

{kind=link}
Ciao a tutti, sono Vincenzo Lomonaco, ricercatore e docente all’Università di Pisa.
Nella puntata di oggi parliamo di Olympus, un sistema molto recente di intelligenza artificiale sviluppato dall’Università di Oxford in collaborazione con Microsoft, che rappresenta una soluzione unica per diversi compiti molto complessi, multimodali e di ragionamento, soprattutto riguardanti la visione artificiale, perché particolarmente interessante e innovativa.
Come può un unico modello riuscire a risolvere compiti particolarmente complessi che neanche ChatGPT o potentissimi modelli di AI allo stato dell’arte, non riescono a risolvere? Scopriamolo insieme in questa puntata di Le Voci dell’AI.
Il rilascio di Olympus per la conferenza CVPR 2025 segna un momento chiave nell’evoluzione della computer vision, proponendosi come una piattaforma unificata capace di affrontare simultaneamente molteplici task di visione artificiale, superando il tradizionale approccio, un modello per ogni compito, che ha dominato il settore negli ultimi anni.
Fino a oggi lo sviluppo nel campo della visione artificiale, infatti, è stato fortemente frammentato: per ogni problema, che si tratti di classificazione e segmentazione, rilevamento oggetti, stima della posa, ricostruzione 3D, si costruiva un modello specializzato, spesso ottimizzato solo per quel singolo compito.
Questo paradigma ha portato a una proliferazione di architetture distinte, pipeline separate e dataset specifici, rendendo difficile l’integrazione tra task e aumentando la complessità dei sistemi reali.
Olympus rompe questa barriera proponendo un framework generalista che, pur ispirandosi alla filosofia dei Large Language Models, quindi un singolo modello capace di gestire input output diversi, riesce però a mantenere una qualità comparabile e in certi casi superiore agli approcci specializzati.
È noto infatti che, nonostante la straordinaria flessibilità dei Large Language Models, questi modelli spesso non raggiungono la precisione dei sistemi progettati ad hoc per un singolo task visivo, soprattutto nei contesti dove il dettaglio e la precisione sono cruciali.
Olympus colma proprio questo gap utilizzando un’architettura modulare e multimodale che consente di trattare i vari task come dialetti di un’unica lingua visiva, con la possibilità di adattarsi dinamicamente al contesto senza sacrificare la performance specifica.
Questo approccio apre la strada a soluzioni uniche, dove attività prima separate, come la comprensione di una scena complessa che richiede contemporaneamente identificazione e segmentazione e stima della profondità, possono essere affrontate in modo sinergico.
La motivazione profonda, quindi, dietro Olympus nasce dall’esigenza di superare i limiti della compartimentazione della specializzazione estrema, mantenendo però l’alta qualità richiesta dalla visione artificiale moderna per tante applicazioni.
Il risultato è un sistema che si avvicina alla versatilità dei Large Language Models, ma con una cura ingegneristica, una precisione che rispetta le esigenze specifiche di applicazioni complesse, aprendo nuovi orizzonti nella ricerca e nella commercializzazione di queste soluzioni.
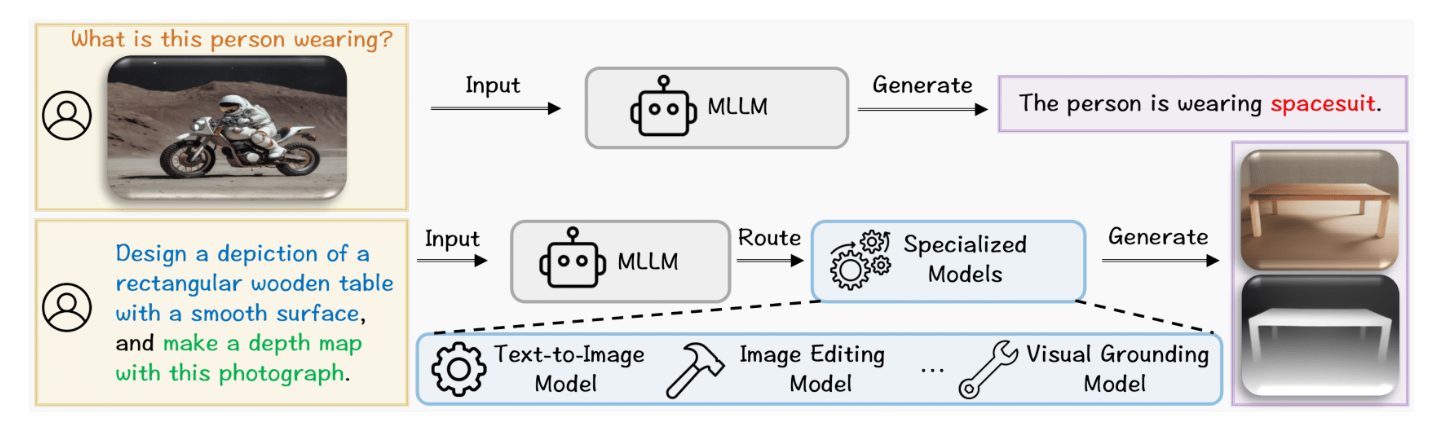
In questa immagine vediamo l’architettura alla base di Olympus, evidenziando la sua strategia chiave: combinare la versatilità di modelli linguistici multimodali, MLLM con la potenza dei modelli specializzati di computer vision.
Nella parte superiore vediamo un caso semplice, quello dello stato dell’arte, in cui l’input visivo con una domanda, un quesito, su una persona in moto su un terreno lunare viene passato direttamente al Multimodal Large Language Model, che grazie alla sua capacità di comprensione multimodale, genera una risposta corretta: questa persona veste una tuta spaziale.
Questo rappresenta quindi anche il livello base di Olympus, simile ai grandi modelli generici attuali che eseguono un task di comprensione in linguaggio naturale, combinato eventualmente degli elementi visivi.
Tuttavia, la vera innovazione di Olympus emerge nella parte inferiore della figura.
In questo esempio, dove abbiamo un quesito un po’ più complesso – progetta una rappresentazione di un tavolo rettangolare in legno con una superficie liscia e realizza una mappa di profondità corrispondente con questa fotografia come input – il sistema quindi non si affida soltanto al Multimodal Large Language Models, ma attiva un meccanismo di routing, di smistamento intelligente, ossia il Multimodal Large Language Model funge da dispatcher che comprende l’intento dell’utente e indirizza la richiesta verso una combinazione eventuale di modelli specializzati: un modello di text to image per generare la rappresentazione visiva del tavolo dato il testo; un modello di visual editing per adattare l’immagine e infine un modello di visual grounding, di stima della profondità per produrre la texture.
Questo schema modulare permette a Olympus di scalare in termini di complessità dei quesiti risolti senza sacrificare la qualità, superando il limite dei Multimodal Large Language Models moderni puramente generalisti che tendono a degradare le performance su task visivi così complessi e avanzati.
L’approccio di Olympus unisce quindi il meglio dei due mond: da un lato la flessibilità e la comprensione contestuale dei Multimodal Large Language Models, dall’altro la precisione e potenza dei modelli specializzati, mantenendo ogni componente ottimizzato per il proprio compito specifico.

Questa immagine invece, illustra la portata e la versatilità di Olympus, evidenziando come il sistema riesca a coprire oltre venti compiti distinti della Computer Vision, spaziando tra immagini, video e contenuti 3D.
In alto vediamo funzioni come il text to Image capace di generare immagini personal usate da descrizioni, per esempio “un chihuahua vestito con colori vivaci” e il text to video che crea sequenze realistiche di immagini come il fuoco che arde in un contenitore.
Nella seconda riga si mostrano task più sofisticati, come la generazione controllata dove l’immagine viene guidata da uno schizzo,un prompt e la generazione text to 3d, che produce addirittura modelli tridimensionali dettagliati dal testo.
Pensate quanto questo possa utile possa essere utile per la progettazione di componenti da stampare 3D o dell’industria.
La terza sezione introduce la capacità di Chain of Action o catena di azioni di Olympus, la parte più interessante che riguarda l’esecuzione sequenziale di più operazioni.
Un cavallo viene prima disegnato, poi colorato diversamente, infine trasformato in una mappa normale per uso tecnico.
Infine vengono mostrati compiti come la stima della posa umana da immagini e l’image editing, dove elementi vengono aggiunti o modificati, ad esempio i libri accanto al cane e persino la conversione image to 3D per creare asset tridimensionali ad alta qualità a partire da un’immagine.
Olympus quindi emerge come una piattaforma unica capace di integrare e concatenare compiti che fino ad ora richiedevano sistemi separati.
In questa puntata abbiamo parlato di Olympus, un sistema di intelligenza artificiale che capace di smistare sotto compiti ad altri modelli più esperti e fornire all’utente risposte molto precise a quesiti complessi che richiedono competenze diverse e multimodali.
Olympus non solo rappresenta quindi un’importante pietra miliare per il mondo della visione artificiale, ma anche un interessante caso di studio per un approccio diverso allo sviluppo dell’intelligenza artificiale generale.
Non costruire più enormi modelli monolitici con la pretesa che possano risolvere ogni possibile compito, ma utilizzarli piuttosto per orchestrare l’utilizzo di modelli più piccoli ma esperti in un particolare dominio.
Questo rappresenta anche il funzionamento di una qualsiasi organizzazione umana, dove non c’è solo un dipendente geniale che sa fare tutto, ma è l’interazione di più individui capaci in differenti aree a rendere l’organizzazione efficace.
Ciao! Alla prossima puntata di Le Voci dell’AI!