali: si può muovere un solo disco alla volta e non si può mai posare un disco più grande sopra uno più piccolo.
La difficoltà, ovviamente, cresce molto rapidamente con il numero di dischi, rendendolo un banco di prova ideale per valutare le prestazioni su compiti di complessità crescente.
Nel riquadro in alto viene mostrato come i ricercatori hanno strutturato l’analisi il modello Claude 3.7 genera una sequenza di passi intermedi tra i tag Sync e Answer, che vengono poi verificati contro la sequenza corretta per determinare accuratezza e comportamento del ragionamento.
I tre grafici in basso invece sintetizzano i risultati a sinistra vediamo che a bassa complessità, quindi da 1 a 4 dischi anche il modello senza fase di ragionamento Claude 3.7 ottiene ottime performance, ma quando la complessità aumenta, l’accuratezza crolla rapidamente, anche per la versione di Thinking, di ragionamento più avanzata.
Al centro il grafico mostra come i modelli che pensano impiegano molti più token molto più costosi dal punto di vista computazionale, man mano che il compito diventa più complesso fino a un punto critico in cui falliscono comunque.
A destra, infine, si analizza dove nel processo di pensiero viene generata la risposta.
Nei casi corretti la risposta arriva verso la fine, a bassa complessità o a metà a media complessità, mentre nei casi errati la risposta è spesso proposta troppo presto, con il modello che si fissa su una soluzione errata, consumando il budget di token in modo inefficiente.
In sostanza, questo esperimento mostra che, anche con il ragionamento esplicito, i Large Language Models tendono a fallire quando il compito supera una certa soglia di complessità, gettano la spugna troppo presto, per capirci, rilevando limiti strutturali nella loro capacità di ragionamento e pianificazione.
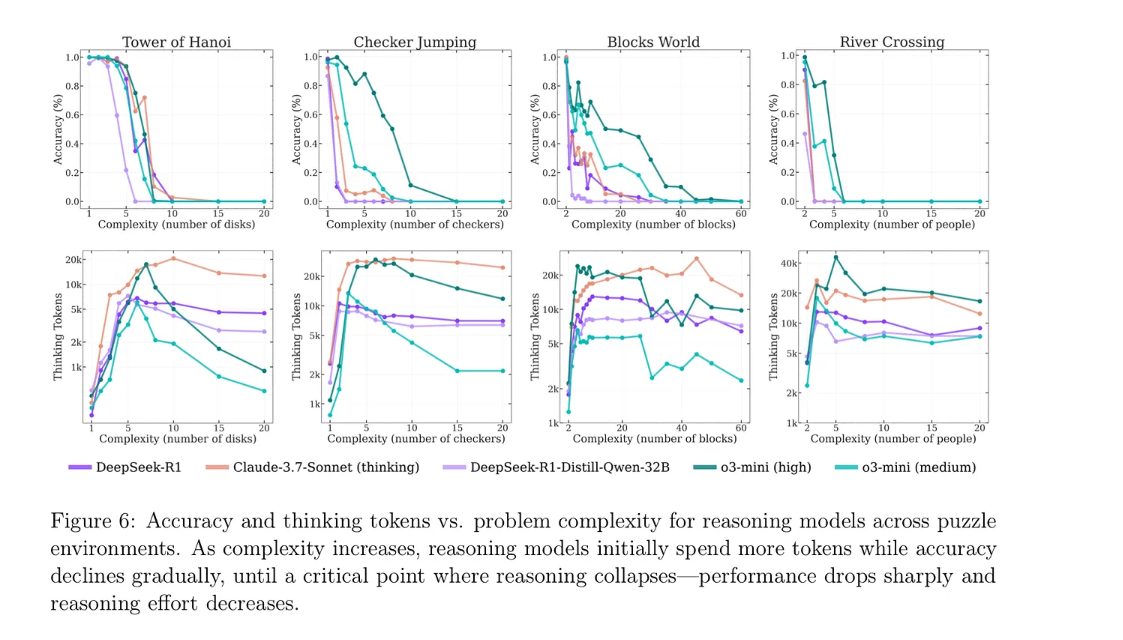
In questa immagine, invece, vediamo l’estensione dell’analisi dell’articolo di Apple anche ad altri tre giochi di ragionamento classici oltre alle Torri di Hanoi: Checker Jumping, Blocks World e River Crossing.
Ogni colonna mostra come varia la performance dei modelli al crescere della complessità del problema, misurata in base a elementi come il numero di dischi dalle torri di Hanoi, blocchi o persone coinvolte negli altri giochi.
I grafici superiori indicano l’accuratezza, mentre quelli inferiori mostrano quanti token vengono spesi nella fase di pensiero, ovvero nei passaggi intermedi tra input e risposta finale.
Un pattern chiaro emerge: inizialmente i modelli migliorano, mantengono le performance aumentando l’impegno computazionale, cioè usando più token per ragionare.
Tuttavia, superata una soglia critica di complessità, l’accuratezza crolla improvvisamente, quindi non gradualmente, e anche il numero di token usati tende a diminuire o fluttuare, segnando un collasso nella capacità di ragionamento.
Questo vale anche per modelli più avanzati come Claude 3.7 con modalità thinking attiva e persiste su ambienti con strutture e dinamiche differenti, suggerendo che il fenomeno è centralizzato, non esclusivo e relativo al problema delle Torri di Hanoi.
In sintesi, i Large Language Model sembrano in grado di gestire solo problemi entro una certa finestra di complessità, oltre quel limite, nella potenza, nel ragionamento esplicito riescono a compensare, rilevando che di limiti sistemici.
Bene, in questa puntata abbiamo discusso di un recentissimo e molto dibattuto articolo scientifico di Apple che mette in luce limiti strutturali al ragionamento dei Large Language models.
Nel corso di questa rubrica abbiamo discusso più volte della capacità di ragionamento di questi modelli e dei risultati incredibili che sono riusciti a raggiungere, specialmente in contesti specifici come la matematica o la programmazione.
Ma abbiamo anche evidenziato molte criticità rilevanti e dubbi sulla loro scalabilità e capacità di generalizzare a problemi di tipo diverso.
Questo articolo ne è un’ulteriore prova.
Cosa dunque aspettarci dal futuro? Un superamento di questi limiti strutturali?
Certamente sì, ma non è chiaro ancora come se, seguendo da un lato la strada dei Large Language Models o con un cambio radicale di paradigma.
Ciao! Alla prossima puntata di Le Voci dell’AI.