


Data Awakening. Infra Evolving. Lo slogan dell’Huawei Innovative Data Infrastructure Forum 2026, tenutosi a Parigi il 20 e 21 maggio, riassume la tesi che ha attraversato il keynote di apertura: la disponibilità di GPU non basta più. La prossima sfida dell’intelligenza artificiale non riguarda soltanto i modelli, ma l’infrastruttura dati necessaria per alimentarli. Per sostenere agenti intelligenti, inferenza continua e workload distribuiti servono infatti piattaforme capaci di gestire memoria, contesto, resilienza e grandi volumi di dati. Storage, memoria persistente, data fabric e agentic AI vengono così descritti come elementi di un’unica architettura destinata a sostenere la nuova generazione di sistemi intelligenti.
L’intelligenza artificiale sta entrando in una fase nella quale il nodo centrale non è più soltanto la capacità computazionale, ma l’infrastruttura dati necessaria a sostenere agenti intelligenti, inferenza distribuita e workload AI mission critical. Yang Chaobin, Executive Director e CEO dell’ICT Business Group di Huawei, descrive il mercato come una transizione dall’AI sperimentale all’adozione industriale su larga scala.
Con oltre 30 milioni di agenti AI già operativi e una previsione di crescita fino a 2,2 miliardi entro il 2030, l’infrastruttura ICT è destinata ad assumere un ruolo sempre più centrale. “L’AI sta espandendo la produttività e ridefinendo il modo in cui le aziende lavorano e crescono”, afferma Chaobin.

La strategia “All Intelligence” del gruppo punta a costruire una piattaforma capace di sostenere produzione, trasferimento, analisi e conservazione dei dati su scala globale. Huawei collega direttamente la maturazione dell’AI al livello di digitalizzazione delle infrastrutture, sostenendo che la crescita simultanea di modelli, algoritmi e capacità computazionale renda la gestione del dato molto più complessa rispetto al passato.
Tra le trasformazioni destinate ad accompagnare la diffusione dell’AI figura l’adozione sempre più estesa dello storage all-flash nei data center. Gli SSD vengono indicati come elementi indispensabili per sostenere workload ad alta intensità grazie a performance e affidabilità superiori rispetto alle architetture tradizionali. “Con gli SSD possiamo liberare pienamente performance e affidabilità, permettendo un’elaborazione dei dati più veloce e stabile sotto workload AI”, osserva Yang Chaobin.
Ma il cambiamento più importante riguarda il ruolo stesso dello storage. L’infrastruttura dati non dovrebbe più limitarsi a conservare informazioni, ma diventare semanticamente consapevole, capace cioè di supportare modelli AI che lavorano su dati eterogenei, relazioni contestuali e strutture informative complesse.
Huawei collega inoltre la crescita dell’AI al problema energetico dei data center. Secondo Yang Chaobin, algoritmi avanzati di data reduction e nuove architetture storage saranno necessari per contenere consumi, spazio occupato e impatto ambientale. “Continueremo a spingere sulla sostenibilità attraverso migliori algoritmi di riduzione dati, abbassando il consumo energetico e riducendo la footprint dello storage”, afferma.
La visione proposta dal gruppo va oltre il semplice aggiornamento tecnologico dell’infrastruttura. Huawei interpreta il dato come una risorsa dinamica destinata ad alimentare modelli AI, inferenza distribuita e sistemi agentici persistenti. “In futuro il dato non sarà più un petrolio statico, ma un flusso vivente capace di creare valore continuamente”, sostiene Yang Chaobin.
Secondo Huawei, questa trasformazione renderà sempre più critici throughput, bassa latenza, resilienza, capacità di retrieval e gestione semantica del dato. Storage, networking, computing e data management vengono quindi reinterpretati come componenti convergenti di un’unica architettura destinata a sostenere workload AI continui e distribuiti.
L’Europa punta a costruire una propria infrastruttura AI
Secondo Huawei, l’Europa sta entrando in una fase nella quale l’intelligenza artificiale non è più una tecnologia emergente ma una componente strutturale della competitività industriale. Willi Song, President di Huawei Europe Enterprise Business, collega direttamente lo sviluppo dell’AI alla capacità del continente di costruire infrastrutture dati proprietarie, resilienti e sostenibili.
“L’intelligenza artificiale sta cambiando il nostro mondo più velocemente che mai”, afferma Song. “Sta ridefinendo il modo in cui viviamo, lavoriamo e cresce l’economia”. Secondo il manager, l’Europa si trova davanti a una delle più grandi opportunità industriali del prossimo decennio.

Il principio attorno al quale ruota l’intervento è che “non esiste AI senza dati”. Huawei sostiene che la crescita dei workload AI renda sempre più strategica la qualità dell’infrastruttura dati, collegando direttamente sviluppo dell’intelligenza artificiale, capacità storage e sovranità tecnologica europea.
Song richiama l’AI Continent Action Plan lanciato dalla Commissione europea nel 2025, ricordando che il continente dispone già di 19 AI Factory operative e che Bruxelles sta promuovendo la realizzazione di una nuova generazione di AI Gigafactory destinate a rafforzare la capacità europea di addestramento e inferenza su larga scala, insieme a investimenti per la creazione di dataset ad alta qualità. Secondo Huawei, proprio il dato rappresenta il vero fattore abilitante dell’adozione dell’AI su scala industriale.
È in questo contesto che il gruppo punta a rafforzare il proprio ruolo nell’ecosistema infrastrutturale europeo. Song ricorda la presenza di 29 centri di ricerca e sviluppo nel continente e afferma l’intenzione di “guidare questa trasformazione insieme ai clienti e ai partner europei”.
L’adozione dell’AI viene indicata come un fattore destinato ad accelerare ulteriormente la transizione verso architetture storage all-flash. Secondo Song, throughput elevato, bassa latenza e inferenza continua richiederanno piattaforme basate sempre più su SSD avanzati. “Porteremo avanti la nostra strategia all-flash e aggiorneremo i dataset con tecnologie SSD avanzate”, afferma.
Anche l’efficienza energetica entra tra i requisiti delle future infrastrutture AI. La crescita della capacità computazionale renderà indispensabili architetture storage ad alta densità e basso consumo. Song cita OceanStor Pacific come piattaforma progettata per rispondere a queste esigenze e richiama il caso di una grande istituzione educativa europea nella quale, secondo l’azienda, la soluzione avrebbe consentito una riduzione del 20% dei consumi energetici.
L’efficienza delle future infrastrutture AI dipenderà anche dalla capacità di contenere la crescita fisica dello storage. Questo obiettivo viene collegato ad algoritmi avanzati di data reduction e alle funzionalità integrate in OceanProtect, che secondo l’azienda permettono di archiviare fino al 40% di dati in più a parità di spazio occupato.
La strategia “In Europe, For Europe” lega questa visione alla costruzione delle future infrastrutture per l’intelligenza artificiale nel continente. Secondo Song, la competizione AI si giocherà sempre più sulla capacità di realizzare piattaforme dati resilienti, sostenibili e ad alte prestazioni. L’Europa viene così descritta come uno dei poli destinati a svolgere un ruolo centrale nell’evoluzione delle infrastrutture intelligenti.
L’agentic AI apre il quarto grande ciclo dell’IT
Il tema non riguarda soltanto le infrastrutture dati. Secondo IDC, l’intelligenza artificiale generativa e agentica sta producendo una trasformazione più ampia, destinata a modificare architetture IT, applicazioni e modelli operativi delle imprese. Andrew Buss, Senior Research Director dell’analista americano, definisce l’attuale fase come il “quarto ciclo tecnologico moderno”, sostenuto da investimenti infrastrutturali, nuove architetture applicative e modelli operativi destinati a trasformare il ruolo stesso dell’IT nelle imprese.
Per Buss non si tratta di una normale evoluzione incrementale. Le aziende stanno passando da un’informatica algoritmica, precisa e deterministica a un modello più interpretativo, generativo e basato sul linguaggio naturale. “Siamo nel mezzo di un enorme cambiamento dell’IT, come non ne abbiamo mai visti prima”, afferma.
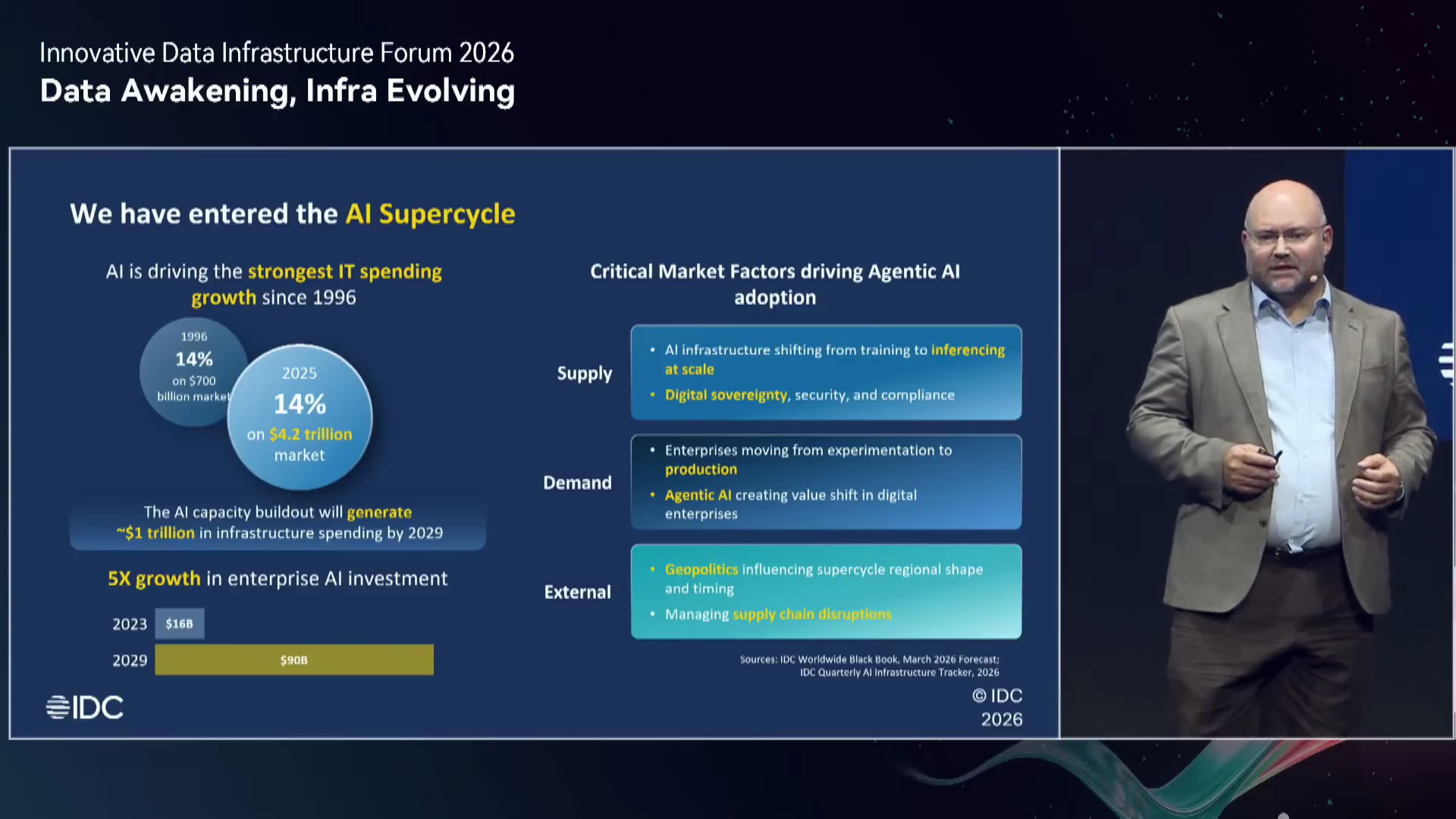
IDC sostiene che l’AI stia uscendo dal back office per entrare progressivamente nella customer experience, nella produttività del personale, nella supply chain, nei modelli di go-to-market e nei processi decisionali. Gli investimenti enterprise in AI, secondo IDC, cresceranno di cinque volte tra il 2023 e il 2029 fino a sfiorare i 100 miliardi di dollari. Il mercato si sta quindi spostando dalla sperimentazione iniziale alla produzione su larga scala, dall’addestramento dei modelli alla creazione di valore operativo.
Il vantaggio competitivo sarà particolarmente forte per le aziende che hanno già costruito una base digitale avanzata. IDC identifica questo gruppo nei cosiddetti “digital leader”: organizzazioni caratterizzate da forte automazione, sviluppo cloud-native, AIOps, uso esteso del multicloud e infrastrutture già orientate alla scalabilità. Queste aziende crescono più rapidamente, spesso oltre il 10%, e attribuiscono alla GenAI un ruolo critico nella strategia di business.
La distinzione tra AI generativa tradizionale e agentic AI segna uno dei principali elementi di discontinuità dell’attuale evoluzione tecnologica. La prima generazione di AI generativa è prompt-based: l’utente formula una richiesta, riceve una risposta e decide autonomamente come utilizzarla. L’agentic AI introduce invece il modello “reasoning and action”, cioè sistemi capaci non soltanto di generare output ma anche di interpretare contesto, prendere decisioni ed eseguire azioni operative.
Secondo Buss, questa evoluzione cambia radicalmente il perimetro dell’automazione. Gli agenti AI possono coordinarsi tra loro, avviare task, operare su processi complessi e mantenere memoria nel tempo. “Ciò che rende diversa l’AI agentica è la capacità di avere memoria, mantenere il contesto e agire su una lunga serie di eventi e catene di ragionamento”, osserva.
IDC individua casi applicativi già concreti in customer service, AIOps, finanza, risorse umane, retail, manufacturing e healthcare. Buss cita in particolare un produttore di scanner medicali che ha integrato capacità LLM direttamente nei sistemi di imaging, consentendo una prima analisi immediata senza attendere la revisione di specialisti e accelerando così diagnosi e trattamento dei pazienti.
Questa evoluzione impone però un ripensamento completo dell’architettura IT. I sistemi agentici devono gestire multitask execution, eccezioni, ambiguità operative e interazioni continue tra agenti, utenti e piattaforme aziendali. Secondo Buss, le imprese dovranno quindi rafforzare osservabilità, governance e meccanismi di supervisione umana, soprattutto nei processi regolamentati o ad alto impatto.
La sicurezza rappresenta un altro punto critico. “Senza fiducia e integrità nei dati e nei sistemi, non possiamo avere modelli di business digitali e servizi digitali”, afferma Buss. IDC osserva una forte crescita della domanda di private AI infrastructure in Europa e nell’area EMEA, soprattutto per proteggere proprietà intellettuale, dati sensibili e compliance normativa.

Il limite principale resta però la qualità del dato. Secondo le previsioni IDC FutureScape 2026, la mancanza di dati realmente AI-ready potrebbe causare una perdita di produttività del 15%. IDC invita quindi le imprese a concentrarsi su governance, integrazione, sicurezza e qualità dei dataset prima ancora di accelerare sul deployment degli agenti AI.
Per ridurre complessità e rischio, IDC vede un vantaggio nei vendor capaci di offrire piattaforme full stack che integrino silicio, server, storage, networking, piattaforme AI e servizi professionali dentro una logica di “AI factory”, progettata per sostenere implementazioni scalabili dal piccolo ambiente fino alla grande infrastruttura enterprise.
Secondo Buss, l’agentic AI non rappresenta quindi soltanto una nuova generazione software, ma una trasformazione sistemica destinata a ridefinire processi, modelli operativi e infrastrutture digitali delle imprese.
L’AI entra nell’era della memoria persistente e dell’inferenza continua
L’intelligenza artificiale sta entrando in una fase nella quale il vero elemento competitivo non sarà più soltanto la disponibilità di GPU o la qualità dei foundation model, ma la capacità di costruire infrastrutture dati capaci di sostenere inferenza continua, memoria persistente e collaborazione tra agenti intelligenti. , Vice President di Huawei e President della Data Storage Product Line, descrive questa trasformazione come il passaggio definitivo da un paradigma compute-centric a uno data-centric: “Il prossimo capitolo dell’AI saranno i dati”. La crescita degli agenti AI sta modificando radicalmente il rapporto tra sistemi informativi e infrastruttura. Citando dati IDC, Yuan Yuan sostiene che siano già operativi oltre 30 milioni di agenti intelligenti e che il numero possa raggiungere i 2,2 miliardi entro pochi anni. Ma il cambiamento più importante non è quantitativo: gli agenti stanno evolvendo da semplici interfacce conversazionali a componenti operative persistenti capaci di collaborare tra loro, richiamare memoria contestuale ed eseguire task complessi. “Gli agenti stanno diventando dipendenti digitali”, osserva Yuan Yuan.
Il dato smette così di essere un asset statico da archiviare e proteggere e diventa un fattore produttivo continuamente consumato, arricchito e rigenerato dagli stessi sistemi intelligenti. È questo il significato del concetto di “data awakening”, attraverso cui Huawei descrive il passaggio dei dati da risorsa passiva a elemento cognitivo vivo dell’infrastruttura AI.
Yuan Yuan richiama dati relativi ai workload OpenAI secondo cui il volume elaborato sarebbe passato da circa 6 miliardi di token al minuto nel 2025 a 15 miliardi nel 2026. “I token stanno diventando come aria e acqua”, afferma. “Indispensabili per la nostra vita digitale”.
Il problema infrastrutturale non è più soltanto addestrare modelli sempre più grandi, ma sostenere una quantità crescente di inferenza continua. Gli agenti mantengono contesto, memoria e stato operativo persistente: ogni interazione richiede retrieval continuo, accesso alle informazioni contestuali e orchestrazione di dataset distribuiti. L’inferenza smette quindi di essere episodica e diventa permanente.
Le architetture storage tradizionali non erano state progettate per questo tipo di workload. Database enterprise, NAS convenzionali e cloud legacy erano ottimizzati per workload transazionali e applicazioni business classiche, mentre gli ambienti agentici richiedono throughput elevatissimo, retrieval semantico in millisecondi, gestione di contesti lunghi e inferenza ad alta concorrenza.
Il problema cresce ulteriormente con l’AI multimodale. I sistemi AI elaborano contemporaneamente testo, immagini, video, audio, dati industriali e flussi IoT, trasformando il data lake in un componente strategico dell’architettura enterprise. Per questo Huawei introduce il concetto di AI-native data infrastructure, una piattaforma progettata specificamente per workload agentici e multimodali e pensata per trasformare il data center in una vera “AI factory”.
La AI Data Platform proposta dal gruppo integra knowledge layer, retrieval layer, persistent memory layer, inferencing layer e security layer dentro un’unica architettura, inserita in una piattaforma costruita attorno a sei componenti fondamentali: data lake, AI data platform, capacità computazionale, modelli, framework agentici e resilienza del dato. Nel layer data lake il ruolo centrale è affidato a OceanStor Pacific, piattaforma scale-out ad alta densità che può raggiungere 11 PB in 2U, affiancata da DME Omni-Dataverse, uno spazio dati unificato progettato per aggregare dati multimodali distribuiti tra siti differenti e renderli disponibili in tempo reale attraverso meccanismi di retrieval semantico capaci di operare su centinaia di miliardi di vettori. La piattaforma viene inoltre presentata come una AI Data Platform “3+1”, nella quale accelerazione della KV cache, knowledge base semantiche e memory bank persistenti sono coordinate da un livello unificato di orchestrazione. Secondo Huawei, le capacità di retrieval raggiungono livelli di accuratezza superiori al 95%, mentre l’Unified Cache Manager consente una gestione integrata di cache, memoria e contesto operativo che può migliorare fino al 30% la qualità inferenziale, coordinando la distribuzione del contesto tra memoria, cache e sistemi di retrieval. In questo contesto OceanStor Dorado viene posizionato per workload AI ad alte prestazioni e inferenza a bassa latenza, OceanProtect per resilienza e protezione ransomware, mentre gli acceleratori Ascend e gli strumenti proprietari di orchestrazione completano la piattaforma.

La knowledge base rappresenta il patrimonio documentale e informativo dell’organizzazione e deve diventare semanticamente consapevole, capace di comprendere relazioni e contesto. Un ruolo altrettanto importante è attribuito alla gestione del contesto inferenziale: senza meccanismi efficienti di condivisione e riutilizzo delle informazioni già elaborate, i modelli sarebbero costretti a ricalcolare continuamente lo stesso patrimonio informativo, aumentando latenza, consumo energetico e carico computazionale.
La persistent memory viene indicata come una delle differenze fondamentali tra chatbot tradizionali e agenti intelligenti persistenti. “Gli esseri umani diventano più intelligenti perché hanno memoria”, afferma Yuan Yuan. Gli agenti devono quindi poter accumulare esperienza nel tempo, ricordare debugging precedenti, adattarsi ai workflow e mantenere continuità cognitiva. Per supportare questo modello Huawei introduce il concetto di Context Memory Storage (CMS), una piattaforma per la gestione di cache KV distribuite in scala petabyte su infrastrutture Nvidia, AMD e Ascend che, secondo l’azienda, consente di ridurre fino al 90% il time-to-first-token e migliorare la reattività degli ambienti di inferenza su larga scala.
Il futuro dell’AI dipenderà così dalla convergenza tra storage e memory layer. Le piattaforme dovranno orchestrare dinamicamente HBM, DRAM, SSD all-flash e cold storage in funzione del contesto operativo e dei workload AI. OceanStor Dorado viene posizionato come piattaforma chiave per workload AI mission critical e inferenza a bassa latenza, mentre OceanStor Pacific opera come foundation layer per data lake AI-native e training multimodale hyperscale.
Yuan Yuan collega direttamente questa architettura anche al problema energetico dell’AI, sostenendo che l’inferenza continua rischi di diventare economicamente insostenibile senza una gestione intelligente della memoria e del dato.
Tra gli esempi portati dal manager figura un grande ospedale cinese che ha implementato una piattaforma AI per la patologia digitale basata su sette agenti AI e tre modelli differenti. Il sistema utilizza oltre 300 libri medici come knowledge base e più di un milione di vetrini patologici digitalizzati elaborati attraverso 16 GPU e storage all-flash. Il tempo necessario per generare un referto patologico sarebbe stato ridotto da 40 minuti a 15 secondi con capacità di identificazione accurata di oltre 19 tipologie di tumore.
La stessa logica viene applicata alla guida autonoma. Yuan Yuan descrive il caso di un produttore automotive impegnato nello sviluppo di sistemi Level 5 costretto a gestire oltre 100 petabyte di dati provenienti da radar, sensori, traffico, meteo e ambiente stradale. Il problema non è soltanto archiviare questi dati ma riuscire a recuperare rapidamente edge case rarissimi – come “un cane che attraversa la strada sotto la pioggia con il semaforo rosso” – all’interno di centinaia di miliardi di file.
Questo tipo di retrieval deve avvenire in pochi millisecondi attraverso motori semantici distribuiti e piattaforme context-aware. È qui che OceanStor Pacific viene posizionato come piattaforma hyperscale per retrieval semantico e data lake AI-native.
La frammentazione dei dati enterprise viene indicata come uno dei principali ostacoli all’AI agentica. Le aziende possiedono enormi quantità di informazioni distribuite tra ERP, CRM, database legacy, cloud e file system differenti, mentre gli agenti richiedono una visione unificata del patrimonio informativo. La risposta proposta è un data fabric AI-native capace di orchestrare dati cross-domain e costruire una governance distribuita dell’informazione.
La sicurezza rappresenta un altro elemento centrale. L’AI enterprise viene descritta come un ambiente ad alta criticità esposto a poisoning dei dataset, ransomware e manipolazione dei modelli. OceanProtect viene quindi posizionato come piattaforma per la resilienza AI-ready, con sistemi anti-poisoning, tecnologie anti-tampering e meccanismi di protezione ransomware.
Backup e disaster recovery tradizionali non sono più sufficienti per ambienti agentici persistenti. Le future piattaforme dovranno proteggere non soltanto dati statici ma anche memoria contestuale, knowledge graph e stato operativo degli agenti AI.
La prospettiva delineata da Yuan Yuan converge così verso un’infrastruttura AI full-stack che integra acceleratori, deployment dei modelli, persistent memory, retrieval semantico, hyperscale storage, data fabric distribuito e sicurezza integrata.

Sul piano operativo Huawei affianca all’infrastruttura dati anche strumenti dedicati alla gestione dei modelli e degli agenti AI. ModelEngine viene presentato come una piattaforma che integra funzionalità di model gateway, adattamento zero-code a nuovi modelli e deployment automatizzato, supportando inoltre una gestione granulare delle risorse computazionali con rapporti di partizionamento xPU fino a 1:10. Accanto a questa componente, la piattaforma Nexent è progettata per consentire la creazione di agenti attraverso interazioni in linguaggio naturale anziché mediante sviluppo tradizionale. Secondo Huawei, l’automazione di skill, prompt e memoria può ridurre fino all’80% i tempi di rollout e permettere agli agenti di evolvere progressivamente nel tempo.
La competizione AI dei prossimi anni, conclude il manager, sarà determinata dalla capacità di costruire sistemi cognitivi persistenti alimentati da infrastrutture dati intelligenti, resilienti e progettate per sostenere inferenza continua su scala industriale.
La resilienza diventa capacità di sopravvivenza operativa del dato
La resilienza non coincide più con l’alta disponibilità. Benoit Fix, CTO di Huawei France Data Center Solutions, sostiene che la distinzione sia ormai decisiva perché le infrastrutture enterprise non operano più all’interno di perimetri semplici, con un’applicazione, un data center e un insieme di dati chiaramente isolato. I sistemi moderni sono distribuiti tra più siti, città, Paesi e regioni, con applicazioni, dati, microservizi e piattaforme che cooperano continuamente. In questo scenario non basta più garantire la disponibilità di un singolo componente: bisogna assicurare che l’organizzazione possa continuare a operare, recuperare servizi e preservare l’integrità del dato anche durante guasti o compromissioni. “Non lavoriamo più davvero con data center isolati”, osserva Fix. “Siamo in un modello di servizi cross-region”.
L’AI, il cloud ibrido, la containerizzazione e la crescita dei rischi cyber stanno cambiando profondamente il problema infrastrutturale. Le imprese continuano a utilizzare virtual machine e ambienti legacy, ma li affiancano a container, microservizi e piattaforme cloud-native. Questa convivenza aumenta l’agilità ma introduce nuovi failure domain: un errore in un singolo componente può propagarsi rapidamente lungo servizi distribuiti. Fix richiama il caso Cloudflare come esempio di quanto un problema localizzato possa produrre effetti sistemici su piattaforme apparentemente separate.
Anche la supply chain software diventa una nuova superficie di rischio. L’uso massiccio di componenti open source moltiplica le dipendenze tra librerie, framework e moduli sviluppati in momenti diversi e da soggetti differenti. Una vulnerabilità ereditata lungo questa catena può entrare nei workload enterprise senza essere immediatamente identificata.
In questo contesto la recoverability diventa centrale. La domanda non è più soltanto se il sistema sia disponibile, ma se l’azienda sia realmente in grado di ripristinare dati, applicazioni e servizi dopo un guasto o un attacco. Per Fix la resilienza deve essere verificabile attraverso test reali di disaster recovery e capacità concrete di ricostruzione operativa.
L’AI modifica anche il dimensionamento dei data center. I workload generativi e agentici introducono livelli di imprevedibilità che rendono meno efficace una gestione tradizionale basata su QoS e carichi medi. Le piattaforme mission critical devono quindi mantenere performance stabili anche in presenza di failure di controller, dischi, enclosure o interi siti.
Nel layer mission critical Huawei posiziona la nuova generazione di OceanStor Dorado come piattaforma all-flash progettata per garantire alte prestazioni stabili e continuità operativa sotto stress. L’obiettivo non è soltanto accelerare lo storage ma assicurare bassa latenza, accessi concorrenti e qualità del servizio prevedibile anche durante manutenzioni o incidenti.

Per gli ambienti scale-out e i grandi volumi di dati, la strategia ruota invece attorno a OceanStor Pacific. Fix richiama la crescita esplosiva della capacità richiesta dalle imprese: organizzazioni che dieci anni fa gestivano decine di terabyte oggi richiedono piattaforme da più petabyte. OceanStor Pacific viene quindi posizionato come piattaforma ad alta densità progettata per ridurre footprint e failure radius, limitando l’impatto dei guasti e accelerando la ricostruzione dei dati.
Uno dei passaggi tecnicamente più rilevanti riguarda le architetture multi-site. Huawei propone configurazioni active-active fino a tre siti e active-passive fino a dodici siti, superando il tradizionale disaster recovery a due data center. La logica è quella di una resilienza geografica nativa nella quale dati e servizi restano coerenti e disponibili anche durante indisponibilità di interi siti. Il riferimento alle configurazioni IP Metro active-active evidenzia la necessità di collegare ambienti storage e data center distribuiti mantenendo continuità operativa cross-site.
Il backup viene descritto come l’ultima linea di difesa, ma il suo significato cambia radicalmente. Non basta più copiare i dati: bisogna recuperarli rapidamente, verificarne l’integrità e proteggerli da ransomware e compromissioni logiche. È qui che Huawei colloca OceanProtect, piattaforma progettata per backup full-flash, retention estesa, instant recovery e protezione cyber.
Fix insiste molto sul ruolo della velocità di recovery. In scenari AI e data-driven, la capacità di ricostruire rapidamente un data center o ripristinare grandi volumi di dati diventa fondamentale. Per questo Huawei sta lavorando anche su tecnologie disco ibride che combinano caratteristiche SLC e QLC, insieme a nuove logiche di deduplica e compressione ottimizzate in funzione del workload.
La protezione ransomware rappresenta il punto in cui resilienza e alta disponibilità si separano più nettamente. L’AI può essere utilizzata anche dagli attaccanti per analizzare vulnerabilità, generare codice malevolo e costruire attacchi più sofisticati. La risposta proposta da Huawei è una catena multilivello che combina backup rapido, replica isolata, analisi anti-tampering e golden copy.
Huawei estende inoltre il concetto di resilienza all’intera catena dell’intelligenza artificiale. Oltre alla protezione contro ransomware e compromissioni delle infrastrutture storage, la strategia comprende contromisure contro data poisoning, manipolazione dei modelli e alterazione delle knowledge base, con l’obiettivo di preservare l’affidabilità degli agenti AI, dei sistemi inferenziali e dei dati che ne alimentano il funzionamento.
Le appliance OceanProtect analizzano i dati per individuare segnali di cifratura anomala o compromissione. Le copie vengono quindi replicate in clean room isolate attraverso meccanismi di air gap e sottoposte a verifica. Solo una copia validata può diventare golden copy, cioè l’ultima versione considerata sicuramente recuperabile e non contaminata. Questo approccio assume particolare importanza negli ambienti AI. Se ransomware o compromissioni logiche colpiscono dataset, modelli, knowledge base o pipeline inferenziali, una replica non verificata rischia infatti di propagare il problema. La resilienza richiede quindi recovery “known clean”, cioè ripristino da copie la cui integrità sia stata verificata.
Fix collega la resilienza anche alla trasformazione del mercato hypervisor. Molte aziende stanno rivalutando le proprie piattaforme di virtualizzazione e cercano modelli di dual sourcing o alternative agli ambienti consolidati. Huawei posiziona le proprie soluzioni di virtualizzazione come strumenti capaci di mantenere continuità applicativa, recovery coerente e resilienza operativa durante queste transizioni.
Anche l’operation cambia profondamente. La gestione tradizionale del data center dipende dall’esperienza degli amministratori e da strumenti di troubleshooting spesso reattivi. Huawei propone invece un modello più data-driven e agentico basato su eSight/DME e Data Master, progettato per trasformare la gestione dell’infrastruttura da reattiva a proattiva.
Fix descrive il modello “0-1-3-5”: rilevazione proattiva delle anomalie, identificazione del problema entro un minuto, individuazione dell’area coinvolta – rete, VM o storage – entro tre minuti e root cause analysis entro cinque minuti. Data Master viene presentato come un agente integrato capace di analizzare rischi di capacità, performance e stabilità prima che si trasformino in incidenti reali.
La sintesi della proposta Huawei mette quindi insieme più livelli: OceanStor Dorado per workload mission critical, OceanStor Pacific per storage massivo hyperscale, OceanProtect per backup e resilienza cyber, piattaforme di virtualizzazione per continuità operativa e DME/Data Master per AIOps e gestione predittiva.
“La resilienza è ormai più importante dell’alta disponibilità”, conclude Fix. Non perché l’availability abbia perso valore, ma perché nell’era dell’AI non basta più mantenere acceso un sistema: bisogna poter proteggere il dato, verificarne l’integrità, mantenere performance stabili, prevenire incidenti e ricostruire rapidamente servizi distribuiti anche in presenza di failure o attacchi sistemici.
Lo storage AI-native diventa un sistema distribuito di alimentazione dell’inferenza
L’intelligenza artificiale sta trasformando radicalmente il ruolo dello storage nei data center moderni. Secondo David Slik, Chief Scientist of Data Storage presso Huawei Fields Research Center, le architetture costruite negli ultimi vent’anni attorno a capacità, persistenza e throughput general purpose non sono più sufficienti per sostenere foundation model, inferenza distribuita e workload agentici.
“Le GPU sono incredibilmente veloci”, osserva Slik. “Ma diventano inutili se non riesci ad alimentarle con dati alla velocità necessaria”.
Il problema centrale non è più conservare i dati, ma riuscire a portarli abbastanza rapidamente verso GPU e cluster computazionali senza creare colli di bottiglia sistemici. Huawei interpreta così la trasformazione AI soprattutto come un problema di data movement infrastructure. Nei cluster AI moderni il rischio principale è la GPU starvation: acceleratori molto costosi restano parzialmente inattivi perché rete, storage o metadata layer non riescono a sostenere il throughput richiesto da training e inferenza.
Questo cambia profondamente il modo in cui devono essere progettati i sistemi storage enterprise. Database transazionali, analytics batch, virtualizzazione e file serving generavano pattern relativamente prevedibili; i workload AI producono invece accessi paralleli massivi, throughput burst-oriented e continui cicli di lettura dei dataset. “L’AI non aumenta soltanto il volume dei dati”, spiega Slik. “Aumenta soprattutto l’intensità di accesso ai dati”.
La pressione cresce ulteriormente con i foundation model multimodali. Testo, immagini, audio, video, metadata e dati sintetici devono essere elaborati simultaneamente, moltiplicando il traffico east-west, ossia gli scambi di dati interni tra server, applicazioni e sistemi storage, oltre alle richieste concorrenti e alla pressione sui namespace storage.
Uno dei problemi più sottovalutati riguarda i metadati. I workload AI non elaborano soltanto grandi file sequenziali, ma generano enormi quantità di piccoli oggetti, embedding, indici vettoriali, checkpoint, metadati contestuali e strutture distribuite indispensabili per retrieval e inferenza. La criticità non risiede quindi soltanto nella velocità di trasferimento dei dati, ma nella capacità dell’infrastruttura di gestire miliardi di operazioni sul namespace, enormi quantità di piccoli file e livelli sempre più elevati di accesso concorrente.
Slik considera particolarmente critica la crescita dei vector database e delle pipeline RAG – Retrieval-Augmented Generation. Gli agenti AI non lavorano su dataset statici, ma interrogano continuamente vector store, retrieval cache e knowledge base distribuite. Questo cambia anche il concetto di persistenza: non bisogna più proteggere soltanto dataset e backup tradizionali, ma anche embedding, memoria contestuale, KV cache, retrieval index e stato operativo distribuito degli agenti.
Anche il checkpointing – il salvataggio periodico degli stati intermedi dei modelli per consentire il ripristino delle elaborazioni in caso di interruzioni – diventa una componente critica delle infrastrutture AI. Questa attività genera flussi intensivi di I/O e richiede piattaforme storage capaci di sostenere elevati volumi di scrittura senza penalizzare le prestazioni. “Il problema non è più archiviare petabyte”, osserva Slik. “Il problema è riuscire a muoverli abbastanza rapidamente da non rallentare il sistema computazionale”.
Se il throughput non è sufficiente, i cluster GPU restano in attesa durante il salvataggio dello stato del modello, peggiorando drasticamente l’utilizzo effettivo dell’infrastruttura AI. Anche la resilienza assume quindi un significato differente: training distribuiti di grandi foundation model non possono permettersi recovery lenti o interruzioni prolungate.
Per questo Huawei sta lavorando su architetture storage AI-native progettate per sostenere contemporaneamente throughput elevato, checkpoint frequenti e recovery rapido. OceanStor Dorado all-flash viene posizionato come layer ad altissime prestazioni per training, inferenza e workload mission critical ad alta concurrency, mentre OceanStor Pacific opera come piattaforma scale-out per AI data lake e repository distribuiti di grandi dimensioni.

Secondo Slik, però, il punto non è costruire un singolo tier storage universale, ma una gerarchia dinamica nella quale i dati possano muoversi automaticamente tra differenti layer in funzione del comportamento reale dei workload. Compute, networking e storage devono operare come un unico sistema distribuito dentro un AI data fabric convergente.
La separazione tradizionale tra file storage, object storage e data lake tende progressivamente a scomparire. I workload AI richiedono accesso simultaneo multi-protocol a dataset differenti, object repository, parallel file system e ambienti distribuiti. Per questo Huawei spinge sulla convergenza object-file e sul ruolo di OceanFS come global namespace distribuito per ambienti AI.
Il global namespace diventa fondamentale perché i workload AI non possono dipendere da silos storage separati. Dataset e repository devono poter essere raggiunti coerentemente da cluster differenti, pipeline diverse e workload distribuiti senza continui spostamenti fisici dei dati.
La proliferazione delle copie dei dataset viene indicata come uno dei principali rischi economici dell’AI enterprise. Ogni pipeline AI tende a generare nuove copie dei dati, nuove varianti e nuovi layer di elaborazione. La crescita dei dati sintetici amplifica ulteriormente il fenomeno: i sistemi generativi non consumano soltanto dati, ma producono continuamente nuovi contenuti che devono essere archiviati, indicizzati, versionati e resi disponibili per ulteriori workflow AI.
Molte organizzazioni, osserva Slik, sottovalutano l’impatto economico del data movement. Spostare continuamente petabyte di dati tra cluster, cloud e ambienti differenti aumenta consumi energetici, pressione sulla rete e costi operativi. Per questo il tema della data locality diventa centrale: inferenza, training e retrieval devono essere collocati il più vicino possibile ai repository dati. “L’efficienza dell’AI dipenderà sempre di più dalla capacità di avvicinare il dato alla computazione”, afferma.
Questo problema è strettamente collegato alla crescita del networking east-west nei data center AI. Training distribuiti e workload multimodali generano traffico interno molto più elevato rispetto ai workload enterprise tradizionali.
Huawei considera tecnologie come RDMA (Remote Direct Memory Access), che consentono lo scambio diretto di dati tra memoria e sistemi remoti con latenza minima, e interconnessioni ad altissimo throughput come componenti fondamentali delle infrastrutture AI-ready. Il problema non riguarda più soltanto la velocità dello storage locale, ma la capacità dell’intero fabric di sostenere movimenti continui di dati tra GPU, memoria e layer storage distribuiti.
La pressione energetica rappresenta un’altra area critica. Cluster AI sempre più densi stanno modificando il rapporto tra potenza computazionale, alimentazione elettrica e raffreddamento.
Molti data center, osserva Slik, stanno raggiungendo i propri limiti non tanto in termini di spazio fisico, quanto di power delivery e cooling capacity. La capacità di alimentare e raffreddare infrastrutture AI sempre più dense sta infatti diventando un vincolo critico. Migliorare l’efficienza del data movement diventa quindi anche un problema energetico.
Huawei collega direttamente sostenibilità ed efficienza storage. Copie inutili dei dati e movimentazioni eccessive aumentano traffico, consumi e pressione infrastrutturale. Per questo il gruppo punta verso modelli sempre più automatizzati di AI-driven storage management capaci di analizzare pattern di utilizzo, prevedere saturazioni, ottimizzare placement dei dati e bilanciare dinamicamente i workload storage.
“Lo storage sta diventando un sistema intelligente”, osserva Slik. “Non può più essere soltanto un repository passivo”.
L’obiettivo è ridurre operation manuali e costruire piattaforme storage autonome capaci di governare automaticamente performance, resilienza, capacity planning e distribuzione dei dati. Anche il concetto di resilienza cambia: nei sistemi AI distribuiti non basta più proteggere dati statici o backup periodici, ma bisogna garantire continuità di accesso a vector database, retrieval layer, knowledge graph, cache distribuite e memoria persistente degli agenti.
Per questo Huawei sta lavorando su architetture active-active distribuite e meccanismi di predictive balancing progettati per evitare saturazioni improvvise e failure sistemici. OceanStor Pacific viene posizionato come piattaforma scale-out capace di aumentare simultaneamente capacità e throughput aggiungendo nodi senza ricostruire l’infrastruttura.
Training dataset, retrieval cache, metadata, dati sintetici e inferenza multimodale stanno producendo una crescita esplosiva sia della capacità sia del throughput richiesto. In questo scenario, conclude Slik, lo storage smette di essere un semplice repository persistente e diventa una componente cognitiva distribuita dell’infrastruttura AI. “Il valore dello storage non dipenderà più dalla quantità di dati archiviati, ma dalla capacità di alimentare continuamente l’intelligenza artificiale senza creare colli di bottiglia”.






{kind=link}